
Performance Tuning Guide
for use with JBoss Enterprise Application Platform 5.2.x
Edition 5.2.0
Abstract
Preface
1. File Name Conventions
- JBOSS_EAP_DIST
- The installation root of the JBoss Enterprise Application Platform instance. This folder contains the main folders that comprise the server such as
/jboss-as,/seam, and/resteasy. - PROFILE
- The name of the server profile you use as part of your testing or production configuration. The server profiles reside in
JBOSS_EAP_DIST/jboss-as/server.
Chapter 1. Introduction
1.1. Platform Components

Figure 1.1. JBoss Enterprise Application Platform architecture
- Connection pooling
- Thread pooling
- Object and/or component pooling
- I/O configuration
- Logging and JMS provider
- Replication options
- Caching
Chapter 2. Connectors
2.1. Java I/O Connector
- maxKeepAliveRequests
- maxThreads
- minSpareThreads
server.xml file for the JBoss Web embedded servlet container: JBOSS_EAP_DIST/jboss-as/server/PROFILE/deploy/jbossweb.sar. Near the top of this file is the Connector section, where these parameters are configured. Note that the minimal configuration does not include JBoss Web.
<!-- A HTTP/1.1 Connector on port 8080 -->
<Connector protocol="HTTP/1.1" port="8080" address="${jboss.bind.address}"
connectionTimeout="20000" redirectPort="8443" />
2.1.1. maxKeepAliveRequests
maxKeepAliveRequests parameter specifies how many pipe-lined requests a user agent can send over a persistent HTTP connection (which is the default in HTTP 1.1) before it will close the connection. A persistent connection is one which the client expects to remain open once established, instead of closing and reestablishing the connection with each request. Typically the client (a browser, for example) will send an HTTP header called a “Connection” with a token called "keep-alive" to specify a persistent connection. This was one of the major improvements of the HTTP protocol in version 1.1 over 1.0 because it improves scalability of the server considerably, especially as the number of clients increases. To close the connection, the client or the server can include the “Connection” attribute in its header, with a token called “close”. This signals either side that after the request is completed, the connection is to be closed. The client, or user agent, can even specify the “close” token on its “Connection” header with its initial request, specifying that it does not want to use a persistent connection.
Connection: keep-alive content in the header, followed by an HTTP POST, again with Connection: keep-alive specified. This is the 100th client request so in the response to the HTTP POST is the instruction Connection: close.
POST /Order/NewOrder HTTP/1.1 Connection: keep-alive Cookie: $Version=0; JSESSIONID=VzNmllbAmPDMInSJQ152bw__; $Path=/Order Content-Type: application/x-www-form-urlencoded Content-Length: 262 User-Agent: Jakarta Commons-HttpClient/3.1 Host: 192.168.1.22:8080 customerid=86570&productid=1570&quantity=6&productid=6570&quantity=19&productid=11570&quantity=29&productid=16570&quantity=39&productid=21570&quantity=49&productid=26570&quantity=59&productid=&quantity=&productid=&quantity=&productid=&quantity=&NewOrder=NewOrderGET /Order/OrderInquiry?customerId=86570 HTTP/1.1 Connection: keep-alive Cookie: $Version=0; JSESSIONID=VzNmllbAmPDMInSJQ152bw__; $Path=/Order User-Agent: Jakarta Commons-HttpClient/3.1 Host: 192.168.1.22:8080 [1181 bytes missing in capture file]HTTP/1.1 200 OK Server: Apache-Coyote/1.1 X-Powered-By: Servlet 2.5; JBoss-5.0/JBossWeb-2.1 Content-Type: text/html;charset=ISO-8859-1 Content-Length: 1024 Date: Wed, 26 Jan 2011 17:10:40 GMT Connection: close
- set it to a specific value, higher than the default;
- disable persistent connections by setting the value
1; - set persistent connections to unlimited by setting the value
-1.
1 in effect disables persistent connections because this sets the limit to 1. The other options of raising the limit to a specific value and unlimited require further analysis of the situation. Setting the value to unlimited is easiest because the platform will use whatever it calculates to be the optimal value for the current workload. However it's possible to run out of operating system file descriptors, if there are more concurrent clients than there are file descriptors available. Choosing a specific value is a more conservative approach and is less risky than using unlimited. The best method of finding the most suitable value is to monitor the maximum number of connections used and if this is higher than what's available, set it higher then do performance testing.
server.xml in which maxKeepAliveRequests is set to -1 or unlimited.
<!-- A HTTP/1.1 Connector on port 8080 -->
<Connector protocol="HTTP/1.1" port="8080" address="${jboss.bind.address}"
connectionTimeout="20000" redirectPort="8443"
maxKeepAliveRequests=”-1” />
2.1.2. maxThreads
maxThreads parameter creates the thread pool that sits directly behind the connector, and actually processes the request. It’s very important to set this for most workloads as the default is quite low, currently 200 threads. If no threads are available when the request is made, the request is refused so getting this value right is critical. In the event the maximum number of threads is reached, this will be noted in the log:
2011-01-27 16:18:08,881 INFO [org.apache.tomcat.util.net.JIoEndpoint] (http-192.168.1.22-8080-Acceptor-0) Maximum number of threads (200) created for connector with address /192.168.1.22 and port 8080
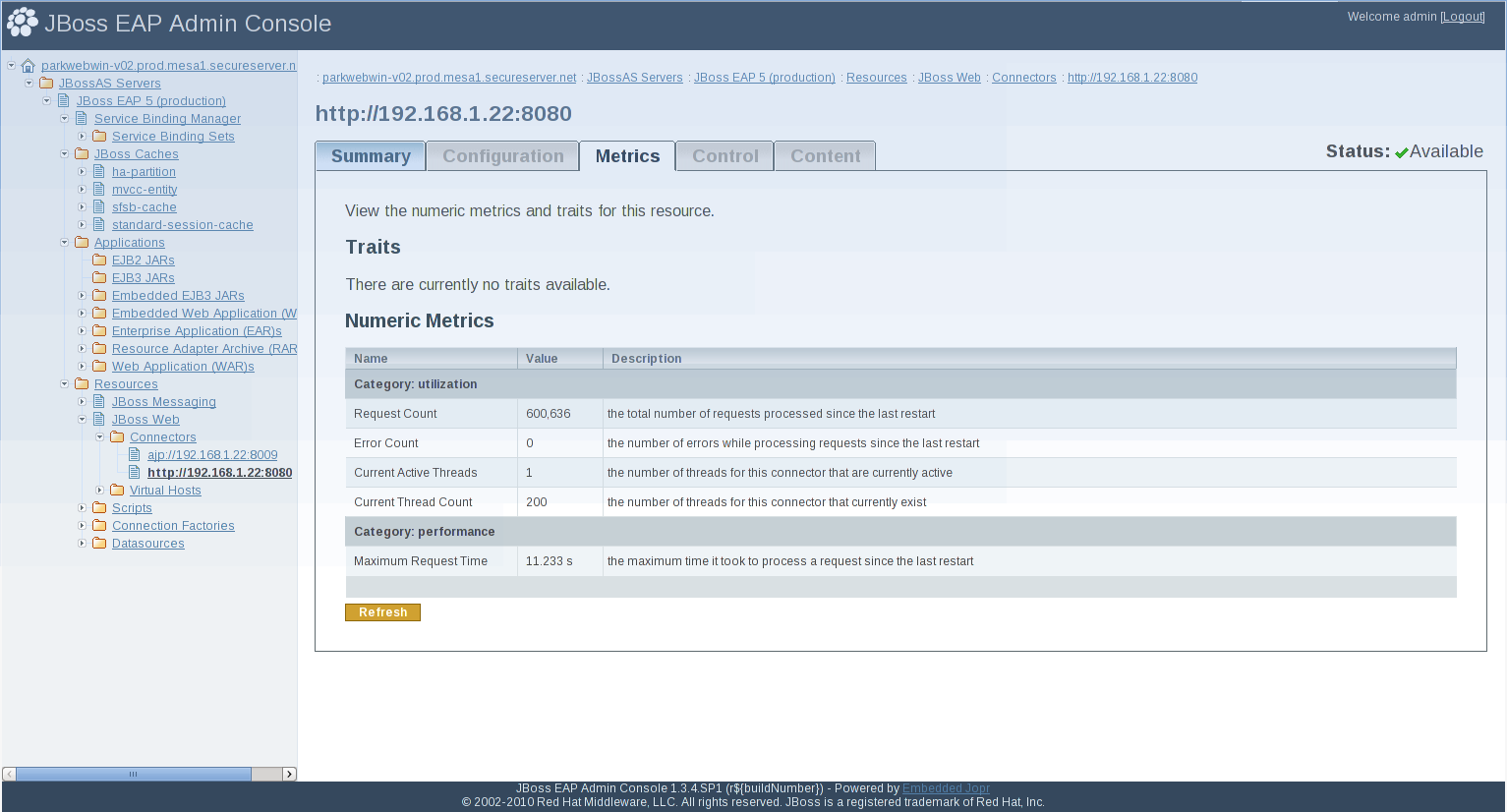
Figure 2.1. Connectors metrics
2.1.3. minSpareThreads
minSpareThreads parameter specifies the minimum number of threads that must be maintained in the thread pool. If sufficient resources are available set minSpareThreads to the same value as maxThreads. If maxThreads is set to represent a peak, but that peak does not last very long, set minSpareThreads to a lower value. That way, the platform can reclaim those resources as threads sit idle. There are a couple of ways to look at the interaction between these two parameters. If resource consumption is not an issue, set minSpareThreads to what you need to process at peak loads, but allow for an increase by setting maxThreads between 10% and 25% higher. If resource consumption is a concern, then set the maxThreads to only what you need for peak, and set the minSpareThreads to a value that won’t hurt overall throughput after a drop in load occurs. Most applications have large swings in load over the course of a given day.
Note
2.1.4. Tuning the thread pool
maxThreads parameter, it needs to be increased and again monitored.
server.xml configuration file in which all three parameters are assigned specific values.
<!-- A HTTP/1.1 Connector on port 8080 -->
<Connector protocol="HTTP/1.1" port="8080" address="${jboss.bind.address}"
connectionTimeout="20000" redirectPort="8443" maxThreads="3000"
minSpareThreads="2000" maxKeepAliveRequests="-1" />
2.2. AJP Connector
- maxThreads
- minSpareThreads
server.xml. Below is an extract from server.xml in which both maxThreads and minSpareThreads have been configured:
<!-- A AJP 1.3 Connector on port 8009 -->
redirectPort="8443" maxThreads="3000" minSpareThreads="2000" />
<Connector protocol="AJP/1.3" port="8009" address="${jboss.bind.address}"
Chapter 3. Servlet Container
3.1. Cached Connection Manager
Connection connection = dataSource.getConnection(); transaction.begin(); <Do some work> transaction.commit();
transaction.begin(); Connection connection = datasource.getConnection(); <Do some work> transaction.commit();
default, standard and all configurations, the CachedConnectionManager is configured to be in the servlet container in debug mode. It's also configured in the production configuration but with debug mode off. If you do not use BMT, and/or you do not have the anti-pattern, described earlier, it's best to remove the CachedConnectionManager. The configuration is in the file server.xml in the directory JBOSS_EAP_DIST/jboss-as/server/<PROFILE>/deploy/jbossweb.sar. Note that the minimal configuration does not include JBoss Web.
server.xml in which the CachedConnectionManager is enabled.
<!-- Check for unclosed connections and transaction terminated checks in servlets/jsps. Important: The dependency on the CachedConnectionManager in META-INF/jboss-service.xml must be uncommented, too --> <Valve className="org.jboss.web.tomcat.service.jca.CachedConnectionValve" cachedConnectionManagerObjectName="jboss.jca:service=CachedConnectionManager" transactionManagerObjectName="jboss:service=TransactionManager" />
<!-- Check for unclosed connections and transaction terminated checks in servlets/jsps.
Important: The dependency on the CachedConnectionManager in META-INF/jboss-service.xml must be uncommented, too
<Valve className="org.jboss.web.tomcat.service.jca.CachedConnectionValve"
cachedConnectionManagerObjectName="jboss.jca:service=CachedConnectionManager"
transactionManagerObjectName="jboss:service=TransactionManager" />
-->
jboss-beans.xml in the JBOSS_EAP_DIST/jboss-as/server/<PROFILE>/deploy/jbossweb.sar/META-INF directory. Note that the minimal configuration does not include JBoss Web. This file is used by the micro-container for JBoss Web’s integration with it, and it specifies the connections between the dependent components. In this case, the CachedConnectionManager’s valve is dependent on the transaction manager. So, in order to get rid of the valve properly, we have to remove the dependency information from this configuration file. The pertinent information is at the top of the file, and it looks like the following:
<!-- Only needed if the org.jboss.web.tomcat.service.jca.CachedConnectionValve
is enabled in the tomcat server.xml file.
-→
<depends>jboss.jca:service=CachedConnectionManager</depends>
<!-- Transaction manager for unfinished transaction checking in the CachedConnectionValve -->
<depends>jboss:service=TransactionManager</depends>
<!-- Only needed if the org.jboss.web.tomcat.service.jca.CachedConnectionValve
is enabled in the tomcat server.xml file.
-→
<!--<depends>jboss.jca:service=CachedConnectionManager</depends> -→
<!-- Transaction manager for unfinished transaction checking in the CachedConnectionValve -->
<!--<depends>jboss:service=TransactionManager</depends>-->
3.2. HTTP Session Replication
3.2.1. Full Replication
HTTP session size x active sessions x number of nodes
3.2.2. Buddy Replication
jboss-cache-manager-jboss-beans.xml, in the directory: JBOSS_EAP_DIST/jboss-as/server/<PROFILE>/deploy/cluster/jboss-cache-manager.sar/META-INF. Note that the default, standard and minimal configurations do not have the clustering configuration, nor do they have clustering code deployed.
<!-- Standard cache used for web sessions -->
<entry><key>standard-session-cache</key>
<value>
<bean name="StandardSessionCacheConfig" class="org.jboss.cache.config.Configuration">
...
<property name="buddyReplicationConfig">
<bean class="org.jboss.cache.config.BuddyReplicationConfig">
<!-- Just set to true to turn on buddy replication -->
<property name="enabled">true</property>3.2.3. Monitoring JGroups via JMX
- jboss.jgroups:cluster=<cluster_name>,protocol=UDP,type=protocol
- Provides statistical information on the sending and receipt of messages over the network, along with statistics on the behavior of the two thread pools used to carry incoming messages up the channel's protocol stack.Useful attributes directly related to the rate of transmission and receipt include
MessagesSent,BytesSent,MessagesReceivedandBytesReceived.Useful attributes related to the behavior of the thread pool used to carry ordinary incoming messages up the protocol stack includeIncomingPoolSizeandIncomingQueueSize. Equivalent attributes for the pool of threads used to carry special, unordered "out-of-band" messages up the protocol stack includeOOBPoolSizeandOOBQueueSize. Note thatOOBQueueSizewill typically be0as the standard JGroups configurations do not use a queue for OOB messages. - jboss.jgroups:cluster=<cluster_name>,protocol=UNICAST,type=protocol
- Provides statistical information on the behavior of the protocol responsible for ensuring lossless, ordered delivery of unicast (i.e. point-to-point) messages.The ratio of
NumRetransmissionstoMessagesSentcan be tracked to see how frequently messages are not being received by peers and need to be retransmitted. TheNumberOfMessagesInReceiveWindowsattribute can be monitored to track how many messages are queuing up on a recipient node waiting for a message with an earlier sequence number to be received. A high number indicates messages are being dropped and need to be retransmitted. - jboss.jgroups:cluster=<cluster_name>,protocol=NAKACK,type=protocol
- Provides statistical information on the behavior of the protocol responsible for ensuring lossless, ordered delivery of multicast (i.e. point-to-multipoint) messages.Use the
XmitRequestsReceivedattribute to track how often a node is being asked to re-transmit a messages it sent; useXmitRequestsSentto track how often a node is needing to request retransmission of a message. - jboss.jgroups:cluster=<cluster_name>,protocol=FC,type=protocol
- Provides statistical information on the behavior of the protocol responsible for ensuring fast message senders do not overwhelm slow receivers.Attributes useful for monitoring whether threads seeking to send messages are having to block while waiting for credits from receivers include
Blockings,AverageTimeBlockedandTotalTimeBlocked.
Chapter 4. EJB 3 Container
4.1. Stateless Session Bean
- ThreadLocalPool
- StrictMaxPool
4.1.1. ThreadLocalPool
4.1.2. StrictMaxPool
javax.ejb.EJBException: Failed to acquire the pool semaphore, strictTimeout=10000
4.1.3. Pool Sizing
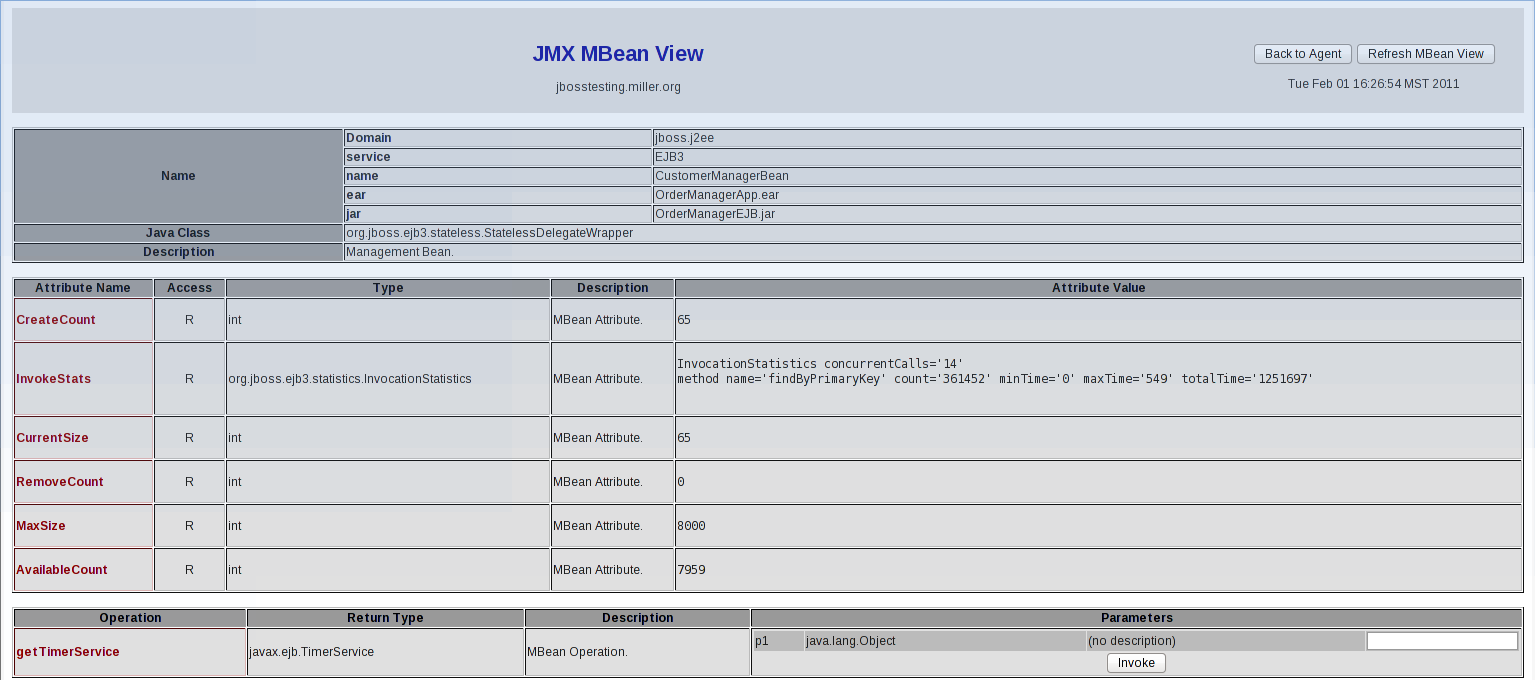
Figure 4.1. JMX Console - JMX MBean View
Note
ejb3-interceptors-aop.xml, which is located in the directory: JBOSS_EAP_DIST/jboss-as/server/<PROFILE>/deploy. The relevant sections are titled “Stateless Bean” and “JACC Stateless Bean”. Stateless Bean is a basic, stateless bean while JACC Stateless Bean provides for permission classes to satisfy the Java EE authorization model. Note that the minimal configuration does not include the EJB 3 container.
Note
4.1.4. Local EJB3 Calls
-Dorg.jboss.ejb3.remoting.IsLocalInterceptor.passByRef=true to JAVA_OPTS in the server's run.conf configuration file.
4.2. Stateful Session Bean
4.2.1. Stateful Configuration
jboss-cache-manager.sar, in the directory JBOSS_EAP_DIST/jboss-as/server/PROFILE/deploy/cluster/jboss-cache-manager.sar/META-INF. Note that the default, standard and minimal configurations do not have the clustering configuration, nor the clustering code deployed. In this file is an entry called sfsb-cache, as seen below:
<!-- Standard cache used for EJB3 SFSB caching -->
<entry><key>sfsb-cache</key>
<value>
<bean name="StandardSFSBCacheConfig" class="org.jboss.cache.config.Configuration">
<!-- No transaction manager lookup -->
<!-- Name of cluster. Needs to be the same for all members -->
<property name="clusterName">${jboss.partition.name:DefaultPartition}-SFSBCache</property>
<!-- Use a UDP (multicast) based stack. Need JGroups flow control (FC)
because we are using asynchronous replication. -->
<property name="multiplexerStack">${jboss.default.jgroups.stack:udp}</property>
<property name="fetchInMemoryState">true</property>
<property name="nodeLockingScheme">PESSIMISTIC</property>
<property name="isolationLevel">REPEATABLE_READ</property>
4.2.2. Full Replication
4.2.3. Buddy Replication
jboss-cache-manager-jboss-beans.xml, in the directory JBOSS_EAP_DIST/jboss-as/server/PROFILE/deploy/cluster/jboss-cache-manager.sar/META-INF. Note that the default, standard and minimal configurations do not have the clustering configuration, nor the clustering code deployed. To configure buddy replication for stateful session beans, change the buddyReplicationConfig's property to true, as in the following extract.
<!-- Standard cache used for EJB3 SFSB caching -->
<entry><key>sfsb-cache</key>
<value>
<bean name="StandardSFSBCacheConfig" class="org.jboss.cache.config.Configuration">
...
<property name="buddyReplicationConfig">
<bean class="org.jboss.cache.config.BuddyReplicationConfig">
<!-- Just set to true to turn on buddy replication -->
<property name="enabled">true</property>
4.3. Remote EJB Clients
maxPoolSize and clientMaxPoolSize. Local clients use the local interface of stateless and stateful session beans, so the execution of those methods is done on the incoming connectors' thread pool. Remote clients call the remote interfaces of stateless and stateful session beans, interacting with the platform's remoting solution. It accepts connections from remote clients, marshals the arguments and calls the remote interface of the corresponding bean, whether that is a stateless or stateful session bean. Note that the minimal configuration does not have the remoting service deployed.
remoting-jboss-beans.xml, in the directory JBOSS_EAP_DIST/jboss-as/server/<PROFILE>/deploy, an extract of which is below:
<!-- Parameters visible only to server -->
<property name="serverParameters">
<map keyClass="java.lang.String" valueClass="java.lang.String">
<!-- Selected optional parameters: -->
<!-- Maximum number of worker threads on the -->
<!-- server (socket transport). Defaults to 300. -->
<!--entry><key>maxPoolSize</key> <value>500</value></entry-->
<!-- Number of seconds after which an idle worker thread will be -->
<!-- purged (socket transport). By default purging is not enabled. -->
<!--entry><key>idleTimeout</key> <value>60</value></entry-->
</map>
</property>
maxPoolSize parameter which specifies the number of worker threads that will be used to execute the remote calls. The comments state that the default is 300, which is quite large, but that depends on the number of remote clients, their request rate, and the corresponding response times. Just like any other connector, the number of clients calling the server, their request rate, and the corresponding response times need to be taken into account to size the pool correctly. One way to determine this is to monitor the statistics on the client to see how many invocations occur. For example, if the remote client is a stateless session bean on another server, the JMX console contains invocation statistics that could be examined to determine how many concurrent calls are coming from that client. If there are many remote servers acting as clients then statistics have to be obtained from each remote client. To change the pool size, uncomment the line and set the value.
clientMaxPoolSize, specified in the same configuration file as above:
<!-- Maximum number of connections in client invoker's --> <!-- connection pool (socket transport). Defaults to 50. --> <!--entry><key>clientMaxPoolSize</key> <value>20</value></entry-->
Figure 4.2. JMX Console - JMX MBean View
InvokeStats and it has an attribute value that shows the InvocationStatistics class, and the value concurrentCalls equals 14. This could give you a hint about how many client connections need to be available in the pool.
4.4. CachedConnectionManager
minimalconfiguration does not contain the EJB 3 container.
ejb3-interceptors-aop.xml, in the directory: JBOSS_EAP_DIST/jboss-as/server/<PROFILE>/deploy.
<interceptor factory="org.jboss.ejb3.connectionmanager.CachedConnectionInterceptorFactory" scope="PER_CLASS"/> <interceptor-ref name="org.jboss.ejb3.connectionmanager.CachedConnectionInterceptorFactory"/>
standardjboss.xml, in the directory: JBOSS_EAP_DIST/jboss-as/server/<PROFILE>/conf. Note that the minimal configuration, does not contain the EJB 2.x container.
<interceptor>org.jboss.resource.connectionmanager.CachedConnectionInterceptor</interceptor>
4.5. Entity Beans
- second-level cache
- prepared statements
- batch inserts
- batching database operations
4.5.1. Second level cache
persistence.xml file that is packaged with an application. Here is an extract from persistence.xml:
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd"
version="1.0">
<persistence-unit name="services" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:/MySqlDS</jta-data-source>
<properties>
<property name="hibernate.cache.region.factory_class" value="org.hibernate.cache.jbc2.JndiMultiplexedJBossCacheRegionFactory"/>
<property name="hibernate.cache.region.jbc2.cachefactory" value="java:CacheManager"/>
<property name="hibernate.cache.use_second_level_cache" value="true"/>
<property name="hibernate.cache.use_query_cache" value="false"/>
<property name="hibernate.cache.use_minimal_puts" value="true"/>
<property name="hibernate.cache.region.jbc2.cfg.entity" value="mvcc-entity"/>
<property name="hibernate.cache.region_prefix" value="services"/>
</properties>
</persistence-unit>
</persistence>hibernate.cache.region.factory_class specifies the cache factory to be used by the underlying Hibernate session factory, in this example JndiMultiplexedJBossCacheRegionFactory. This factory implementation creates a single cache for all types of data that can be cached (entities, collections, query results and timestamps). With other options you can create caches that are tailored to each type of data, in separate cache instances. In this example, there is only one cache instance, and only entities and collections are cached. The second important parameter above is the hibernate.cache.use_second_level_cache, which is set to true, enabling the cache. The query cache is disabled with hibernate.cache.use_query_cache set to false.
hibernate.cache.use_minimal_puts, set to true, specifies the behavior of writes to the cache. It minimizes the writes to the cache at the expense of more reads, the default for a clustered cache.
hibernate.cache.region.jbc2.cfg.entity specifies the underlying JBoss Cache configuration, in this case the multiversion concurrency control (MVCC) entity cache (mvcc-entity).
hibernate.cache.region_prefix is set to the same name as the persistent unit itself. Specifying a name here is optional, but if you do not specify a name, a long default name is generated. The mvcc-entity configuration is in the file jboss-cache-manager-jboss-beans.xml, in the directory: JBOSS_EAP_DIST/jboss-as/server/<PROFILE>/deploy/cluster/jboss-cache-manager.sar/META-INF. Note that the default, standard and minimal configurations do not have the JBoss Cache configured or deployed.
<!-- A config appropriate for entity/collection caching that uses MVCC locking -->
<entry><key>mvcc-entity</key>
<value>
<bean name="MVCCEntityCache" class="org.jboss.cache.config.Configuration">
<!-- Node locking scheme -->
<property name="nodeLockingScheme">MVCC</property>
<!-- READ_COMMITTED is as strong as necessary for most
2nd Level Cache use cases. -->
<property name="isolationLevel">READ_COMMITTED</property>
<property name="useLockStriping">false</property>
<!-- Mode of communication with peer caches.
INVALIDATION_SYNC is highly recommended as the mode for use
with entity and collection caches. -->
<property name="cacheMode">INVALIDATION_SYNC</property>
<property name="evictionConfig">
<bean class="org.jboss.cache.config.EvictionConfig">
<property name="wakeupInterval">5000</property>
<!-- Overall default -->
<property name="defaultEvictionRegionConfig">
<bean class="org.jboss.cache.config.EvictionRegionConfig">
<property name="regionName">/</property>
<property name="evictionAlgorithmConfig">
<bean class="org.jboss.cache.eviction.LRUAlgorithmConfig">
<!-- Evict LRU node once we have more than this number of nodes -->
<property name="maxNodes">500000</property>
<!-- And, evict any node that hasn't been accessed in this many seconds -->
<property name="timeToLiveSeconds">7200</property>
<!-- Do not evict a node that's been accessed within this many seconds.
Set this to a value greater than your max expected transaction length. -->
<property name="minTimeToLiveSeconds">300</property>
</bean>
</property>
</bean>
</property>
- isolationLevel
- cacheMode
- maxNodes
- timeToLiveSeconds
- minTimeToLiveSeconds
isolationLevel is similar to database isolation level for transactions. JBoss Cache is fully transactional and can participate as a full resource in transactions, so that stale data is not stored in the cache. Some applications may not be affected by stale data in a cache so configuration can vary accordingly. The default is READ_COMMITTED, which is the same as in the example data source configuration for the database connection pool. It's recommended to set this the same as in the data source to avoid odd behavior in the application. JBoss Cache supports the following isolation levels:
- NONE
- READ_UNCOMMITTED
- READ_COMMITTED
- REPEATABLE_READ
- SERIALIZABLE
cacheMode specifies that across the cluster, cached entities will be invalidated on other nodes, so that another node does not return a different value. Invalidation is done in a synchronous manner, which ensures that the cache is in a correct state when the invalidation request completes. This is very important for caches when in a cluster, and is the recommended setting. Replication, instead of invalidation, is an option, but is much more expensive and limits scalability, possibly preventing caching from being effective in providing increased throughput. In this example, cacheMode is set to INVALIDATION_SYNC.
maxNodes, timeToLiveSeconds, and minTimeToLiveSeconds - define the size of the cache and how long things live in the cache.
maxNodes specifies the maximum number of nodes that can be in the cache at any one time. The default for maxNodes is 10,000, which is quite small, and in the example configuration it was set to 500,000. Deciding how large to make this value depends on the entities being cached, the access pattern of those entities, and how much memory is available to use. If the cache uses too much memory, other platform components could be starved of resources and so performance may be degraded. If the cache is too small, not enough entities may be stored in the cache to be of benefit.
timeToLiveSeconds specifies how long something remains in the cache before it becomes eligible to be evicted. The default value is 1,000 seconds or about 17 minutes, which is a quite short duration. Understanding the access and load pattern is important. Some applications have very predictable load patterns, where the majority of the load occurs at certain times of day, and lasts a known duration. Tailoring the time that entities stay in the cache towards that pattern helps tune performance.
minTimeToLive sets the minimum amount of time an entity will remain in the cache, the default being 120 seconds, or two minutes. This parameter should be set to equal or greater than the maximum transaction timeout value, otherwise it's possible for a cached entity to be evicted from the cache before the transaction completes.
4.5.1.1. Marking entities to be cached
- import org.hibernate.annotations.Cache;
- import org.hibernate.annotations.CacheConcurrencyStrategy;
- NONE
- NONSTRICT_READ_WRITE
- READ_ONLY
- TRANSACTIONAL
READ_ONLY guarantees that the entity will never change while the application is running. This allows the use of read only semantics, which is by far the most optimal performing cache concurrency strategy.
TRANSACTIONAL allows the use of database ACID semantics on entities in the cache. Anything to be cached while the application is running should be marked TRANSACTIONAL. Avoid caching entities that are likely to be updated frequently. If an entity is updated too frequently, caching can actually increase overhead and so slow throughput. Each update sends an invalidation request across the cluster, so that the state is correctly maintained as well, so the overhead affects every node, not only the node where the update occurs.
4.5.2. Prepared Statements
JBOSS_EAP_DIST/jboss-as/server/PROFILE/deploy. Note that the minimal configuration does not support data sources.
<prepared-statement-cache-size>100</prepared-statement-cache-size> <shared-prepared-statements>true</shared-prepared-statements>
4.5.3. Batch Inserts
INSERT INTO EJB3.OrderLine (OrderId, LineNumber, ProductId, Quantity, Price, ExtendedPrice) VALUES("67ef590kalk4568901thbn7190akioe1", 1, 25, 10, 1.00, 10.00);
INSERT INTO EJB3.OrderLine (OrderId, LineNumber, ProductId, Quantity, Price, ExtendedPrice) VALUES("67ef590kalk4568901thbn7190akioe1", 2, 16, 1, 1.59, 1.59);
INSERT INTO EJB3.OrderLine (OrderId, LineNumber, ProductId, Quantity, Price, ExtendedPrice) VALUES("67ef590kalk4568901thbn7190akioe1", 3, 55, 5, 25.00, 125.00);
INSERT INTO EJB3.OrderLine (OrderId, LineNumber, ProductId, Quantity, Price, ExtendedPrice) VALUES("67ef590kalk4568901thbn7190akioe1", 4, 109, 1, 29.98, 29.98);
INSERT INTO EJB3.OrderLine (OrderId, LineNumber, ProductId, Quantity, Price, ExtendedPrice) VALUES("67ef590kalk4568901thbn7190akioe1", 1, 25, 10, 1.00, 10.00)
, ("67ef590kalk4568901thbn7190akioe1", 2, 16, 1, 1.59, 1.59)
, ("67ef590kalk4568901thbn7190akioe1", 3, 55, 5, 25.00, 125.00)
, ("67ef590kalk4568901thbn7190akioe1", 4, 109, 1, 29.98, 29.98);
Note
@TransactionTimeout(4800)
public void createInventories(int batchSize) throws CreateDataException {
if(numberOfInventoryRecords() > 0) {
throw new CreateDataException("Inventory already exists!");
}
int rowsToFlush = 0, totalRows = 0;
Random quantity = new Random(System.currentTimeMillis());
List<Product> products = productManager.findAllProducts();
List<DistributionCenter> distributionCenters = distributionCenterManager.findAllDistributionCenters();
InventoryPK inventoryPk = null;
Inventory inventory = null;
for(Product product: products) {
for(DistributionCenter distributionCenter: distributionCenters) {
inventoryPk = new InventoryPK();
inventory = new Inventory();
inventoryPk.setProductId(product.getProductId());
inventoryPk.setDistributionCenterId(distributionCenter.getDistributionCenterId());
inventory.setPrimaryKey(inventoryPk);
inventory.setQuantityOnHand(quantity.nextInt(25000));
inventory.setBackorderQuantity(0);
inventory.setVersion(1);
batchEntityManager.persist(inventory);
rowsToFlush++;
totalRows++;
if(rowsToFlush == batchSize) {
batchEntityManager.flush();
rowsToFlush = 0;
batchEntityManager.clear();
if(log.isTraceEnabled()) {
log.trace("Just flushed " + batchSize + " rows to the database.");
log.trace("Total rows flushed is " + totalRows);
}
}
}
}
return;
}
persistence.xml for the persistence unit of the application entities.
<persistence-unit name="batch-services" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:/MySqlDS</jta-data-source>
<properties>
<property name="hibernate.hbm2ddl.auto" value="none"/>
<property name="hibernate.default_catalog" value="EJB3"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect"/>
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_versioned_data" value="true"/>
<property name="hibernate.jdbc.fetch_size" value="50000"/>
<property name="hibernate.jdbc.batch_size" value="50000"/>
<property name="hibernate.default_batch_fetch_size" value="50000"/>
<property name="hibernate.connection.release_mode" value="auto"/>
</properties>
</persistence-unit>
public Order createOrder(Customer customer
, List<OrderLine> orderLines
, BigDecimal totalOrderAmount) {
String addressLine2 = customer.getAddressLine2();
if (addressLine2 == null) {
addressLine2 = "";
}
Address shippingAddress = new Address();
shippingAddress.setAddressLine1(customer.getAddressLine1());
shippingAddress.setAddressLine2(addressLine2);
shippingAddress.setCity(customer.getCity());
shippingAddress.setState(customer.getState());
shippingAddress.setZipCode(customer.getZipCode());
shippingAddress.setZipCodePlusFour(customer.getZipCodePlusFour());
Order newOrder = new Order();
newOrder.setCustomerId(customer.getCustomerId());
newOrder.setDistributionCenterId(customer.getDistributionCenterId());
newOrder.setShippingAddressLine1(shippingAddress.getAddressLine1());
newOrder.setShippingAddressLine2(shippingAddress.getAddressLine2());
newOrder.setShippingCity(shippingAddress.getCity());
newOrder.setShippingState(shippingAddress.getState());
newOrder.setShippingZipCode(shippingAddress.getZipCode());
newOrder.setShippingZipCodePlusFour(shippingAddress.getZipCodePlusFour());
newOrder.setTotalOrderAmount(totalOrderAmount);
newOrder.setOrderDate(new Date());
newOrder.setCustomer(customer);
entityManager.persist(newOrder);
String orderId = newOrder.getOrderId();
for (OrderLine orderLine: orderLines) {
orderLine.getOrderLinePK().setOrderId(orderId);
}
newOrder.setOrderLines(orderLines);
entityManager.persist(newOrder);
return newOrder;
}
<persistence-unit name="services" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:/MySqlDS</jta-data-source>
<properties>
<property name="hibernate.hbm2ddl.auto" value="none"/>
<property name="hibernate.default_catalog" value="EJB3"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect"/>
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_versioned_data" value="true"/>
<property name="hibernate.jdbc.fetch_size" value="500"/>
<property name="hibernate.jdbc.batch_size" value="500"/>
<property name="hibernate.default_batch_fetch_size" value="16"/>
<property name="hibernate.connection.release_mode" value="auto"/>
<property name="hibernate.cache.region.factory_class" value="org.hibernate.cache.jbc2.JndiMultiplexedJBossCacheRegionFactory"/>
<property name="hibernate.cache.region.jbc2.cachefactory" value="java:CacheManager"/>
<property name="hibernate.cache.use_second_level_cache" value="true"/>
<property name="hibernate.cache.use_query_cache" value="false"/>
<property name="hibernate.cache.use_minimal_puts" value="true"/>
<property name="hibernate.cache.region.jbc2.cfg.entity" value="mvcc-entity"/>
<property name="hibernate.cache.region_prefix" value="services"/>
</properties>
</persistence-unit>
true, and you can do this through setting the connection property in the data source XML file for MySQL as such:
<datasources>
<local-tx-datasource>
<jndi-name>MySqlDS</jndi-name>
<connection-url>jdbc:mysql://localhost:3306/EJB3</connection-url>
<driver-class>com.mysql.jdbc.Driver</driver-class>
<user-name>username</user-name>
<password>password</password>
<exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter</exception-sorter-class-name>
<min-pool-size>400</min-pool-size>
<max-pool-size>450</max-pool-size>
<!-- The transaction isolation level must be read committed for optimitic locking to work properly -->
<transaction-isolation>TRANSACTION_READ_COMMITTED</transaction-isolation>
<connection-property name="rewriteBatchedStatements">true</connection-property>
<!-- corresponding type-mapping in the standardjbosscmp-jdbc.xml (optional) -->
<metadata>
<type-mapping>mySQL</type-mapping>
</metadata>
</local-tx-datasource>
</datasources>
Warning
4.5.3.1. Batch Processing; Tests And Results
Example 4.1. Batch Processing Test
Test Parameters
- Environment:
- Quad-core Intel i7
- 8 GB of RAM
- MySQL database
- JBoss Enterprise Application Platform
productionprofile.
- Table Contents:
- 41,106 rows
- 250,000 products
- 6.25 million inventory records
- 2 thousand suppliers
- 1.25 million supplier inventory records
- 2 million rows for customers and pricing methods.
- Batching enabled in Hibernate.
- Batch insert size of 10,000 rows.
- MySQL Batching refers to the
rewriteBatchedStatementsparameter (which is set inmysql-ds.xml).
Table 4.1. Batch Processing Test Results
| MySQL Batching | Throughput (rows per second) |
|---|---|
| Result | 487.7% increase in throughput. |
| Off | 6,734.01 |
| On | 39,575.75 |
Example 4.2. OLTP Baseline Testing
Test Parameters
- Environment:
- Quad-core Intel i7
- 8 GB of RAM
- MySQL database
- JBoss Enterprise Application Platform
productionprofile.
- The composite benchmark is run with randomly created orders with 1 to 9 order line items. The average is around 4.5 to 5 order line items per order. This mimics a real world scenario.
- Batch processing off.
rewriteBatchedStatementsparameter unset inmysql-ds.xml.
Table 4.2. OLTP Baseline Results
| Order Inserts | Throughput (orders per second). |
|---|---|
| Result | Single item orders have the highest throughput, with five and nine following respectively. |
| 10,000 order inserts with a single order line item | 45.80 |
| 10,000 order inserts with five order line items | 43.96 |
| 10,000 order inserts with nine order line items | 43.14 |
Example 4.3. OLTP Hibernate Batch Processing Test
Test Parameters
- Environment:
- Quad-core Intel i7
- 8 GB of RAM
- MySQL database
- JBoss Enterprise Application Platform
productionprofile.
- The composite benchmark is run with randomly created orders with 1 to 9 order line items. The average is around 4.5 to 5 order line items per order. This mimics a real world scenario.
- Hibernate batch processing on.
- MySQL batching (
rewriteBatchedStatements) unset inmysql-ds.xml.
Table 4.3. OLTP Hibernate Batch Processing Results
| Order Inserts | Throughput (orders per second). |
|---|---|
| Result | Ordering the inserts lowered throughput slightly; differences range from .24 to .36 orders per second. |
| 10,000 order inserts with a single order line item | 45.64 |
| 10,000 order inserts with five order line items | 43.62 |
| 10,000 order inserts with nine order line items | 42.78 |
Example 4.4. OLTP Hibernate and MySQL Batch Processing Test
Test Parameters
- Environment:
- Quad-core Intel i7
- 8 GB of RAM
- MySQL database
- JBoss Enterprise Application Platform
productionprofile.
- The composite benchmark is run with randomly created orders with 1 to 9 order line items. The average is around 4.5 to 5 order line items per order. This mimics a real world scenario.
- Hibernate batch processing on.
- MySQL batching (
rewriteBatchedStatements) on inmysql-ds.xml.
Table 4.4. OLTP Hibernate and MySQL Batch Processing Results
| Order Inserts | Throughput (orders per second). |
|---|---|
| Result |
An increase in throughput ranging from .21 to .63 orders per second, with nine line item orders showing the highest improvement.
Five line item orders show a .66% improvement over the baseline and nine line item orders show a 1.46% improvement.
|
| 10,000 order inserts with a single order line item | 46.11 |
| 10,000 order inserts with five order line items | 44.25 |
| 10,000 order inserts with nine order line items | 43.77 |
Example 4.5. Higher Line Items Baseline Test
Test Parameters
- Environment:
- Quad-core Intel i7
- 8 GB of RAM
- MySQL database
- JBoss Enterprise Application Platform
productionprofile.
- The composite benchmark is run with randomly created orders with 1 to 9 order line items. The average is around 4.5 to 5 order line items per order. This mimics a real world scenario.
- Hibernate batch processing off.
- MySQL batching (
rewriteBatchedStatements) unset inmysql-ds.xml.
Table 4.5. Higher Line Items Baseline Results
| Order Inserts | Throughput (orders per second). |
|---|---|
| Result | Because 15 and 20 line items orders take much longer, the server can process even more single line item orders. |
| 10,000 order inserts with a single order line item | 53.34 |
| 10,000 order inserts with 15 order line items | 31.25 |
| 10,000 order inserts with 20 order line items | 30.09 |
Example 4.6. Higher Line Items Hibernate Batch Processing Test
Test Parameters
- Environment:
- Quad-core Intel i7
- 8 GB of RAM
- MySQL database
- JBoss Enterprise Application Platform
productionprofile.
- The composite benchmark is run with randomly created orders with 1 to 9 order line items. The average is around 4.5 to 5 order line items per order. This mimics a real world scenario.
- Hibernate batch processing on.
- MySQL batching (
rewriteBatchedStatements) unset inmysql-ds.xml.
Table 4.6. Higher Line Items Hibernate Batch Processing Results
| Order Inserts | Throughput (orders per second). |
|---|---|
| Result |
Single line item orders showed a 2.79% increase (an extra 1.49 orders per second).
15 line item orders increased by .06 orders per second and the twenty line item orders decreased by .03 orders per second. These results are within the expected margin of test variations.
|
| 10,000 order inserts with a single order line item | 54.83 |
| 10,000 order inserts with fifteen order line items | 31.31 |
| 10,000 order inserts with twenty order line items | 30.06 |
Example 4.7. Higher Line Items Hibernate And MySQL Batch Processing Test
Test Parameters
- Environment:
- Quad-core Intel i7
- 8 GB of RAM
- MySQL database
- JBoss Enterprise Application Platform
productionprofile.
- The composite benchmark is run with randomly created orders with 1 to 9 order line items. The average is around 4.5 to 5 order line items per order. This mimics a real world scenario.
- Hibernate batch processing on.
- MySQL batching (
rewriteBatchedStatements) on inmysql-ds.xml.
Table 4.7. Higher Line Items Hibernate And MySQL Batch Processing Results
| Order Inserts | Throughput (orders per second). |
|---|---|
| Result |
Single line orders showed a 13.97% increase, 15 line item orders showed an increase of 19.65% and 20 line item orders increased by 18.05%.
|
| 10,000 order inserts with a single order line item | 60.79 |
| 10,000 order inserts with fifteen order line items | 37.39 |
| 10,000 order inserts with twenty order line items | 35.52 |
Conclusions
4.5.4. Batching Database Operations
- hibernate.jdbc.fetch_size
- hibernate.jdbc.batch_size
hibernate.jdbc.fetch_size sets the statement's fetch size within the JDBC driver, that is the number of rows fetched when there is more than a one row result on select statements. In the second case, hibernate.jdbc.batch_size determines the number of updates (inserts, updates and deletes) that are sent to the database at one time for execution. This parameter is necessary to do batch inserts, but must be coupled with the ordered inserts parameter and the JDBC driver's capability to rewrite the inserts into a batch insert statement.
Warning
hibernate.jdbc.fetch_size. In the example application, there are queries that return a single row, queries that return 3 rows, and one query that can return up to 500 rows. In the last case, the query itself is actually limited through the API to 500 rows, although there can be many more rows than that that could satisfy the query. The other interesting thing to consider is the fact that the query that could return 500 rows is executed in a stateful session bean. When the query is executed, only 20 rows of data, of the total matching rows, are returned at one time to the client. If the client found what they wanted, and does not page further through the result set, only those first 20 rows (or fewer rows, if the query returns less than 20) will ever be used from the result set. Taking that into account, fetch_size values of 20 and 500 were tested. In tests, 20 gave the best result, with 500 actually being slightly slower. Twenty was also faster than the default of 1. In the case of 20 versus 500, 20 provided 1.73% more throughput while in the case of 20 vs. 1, 20 provided 2.33% more throughput. Aligning the value with the query that can return upwards of 500 rows, and paginating the results 20 rows at a time was the most effective. Thorough analysis of the queries in the application and the frequency with which those queries are executed is necessary to size this correctly.
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd"
version="1.0">
<persistence-unit name="services" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:/MySqlDS</jta-data-source>
<properties>
<property name="hibernate.hbm2ddl.auto" value="none"/>
<property name="hibernate.default_catalog" value="EJB3"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.default_batch_fetch_size" value="20"/>
<property name="hibernate.jdbc.fetch_size" value="20"/>
<property name="hibernate.jdbc.batch_size" value="20"/>
<property name="hibernate.cache.region.factory_class" value="org.hibernate.cache.jbc2.JndiMultiplexedJBossCacheRegionFactory"/>
<property name="hibernate.cache.region.jbc2.cachefactory" value="java:CacheManager"/>
<property name="hibernate.cache.use_second_level_cache" value="true"/>
<property name="hibernate.cache.use_query_cache" value="false"/>
<property name="hibernate.cache.use_minimal_puts" value="true"/>
<property name="hibernate.cache.region.jbc2.cfg.entity" value="mvcc-entity"/>
<property name="hibernate.cache.region_prefix" value="services"/>
</properties>
</persistence-unit>
<persistence-unit name="batch-services" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:/MySqlDS</jta-data-source>
<properties>
<property name="hibernate.hbm2ddl.auto" value="none"/>
<property name="hibernate.default_catalog" value="EJB3"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.fetch_size" value="50000"/>
<property name="hibernate.jdbc.batch_size" value="50000"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect"/>
<property name="hibernate.cache.use_second_level_cache" value="false"/>
</properties>
</persistence-unit>
</persistence>
hibernate.jdbc.batch_size, the Hibernate documentation recommends a value of between 5 and 30 but this value depends upon the application's needs. The Hibernate documentation's recommendation is suitable for most OLTP-like applications. If you examine insert and update queries within the application, you can make a determination of how many rows are inserted and updated across the set. If inserts or updates occur no more than one row at a time, then leaving it unspecified is suitable. If inserts and/or updates affects many rows at a time, in a single transaction, then setting this is very important. If batch inserts are not required, and the aim is to send all the updates in as few trips to the database as possible, you should size it according to what is really happening in the application. If the largest transaction you have is inserting and updating 20 rows, then set it 20, or perhaps a little larger to accommodate any future changes that might take place.
4.6. Message Driven Beans
@MessageDriven(activationConfig = {
@ActivationConfigProperty(propertyName="destinationType"
, propertyValue="javax.jms.Queue"),
@ActivationConfigProperty(propertyName="destination"
, propertyValue="queue/replenish")
@ActivationConfigProperty(propertyName=”minSessions”
, propertyValue=”25”)
@ActivationConfigProperty(propertyName=”maxSessions”
, propertyValue=”50”)
})ejb3-interceptors-aop.xml, in the directory JBOSS_EAP_DIST/jboss-as/server/PROFILE/deploy. Note that the minimal configuration does not contain the EJB 3 container.
<domain name="Message Driven Bean" extends="Intercepted Bean" inheritBindings="true">
<bind pointcut="execution(public * *->*(..))">
<interceptor-ref name="org.jboss.ejb3.security.AuthenticationInterceptorFactory"/>
<interceptor-ref name="org.jboss.ejb3.security.RunAsSecurityInterceptorFactory"/>
</bind>
<bind pointcut="execution(public * *->*(..))">
<interceptor-ref name="org.jboss.ejb3.tx.CMTTxInterceptorFactory"/>
<interceptor-ref name="org.jboss.ejb3.stateless.StatelessInstanceInterceptor"/>
<interceptor-ref name="org.jboss.ejb3.tx.BMTTxInterceptorFactory"/>
<interceptor-ref name="org.jboss.ejb3.AllowedOperationsInterceptor"/>
<interceptor-ref name="org.jboss.ejb3.entity.TransactionScopedEntityManagerInterceptor"/>
<!-- interceptor-ref name="org.jboss.ejb3.interceptor.EJB3InterceptorsFactory"/ -->
<stack-ref name="EJBInterceptors"/>
</bind>
<annotation expr="class(*) AND !class(@org.jboss.ejb3.annotation.Pool)">
@org.jboss.ejb3.annotation.Pool (value="StrictMaxPool", maxSize=15, timeout=10000)
</annotation>
</domain>
<domain name="Consumer Bean" extends="Intercepted Bean" inheritBindings="true">
<bind pointcut="execution(public * *->*(..))">
<interceptor-ref name="org.jboss.ejb3.security.RunAsSecurityInterceptorFactory"/>
</bind>
<bind pointcut="execution(public * *->*(..))">
<interceptor-ref name="org.jboss.ejb3.tx.CMTTxInterceptorFactory"/>
<interceptor-ref name="org.jboss.ejb3.stateless.StatelessInstanceInterceptor"/>
<interceptor-ref name="org.jboss.ejb3.tx.BMTTxInterceptorFactory"/>
<interceptor-ref name="org.jboss.ejb3.AllowedOperationsInterceptor"/>
<interceptor-ref name="org.jboss.ejb3.entity.TransactionScopedEntityManagerInterceptor"/>
</bind>
<bind pointcut="execution(public * *->*(..)) AND (has(* *->@org.jboss.ejb3.annotation.CurrentMessage(..)) OR hasfield(* *->@org.jboss.ejb3.annotation.CurrentMessage))">
<interceptor-ref name="org.jboss.ejb3.mdb.CurrentMessageInjectorInterceptorFactory"/>
</bind>
<bind pointcut="execution(public * *->*(..))">
<!-- interceptor-ref name="org.jboss.ejb3.interceptor.EJB3InterceptorsFactory"/ -->
<stack-ref name="EJBInterceptors"/>
</bind>
<annotation expr="class(*) AND !class(@org.jboss.ejb3.annotation.Pool)">
@org.jboss.ejb3.annotation.Pool (value="StrictMaxPool", maxSize=15, timeout=10000)
</annotation>
</domain>
Chapter 5. Java Connector Architecture
5.1. Data Sources
*-ds.xml file in the deploy directory of a specific configuration. The platform ships with examples for quite a few relational databases, and there is a complete list of certified relational databases on the JBoss Enterprise Application Platform product pages of the Red Hat website. A data source definition has many parameters but the focus here is on two specific parameters: min-pool-size and max-pool-size.
5.2. Data source connection pooling
5.3. Minimum pool size
min-pool-size data source parameter defines the minimum size of the connection pool. The default minimum is zero connections, so if a minimum pool size is not specified, no connections will be created in the connection pool when the platform starts. As data source transactions occur, connections will be requested but because the pool defaults to zero on start up, none will be available. The connection pool examines the minimum and maximum parameters, creates connections and places them in the pool. Users of any affected application will experience a delay while this occurs. During periods of inactivity the connection pool will shrink, possibly to the minimum value, and later when transactions later occur application performance will again suffer.
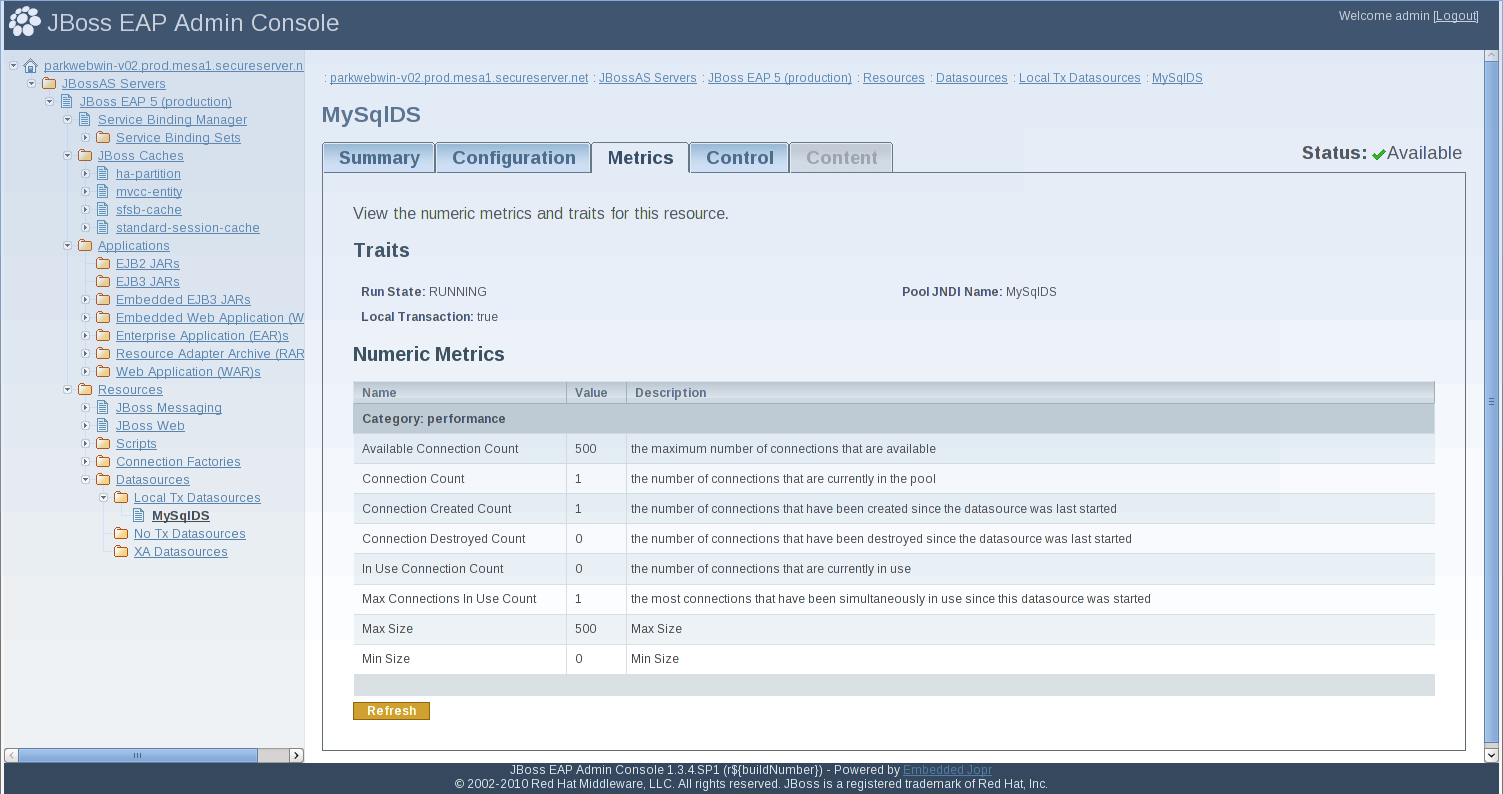
Figure 5.1. Data Source Metrics
5.4. Maximum pool size
max-pool-size parameter data source parameter defines the maximum size of the connection pool. It's more important that the min-pool-size parameter because it limits the number of active connections to the data source and so the concurrent activity on the data source. If this value is set too low it's likely that the platform's hardware resources will be underutilized.
Note
max-pool-size too low is a common configuration error.
5.5. Balancing pool size values
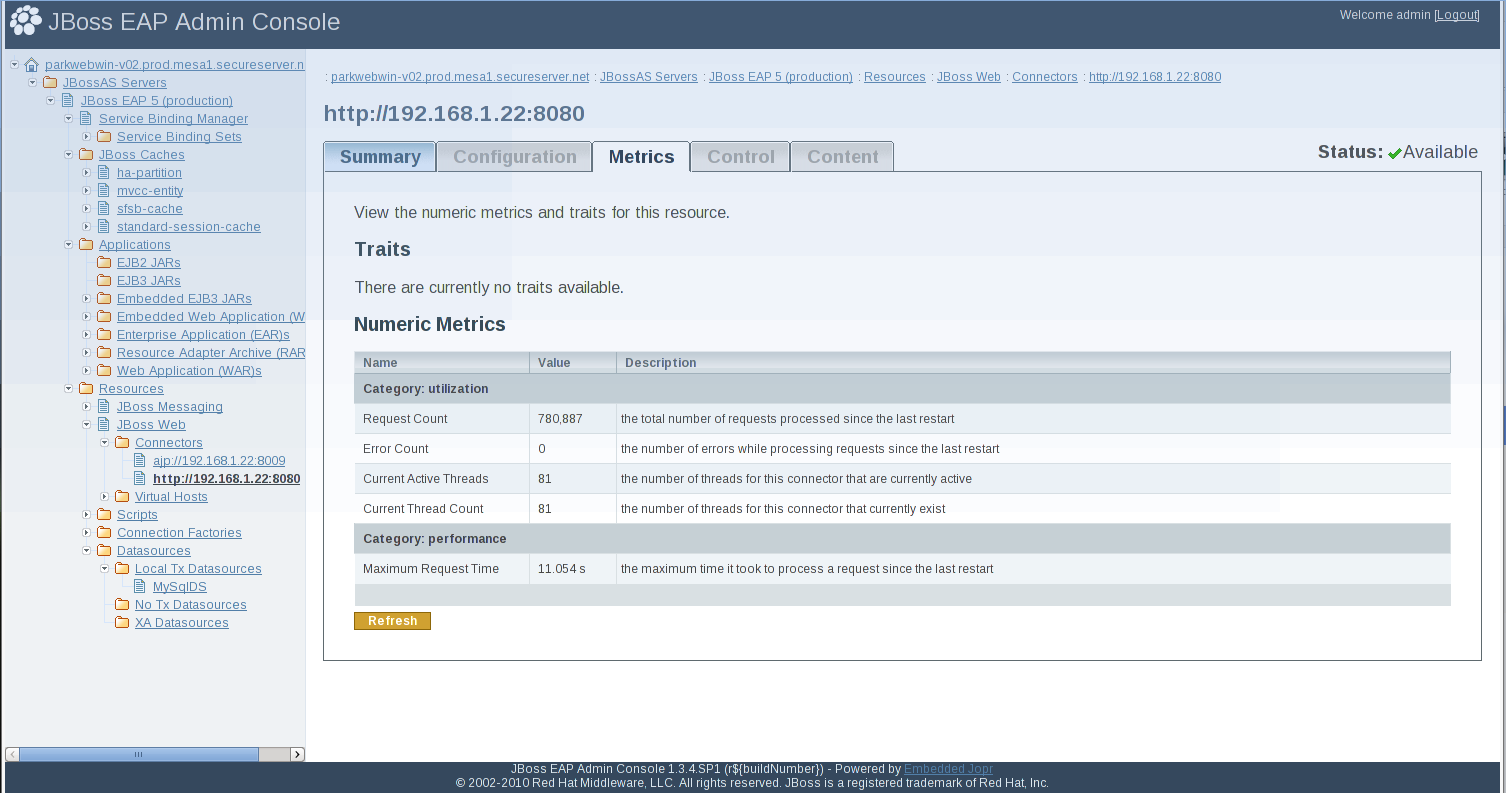
Figure 5.2. JMX Console Datasource Metrics
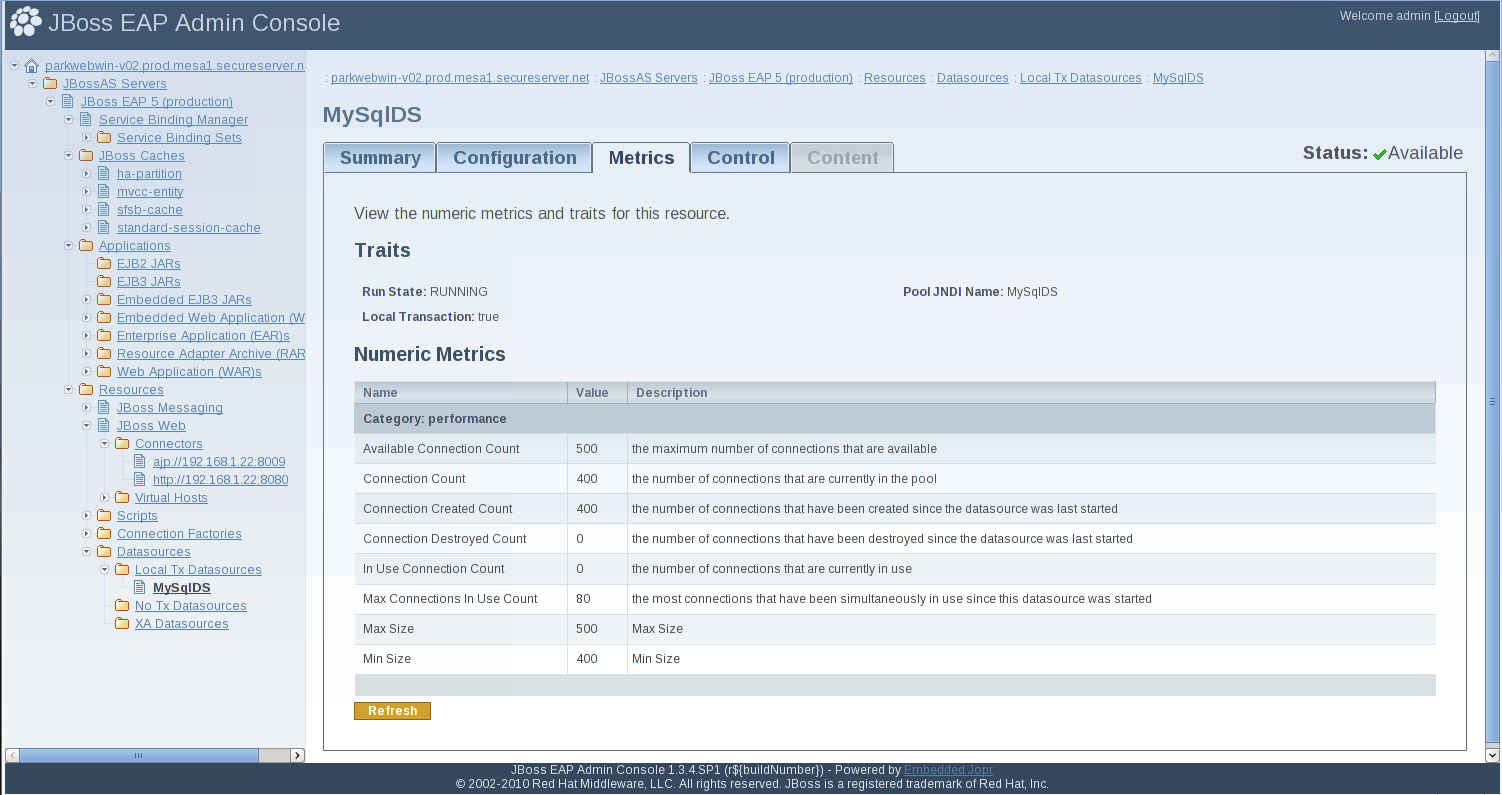
Figure 5.3. Admin Console Datasource Metrics
Thread: http-192.168.1.22-8080-2 : priority:5, demon:true, threadId:145, threadState:TIMED_WAITING - waiting on <0x2222b715> (a java.util.concurrent.Semaphore$FairSync) sun.misc.Unsafe.park(Native Method) java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:226) java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedNanos(AbstractQueuedSynchronizer.java:1037) java.util.concurrent.locks.AbstractQueuedSynchronizer.tryAcquireSharedNanos(AbstractQueuedSynchronizer.java:1326) java.util.concurrent.Semaphore.tryAcquire(Semaphore.java:410) org.jboss.resource.connectionmanager.InternalManagedConnectionPool.getConnection(InternalManagedConnectionPool.java:193) org.jboss.resource.connectionmanager.JBossManagedConnectionPool$BasePool.getConnection(JBossManagedConnectionPool.java:747) org.jboss.resource.connectionmanager.BaseConnectionManager2.getManagedConnection(BaseConnectionManager2.java:404) org.jboss.resource.connectionmanager.TxConnectionManager.getManagedConnection(TxConnectionManager.java:424) org.jboss.resource.connectionmanager.BaseConnectionManager2.allocateConnection(BaseConnectionManager2.java:496) org.jboss.resource.connectionmanager.BaseConnectionManager2$ConnectionManagerProxy.allocateConnection(BaseConnectionManager2.java:941) org.jboss.resource.adapter.jdbc.WrapperDataSource.getConnection(WrapperDataSource.java:89) org.hibernate.ejb.connection.InjectedDataSourceConnectionProvider.getConnection(InjectedDataSourceConnectionProvider.java:47) org.hibernate.jdbc.ConnectionManager.openConnection(ConnectionManager.java:446) org.hibernate.jdbc.ConnectionManager.getConnection(ConnectionManager.java:167)
5.6. JMS Integration or Provider
jca-jboss-beans.xml in the directory JBOSS_EAP_DIST/jboss-as/server/PROFILE/deploy. Note that the minimal configuration does not contain the JCA container.
Note
<!-- THREAD POOL --> <bean name="WorkManagerThreadPool" class="org.jboss.util.threadpool.BasicThreadPool"> <!-- Expose via JMX --> <annotation>@org.jboss.aop.microcontainer.aspects.jmx.JMX(name="jboss.jca:service=WorkManagerThreadPool", exposedInterface=org.jboss.util.threadpool.BasicThreadPoolMBean.class)</annotation> <!-- The name that appears in thread names --> <property name="name">WorkManager</property> <!-- The maximum amount of work in the queue --> <property name="maximumQueueSize">1024</property> <!-- The maximum number of active threads --> <property name="maximumPoolSize">100</property> <!-- How long to keep threads alive after their last work (default one minute) --> <property name="keepAliveTime">60000</property> </bean>
maximumPoolSize parameter specifies the number of threads in the thread pool for use by the JMS provider. The default size is 100, which may or may not be appropriate. If message driven beans are used in the application, make sure that there are enough threads in the thread pool to handle the maximum number of sessions. If only one message driven bean is used, ensure that the thread pool is at least the size of the number of sessions for that one bean. If there are many different message driven beans, the calculations are more complex.

Figure 5.4. JMX Console Thread Pool Statistics
maximumQueueSize parameter specifies how many requests will wait for a thread to become available before an exception is thrown and processing is aborted. The default value is 1024, which is a safe value. You may want to fail fast, versus wait for an extended period of time, or have more than 1024 requests backed up before failing. Setting this parameter to a lower value means you'll know earlier of exceptions but at the expense of application uptime. It's recommended to leave it at the default value as it provides greater reliability. If a request is waiting in the queue it's because there are none available in the pool. While sizing the pool, monitor the number of requests waiting in the queue to confirm whether or not the pool is too small.
Chapter 6. Java Message Service (JMS) Provider
6.1. Switching the Default Messaging Provider to HornetQ
switch.sh (switch.bat on Microsoft Windows Server) and can be found in the directory JBOSS_EAP_DIST/jboss-as/extras/hornetq. This script requires the open source build tool Ant be in the path in order to work.
Warning
6.2. Exploiting HornetQ's Support of Linux's Native Asynchronous I/O
/opt/redhat/jboss-eap-5.1, then the native code must be put in the same directory. This is because, being native code, it must be the right version for your RHEL version, and the right libraries for the JVM. Both the 32-bit and 64-bit JVMs are supported so there are 32-bit and 64-bit versions of the libraries. The run.sh script will automatically detect the directory relative to the EAP installation directory and resulting JBOSS_HOME that is set within that script (run.bat for Windows won’t have this, as this is a Linux only feature). If you have everything installed correctly, you should see this message in the log after start up.
10:50:05,113 INFO [JournalStorageManager] Using AIO Journal
2011-02-18 10:05:11,485 WARNING [org.hornetq.core.deployers.impl.FileConfigurationParser] (main) AIO wasn't located on this platform, it will fall back to using pure Java NIO. If your platform is Linux, install LibAIO to enable the AIO journal
Note
6.3. HornetQ's Journal
${jboss.server.data.dir}/${hornetq.data.dir}:hornetq/journal, which expands to: JBOSS_EAP_DIST/jboss-as/server/PROFILE/data/hornetq/journal. Note that the minimal configuration does not contain the JMS provider.
hornetq-configuration.xml, in the directory JBOSS_EAP_DIST/jboss-as/server/PROFILE/deploy/hornetq/.
<configuration xmlns="urn:hornetq"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:hornetq /schema/hornetq-configuration.xsd">
<!-- Do not change this name.
This is used by the dependency framework on the deployers,
to make sure this deployment is done before any other deployment -->
<name>HornetQ.main.config</name>
<clustered>true</clustered>
<log-delegate-factory-class-name>org.hornetq.integration.logging.Log4jLogDelegateFactory</log-delegate-factory-class-name>
<bindings-directory>${jboss.server.data.dir}/${hornetq.data.dir:hornetq}/bindings</bindings-directory>
<journal-directory>${jboss.server.data.dir}/${hornetq.data.dir:hornetq}/journal</journal-directory>
<journal-min-files>10</journal-min-files>
<large-messages-directory>${jboss.server.data.dir}/${hornetq.data.dir:hornetq}/largemessages</large-messages-directory>
<paging-directory>${jboss.server.data.dir}/${hornetq.data.dir:hornetq}/paging</paging-directory>
</configuration>
- journal-directory
- large-messages-directory
- paging-directory
journal-directory is the most critical with respect to performance but the others can also have a significant impact.
journal-directory is where persistent messages are stored.
large-message directory is used to store messages that are larger than can fit into memory. If the application processes large messages, this is also a performance critical directory.
paging-directory is similar to the large message directory, except that is an accumulation of many messages, that no longer fit into memory or are swapped/paged to disk, which is analogous to operating system paging to swap. Just like the journal and large message directory, this is also a performance critical directory, if swapping/paging occurs.
${jboss.server.data.dir} variable, by passing -Djboss.server.data.dir=<path> where path is the new directory location (higher performance file system and disk configuration). This will have the effect of moving everything that uses that directory to the new location, not just the HornetQ directories. This approach has an added bonus because there is another performance critical directory under that path, which contains the transaction journal. Transactions are logged for crash recovery purposes within this same path and this can also benefit from being located on higher-performing storage. The other option is to change the configuration directly, remove the ${jboss.server.data.dir} and replace it with the new location. In either case, moving this to faster storage will improve performance. Using the command-line option method is easiest because it uses the variable, so there's no need to change the configuration file.
6.4. HornetQ and Transactions
Chapter 7. Logging Provider
- console logging
- type of appender to use
- location of log files
- wrapping of log statements
7.1. Console Logging
jboss-log4j.xml in the directory JBOSS_EAP_DIST/jboss-as/server/PROFILE/conf. Note that the production configuration is preconfigured with console logging disabled.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<!-- ===================================================================== -->
<!-- -->
<!-- Log4j Configuration -->
<!-- -->
<!-- ===================================================================== -->
<!-- ====================== -->
<!-- More Appender examples -->
<!-- ====================== -->
<!-- Buffer events and log them asynchronously -->
<appender name="ASYNC" class="org.apache.log4j.AsyncAppender">
<errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/>
<appender-ref ref="FILE"/>
<appender-ref ref="CONSOLE"/>
<appender-ref ref="SMTP"/>
</appender>
<!-- ======================= -->
<!-- Setup the Root category -->
<!-- ======================= --><root>
<!--
Set the root logger priority via a system property. Note this is parsed by log4j,
so the full JBoss system property format is not supported; e.g.
setting a default via ${jboss.server.log.threshold:WARN} will not work.
-->
<priority value="${jboss.server.log.threshold}"/>
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
</root>
</log4j:configuration>7.2. Appenders
jboss-log4.xml in the directory JBOSS_EAP_DIST/jboss-as/server/<PROFILE>/conf.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<!-- ===================================================================== -->
<!-- -->
<!-- Log4j Configuration -->
<!-- -->
<!-- ===================================================================== -->
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/" debug="false">
<!-- ====================== -->
<!-- More Appender examples -->
<!-- ====================== -->
<!-- Buffer events and log them asynchronously -->
<appender name="ASYNC" class="org.apache.log4j.AsyncAppender">
<errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/>
<appender-ref ref="FILE"/>
<!--
<appender-ref ref="CONSOLE"/>
<appender-ref ref="SMTP"/>
-->
</appender>
<!-- ======================= -->
<!-- Setup the Root category -->
<!-- ======================= -->
<root>
<!--
Set the root logger priority via a system property. Note this is parsed by log4j,
so the full JBoss system property format is not supported; e.g.
setting a default via ${jboss.server.log.threshold:WARN} will not work.
-->
<priority value="${jboss.server.log.threshold}"/>
<!-- appender-ref ref="CONSOLE"/ -->
<appender-ref ref="ASYNC"/>
</root>
</log4j:configuration>
7.3. Location of Log Files
- Specify the preferred value for the variable from the command-line when starting JBoss Enterprise Application Platform, such as: -Djboss.server.log.dir=<path_for_log_files>
- Edit the configuration file, replacing the variable ${jboss.server.log.dir} with the preferred path.
7.4. Wrapping Log Statements
log.debug(“Some text…” + Object);
if (debugEnabled()) {
log.debug(“Some text...” + Object);
}
try..catch structure, where the exception is rare. Since the debug statement will only rarely be evaluated, the performance difference between wrapping and not wrapping the statement in a boolean expression is likely to be minimal. As usual, there should be a measurable gain from the effort put into performance improvements.
Chapter 8. Production Configuration
- Console logging is disabled.
- Asynchronous appender for logging is enabled.
- Logging verbosity is turned down in many cases.
- Additional categories are defined to limit logging.
- Default logging level is debug, but is overridden by the limit categories that were added.
- This enables support to make things easier for customers to turn on debug level logging for various components, since the customer can just comment out the limiting category, and they will have debug logging for it.
- The cached connection manager is set to not be in debug mode.
- Clustering is properly configured to work with supported databases.
- In the “all” configuration, the configuration is created to support the HSQL database, which is bundled for convenience with the server, but does not support clustering properly.
- This is specifically the UUID generator.
- The heap size is set higher than in the community edition.
- Typically the heap size for the JVM is set to 512 megabytes in the community edition. For the platform it's set to the largest value possible for a 32-bit JVM across all platforms.
- The largest 32-bit setting that works across all supported JVM and operating systems is 1.3 gigabytes (Windows sets the limit).
- All administration is secured by default.
- This was recently done in the community releases as well, so its now the same as the rest.
- Hot deployment is still turned on by default, but the scan rate is changed from every 5 seconds to once per minute.
- It could be disabled altogether but many customers do use it in production and if there a large number of deployments, scanning every 5 seconds can affect performance badly.
Chapter 9. Java Virtual Machine Tuning
9.1. 32-bit vs. 64-bit JVM
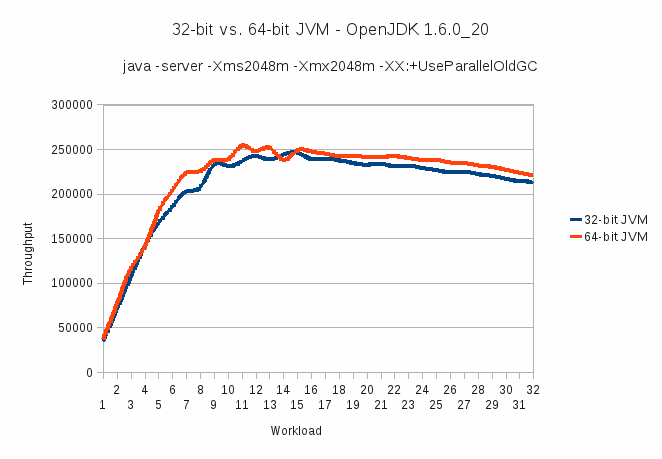
Figure 9.1. JVM Throughput - 32-bit versus 64-bit

Figure 9.2. JVM Throughput - comparison of incrementally larger heap sizes
9.2. Large Page Memory
-XX:+UseLargePages
kernel.shmmax = n
vm.nr_hugepages = n
vm.huge_tlb_shm_group = gid
/etc/security/limits.conf:
<username> soft memlock n <username> hard memlock n
unlimited, which reduces maintenance.
sysctl -p and these settings will be persistent. To confirm that this had taken effect, check that in the statistics available via /proc/meminfo, HugePages_Total is greater than 0. If HugePages_Total is either zero (0) or less than the value you configured, there are one of two things that could be wrong:
- the specified number of memory pages was greater than was available;
- there were not enough contiguous memory pages available.
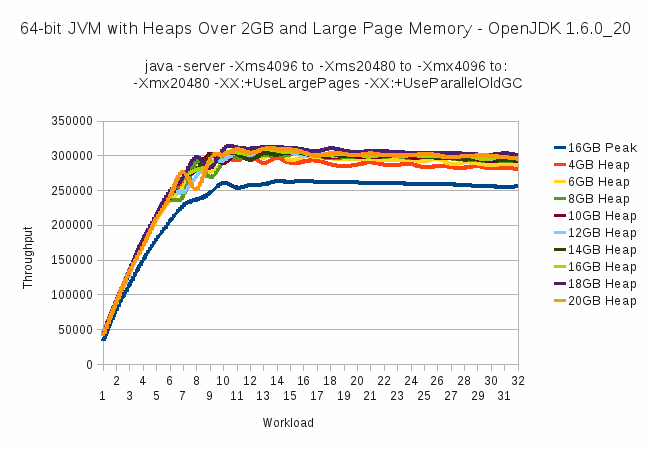
Figure 9.3. JVM Throughput - 32-bit versus 64-bit

Figure 9.4. JVM Throughput - comparison of with and without large pages enabled
9.3. Garbage Collection and Performance Tuning
-XX:+UseParallelOldGC. Many people choose the Concurrent Mark and Sweep (CMS) collector, collection is slower on both the Eden space and Old generation. The following graph shows the difference between using the throughput collector with parallel collection on the Old generation in comparison to using the CMS collector, which works on the Old generation and parallel collection on the Eden space.

Figure 9.5. Transactional OLTP Workload
-XX:+UseParallelOldGC, the throughput collector defaults to parallel collection on the Eden space, and single threaded collection on the Old generation. With a 12GB heap, the Old generation is 8GB in size, which is a lot of memory to garbage collect in a single thread fashion. By specifying that the Old generation should also be collected in parallel, the collection algorithms designed for the highest throughput is used, hence the name "throughput collector". When the option -XX:+UseParallelOldGC is specified it also enables the option -XX:+UseParNewGC. In comparison, the CMS collector is not optimized for throughput but instead for more predictable response times. The focus of this book is tuning for throughput, not response time. The choice of garbage collector depends on whether higher throughput or more predictable response times benefits the application most. For real-time systems, the trade-off is usually lower throughput for more deterministic results in response times.
9.4. Other JVM Options To Consider
- -XX:+CompressedOops
- -XX:+AggressiveOpts
- -XX:+DoEscapeAnalysis
- -XX:+UseBiasedLocking
- -XX:+EliminateLocks
Warning
Chapter 10. Profiling
10.1. Install
Task: Install OProfile
- In a terminal, enter the following command:
yum install oprofile oprofile-jit
- For all enabled yum repositories (/etc/yum.repos.d/*.repo), replace
enabled=0withenabled=1in each file's debuginfo section. If there is nodebugsection, add it, using the example below as a template.[rhel-debuginfo] name=Red Hat Enterprise Linux $releasever - $basearch - Debug baseurl=ftp://ftp.redhat.com/pub/redhat/linux/enterprise/$releasever/en/os/$basearch/Debuginfo/ enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
- In a terminal, enter the following command, modifying the JDK version number to match the version installed:
yum install yum-plugin-auto-update-debug-info java-1.6.0-openjdk-debuginfo
10.2. Enable OProfile
standalone.conf or domain.conf in the platform's JBOSS_EAP_DIST/bin directory.
# 64-bit JVM -agentpath:/usr/lib64/oprofile/libjvmti_oprofile.so # 32-bit JVM -agentpath:/usr/lib/oprofile/libjvmti_oprofile.so
# Specify options to pass to the Java VM. # if [ "x$JAVA_OPTS" = "x" ]; then JAVA_OPTS="-Xms10240m -Xmx10240m -XX:+UseLargePages -XX:+UseParallelOldGC" JAVA_OPTS="$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Dorg.jboss.resolver.warning=true" JAVA_OPTS="$JAVA_OPTS -Dsun.rmi.dgc.client.gcInterval=3600000 -Dsun.rmi.dgc.server.gcInterval=3600000" JAVA_OPTS="$JAVA_OPTS -agentpath:/usr/lib64/oprofile/libjvmti_oprofile.so" fi
10.3. Controlling OProfile
opcontrol is used to manage OProfile's state.
opcontrol --start-daemon
opcontrol --start
opcontrol --stop
opcontrol --dump
opcontrol --shutdown
10.4. Data Capture
- Start capturing profiling data
- Start/run the workload
- Stop capturing profiling data
- Dump profiling data
- Generate the profiling report
opreport -l --output-file=<filename>
Chapter 11. Putting It All Together
11.1. Test Configuration
- CPU: Intel Nehalem-based server with two, four-core Xeon E5520 processors, running at 2.27GHz, with hyper-threading enabled, giving 16 virtual cores
- Memory: 24GB of RAM
- Local storage: two 80GB solid state drives, in a RAID-0 configuration
- Operating system: Linux
11.2. Testing Strategy
11.3. Test Results

Figure 11.1.

Figure 11.2.
Appendix A. Revision History
| Revision History | |||
|---|---|---|---|
| Revision 5.2.0-100.400 | 2013-10-31 | ||
| |||
| Revision 5.2.0-100 | Wed 23 Jan 2013 | ||
| |||
| Revision 5.1.2-133 | Wed 18 Jul 2012 | ||
| |||
| Revision 5.1.2-100 | Thu 8 Dec 2011 | ||
| |||