
Chapter 20. Clustering Concepts
In the next section, we discuss basic concepts behind JBoss' clustering services. It is helpful that you understand these concepts before reading the rest of the Clustering Guide.
20.1. Cluster Definition
A cluster is a set of nodes that communicate with each other and work toward a common goal. In a JBoss Enterprise Application Platform cluster (also known as a “partition”), a node is an JBoss Enterprise Application Platform instance. Communication between the nodes is handled by the JGroups group communication library, with a JGroups
Channel providing the core functionality of tracking who is in the cluster and reliably exchanging messages between the cluster members. JGroups channels with the same configuration and name have the ability to dynamically discover each other and form a group. This is why simply executing “run -c production” on two Enterprise Application Platform instances on the same network is enough for them to form a cluster – each Enterprise Application Platform starts a Channel (actually, several) with the same default configuration, so they dynamically discover each other and form a cluster. Nodes can be dynamically added to or removed from clusters at any time, simply by starting or stopping a Channel with a configuration and name that matches the other cluster members.
On the same Enterprise Application Platform instance, different services can create their own
Channel. In a standard start of the Enterprise Application Platform 5 production server profile, two different services create a total of four different channels – JBoss Messaging creates two and a core general purpose clustering service known as HAPartition creates two more. If you deploy clustered web applications, clustered EJB3 SFSBs or a clustered JPA/Hibernate entity cache, additional channels will be created. The channels the Enterprise Application Platform connects can be divided into three broad categories: a general purpose channel used by the HAPartition service, channels created by JBoss Cache for special purpose caching and cluster wide state replication, and two channels used by JBoss Messaging.
So, if you go to two Enterprise Application Platform 5.0.x instances and execute
run -c production, the channels will discover each other and you'll have a conceptual cluster. It's easy to think of this as a two node cluster, but it's important to understand that you really have multiple channels, and hence multiple two node clusters.
On the same network, you may have different sets of servers whose services wish to cluster. Figure 20.1, “Clusters and server nodes” shows an example network of EAP instances divided into three sets, with the third set only having one node. This sort of topology can be set up simply by configuring the Enterprise Application Platform instances such that within a set of nodes meant to form a cluster the Channel configurations and names match while they differ from any other channel configurations and names match while they differ from any other channels on the same network. The Enterprise Application Platform tries to make this is easy as possible, such that servers that are meant to cluster only need to have the same values passed on the command line to the
-g (partition name) and -u (multicast address) start up switches. For each set of servers, different values should be chosen. The sections on “JGroups Configuration” and “Isolating JGroups Channels” cover in detail how to configure the Enterprise Application Platform such that desired peers find each other and unwanted peers do not.
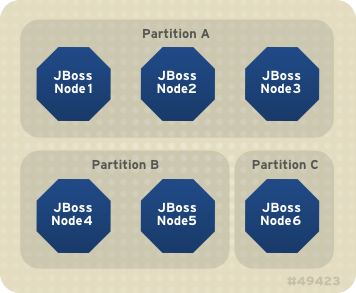
Figure 20.1. Clusters and server nodes