
Configuring Broker Persistence
Red Hat JBoss A-MQ's persistence layer can be tailored for speed and robustness
Copyright © 2011-2014 Red Hat, Inc. and/or its affiliates.
Abstract
Chapter 1. Introduction to Red Hat JBoss A-MQ Persistence
Abstract
Overview
Persistent message stores
- KahaDB message store
- distributed KahaDB message store
- LevelDB message store
- Journaled JDBC adapter
- Non-journaled JDBC adapter
Message cursors
Activating and deactivating persistence
PERSISTENT the broker will not respect the setting. The message will be delivered at-most-once instead of once-and-only-once. This means that persistent messages will not survive broker shutdown.
broker element's persistent attribute.
Table 1.1. Setting a Broker's Persistence
| Value | Description |
|---|---|
true | The broker will use a persistent message store and respect the value of a message's JMSDeliveryMode setting. |
false | The broker will not use a persistent message store and will treat all messages as non-persistent regardless of the value of a message's JMSDeliveryMode setting. |
Example 1.1. Turning Off a Broker's Persistence
<broker persistent="false" ... > ... </broker>
Configuring persistence adapter behavior
persistenceAdapter element or a persistenceFactory element (depending on the kind of adapter you want to use) to the broker's configuration file.
Customizing the store's locker
- if the broker should fail if the store is locked
- how long a broker waits before trying to reacquire a lock
Chapter 2. Using the KahaDB Message Store
Abstract
2.1. Understanding the KahaDB Message Store
Overview
- journal-based storage so that messages can be rapidly written to disk
- allows for the broker to restart quickly
- storing message references in a B-tree index which can be rapidly updated at run time
- full support for JMS transactions
- various strategies to enable recovery after a disorderly shutdown of the broker
Architecture
Figure 2.1. Overview of the KahaDB Message Store
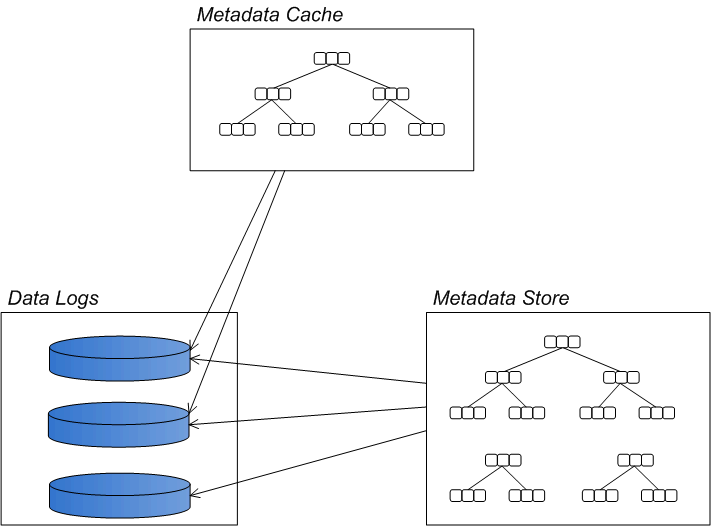
Data logs
Metadata cache
checkpointInterval configuration attribute. For details on how to configure the metadata cache, see Section 2.4, “Optimizing the Metadata Cache”.
Metadata store
db.data, which is periodically updated from the metadata cache.
2.2. Configuring the KahaDB Message Store
Overview
kahaDB element.
Basic configuration
kahaDB element in the persistenceAdapter element of your broker's configuration. The kahaDB element's attributes are used to configure the message store.
directory attribute. This will ensure that the broker will not conflict with other brokers.
activemq-data directory.
Example 2.1. Configuring the KahaDB Message Store
<broker brokerName="broker" persistent="true" ... >
...
<persistenceAdapter>
<kahaDB directory="activemq-data" />
</persistenceAdapter>
...
</broker>Configuration attributes
Table 2.1. Configuration Properties of the KahaDB Message Store
| Attribute | Default Value | Description |
|---|---|---|
directory | activemq-data | Specifies the path to the top-level folder that holds the message store's data files. |
indexWriteBatchSize | 1000 | Specifies the number of B-tree indexes written in a batch. Whenever the number of changed indexes exceeds this value, the metadata cache is written to disk. |
indexCacheSize | 10000 | Specifies the number of B-tree index pages cached in memory. |
enableIndexWriteAsync | false | Specifies if kahaDB will asynchronously write indexes. |
journalMaxFileLength | 32mb | Specifies the maximum size of the data log files. |
enableJournalDiskSyncs | true | Specifies whether every non-transactional journal write is followed by a disk sync. If you want to satisfy the JMS durability requirement, you must also disable concurrent store and dispatch. |
cleanupInterval | 30000 | Specifies the time interval, in milliseconds, between cleaning up data logs that are no longer used. |
checkpointInterval | 5000 | Specifies the time interval, in milliseconds, between writing the metadata cache to disk. |
ignoreMissingJournalfiles | false | Specifies whether the message store ignores any missing journal files while it starts up. If false, the message store raises an exception when it discovers a missing journal file. |
checkForCorruptJournalFiles | false | Specifies whether the message store checks for corrupted journal files on startup and tries to recover them. |
checksumJournalFiles | true | Specifies whether the message store generates a checksum for the journal files. If you want to be able to check for corrupted journals, you must set this property to true. |
archiveDataLogs | false | Specifies if the message store moves spent data logs to the archive directory. |
directoryArchive | null | Specifies the location of the directory to archive data logs. |
databaseLockedWaitDelay | 10000 | Specifies the time delay, in milliseconds, before trying to acquire the database lock in the context of a shared master/slave failover deployment. See section "Shared File System Master/Slave" in "Fault Tolerant Messaging". |
maxAsyncJobs | 10000 | Specifies the size of the task queue used to buffer the broker commands waiting to be written to the journal. The value should be greater than or equal to the number of concurrent message producers. See Section 2.3, “Concurrent Store and Dispatch”. |
concurrentStoreAndDispatchTopics | false | Specifies if the message store dispatches topic messages to interested clients concurrently with message storage. See Section 2.3, “Concurrent Store and Dispatch”. |
concurrentStoreAndDispatchQueues | true | Specifies if the message store dispatches queue messages to clients concurrently with message storage. See Section 2.3, “Concurrent Store and Dispatch”. |
archiveCorruptedIndex | false | Specifies if corrupted indexes are archived when the broker starts up. |
useLock | true | Specifies in the adapter uses file locking. |
2.3. Concurrent Store and Dispatch
Abstract
Overview
Enabling concurrent store and dispatch
kahaDB element's concurrentStoreAndDispatchTopics attribute to true.
Concurrent with slow consumers
Figure 2.2. Concurrent Store and Dispatch—Slow Consumers
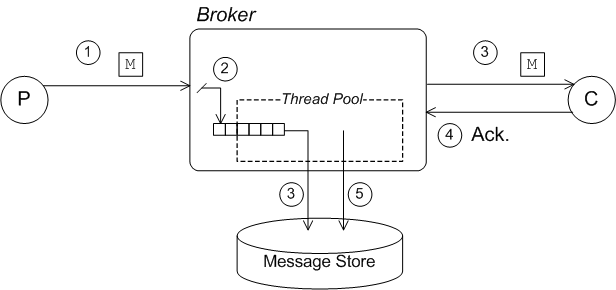
- The producer sends a message,
M, to a destination on the broker. - The broker sends the message,
M, to the persistence layer. Because concurrency is enabled, the message is initially held in a task queue, which is serviced by a pool of threads that are responsible for writing to the journal. - Storing and dispatching are now performed concurrently. The message is dispatched either to one consumer (queue destination) or possibly to multiple destinations (topic consumer). In the meantime, because the attached consumers are slow, we can be sure that the thread pool has already pulled the message off the task queue and written it to the journal.
- The consumer(s) acknowledge receipt of the message.
- The broker asks the persistence layer to remove the message from persistent storage, because delivery is now complete.NoteIn practice, because the KahaDB persistence layer is not able to remove the message from the rolling log files, KahaDB simply logs the fact that delivery of this message is complete. (At some point in the future, when all of the messages in the log file are marked as complete, the entire log file will be deleted.)
Concurrent with fast consumers
Figure 2.3. Concurrent Store and Dispatch—Fast Consumers
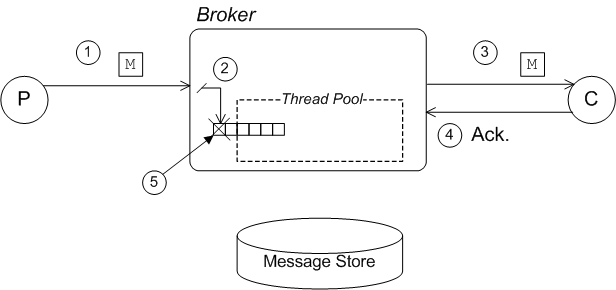
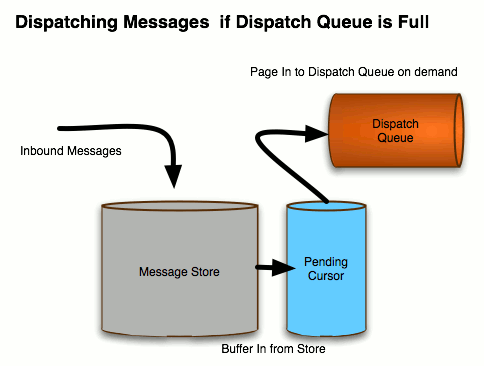
- The producer sends a message,
M, to a destination on the broker. - The broker sends the message,
M, to the persistence layer. Because concurrency is enabled, the message is initially held in a queue, which is serviced by a pool of threads. - Storing and dispatching are now performed concurrently. The message is dispatched to one or more consumers.In the meantime, assuming that the broker is fairly heavily loaded, it is probable that the message has not yet been written to the journal.
- Because the consumers are fast, they rapidly acknowledge receipt of the message.
- When all of the consumer acknowledgments are received, the broker asks the persistence layer to remove the message from persistent storage. But in the current example, the message is still pending and has not been written to the journal. The persistence layer can therefore remove the message just by deleting it from the in-memory task queue.
Disabling concurrent store and dispatch
Example 2.2. KahaDB Configured with Serialized Store and Dispatch
<broker brokerName="broker" persistent="true" useShutdownHook="false">
...
<persistenceAdapter>
<kahaDB directory="activemq-data"
journalMaxFileLength="32mb"
concurrentStoreAndDispatchQueues="false"
concurrentStoreAndDispatchTopics="false"
/>
</persistenceAdapter>
</broker>Serialized store and dispatch
Figure 2.4. Serialized Store and Dispatch
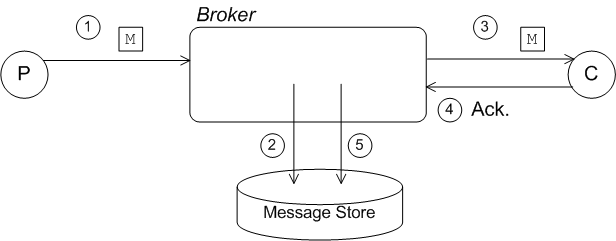
- The producer sends a message,
M, to a destination on the broker. - The broker sends the message,
M, to the persistence layer. Because concurrency is disabled, the message is immediately written to the journal (assumingenableJournalDiskSyncsistrue). - The message is dispatched to one or more consumers.
- The consumers acknowledge receipt of the message.
- When all of the consumer acknowledgments are received, the broker asks the persistence layer to remove the message from persistent storage (in the case of the KahaDB, this means that the persistence layer records in the journal that delivery of this message is now complete).
JMS durability requirements
kahaDB element's enableJournalDiskSyncs attribute to true.
true is the default value for the enableJournalDiskSyncs attribute.
2.4. Optimizing the Metadata Cache
Overview
Figure 2.5. Overview of the Metadata Cache and Store
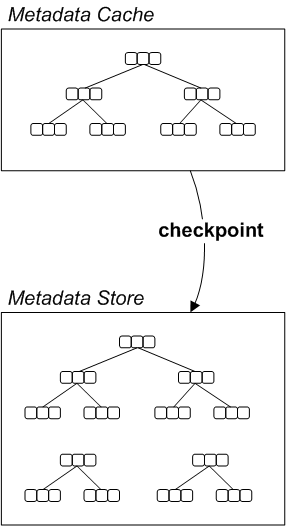
Synchronizing with the metadata store
- Batch threshold—as more and more of the B-tree indexes are changed, and thus inconsistent with the metadata store, you can define a threshold for the number of these dirty indexes. When the number of dirty indexes exceeds the threshold, KahaDB writes the cache to the store. The threshold value is set using the
indexWriteBatchSizeproperty. - Checkpoint interval—irrespective of the current number of dirty indexes, the cache is synchronized with the store at regular time intervals, where the time interval is specified in milliseconds using the
checkpointIntervalproperty.
Setting the cache size
indexCacheSize property, which specifies the size of the cache in units of pages (where one page is 4 KB by default). Generally, the cache should be as large as possible. You can check the size of your metadata store file, db.data, to get some idea of how big the cache needs to be.
Setting the write batch size
indexWriteBatchSize defines the threshold for the number of dirty indexes that are allowed to accumulate, before KahaDB writes the cache to the store. Normally, these batch writes occur between checkpoints.
indexWriteBatchSize to a very large number. In this case, the store would be updated only during checkpoints. The tradeoff here is that there is a risk of losing a relatively large amount of metadata, in the event of a system failure (but the broker should be able to restore the lost metadata when it restarts, by reading the tail of the journal).
2.5. Recovery
Overview
Clean shutdown
- All of the outstanding journal entries.
- All of the cached metadata.
Recovery from disorderly shutdown
db.redo, to reduce the risk of a system failure occurring while updating the metadata store. Before updating the metadata store, KahaDB always saves the redo log, which summarizes the changes that are about to be made to the store. Because the redo log is a small file, it can be written relatively rapidly and is thus less likely to be affected by a system failure. During recovery, KahaDB checks whether the changes recorded in the redo log need to be applied to the metadata.
Forcing recovery by deleting the metadata store
- While the broker is shut down, delete the metadata store,
db.data. - Start the broker.
- The broker now recovers by re-reading the entire journal and replaying all of the events in the journal in order to recreate the missing metadata.
Missing journal files
ignoreMissingJournalfiles property to true.
Checking for corrupted journal files
Example 2.3. Configuration for Journal Validation
<persistenceAdapter>
<kahaDB directory="activemq-data"
journalMaxFileLength="32mb"
checksumJournalFiles="true"
checkForCorruptJournalFiles="true" />
</persistenceAdapter>Chapter 3. Using a Multi KahaDB Persistence Adapter
Abstract
Overview
Configuration
mKahaDB element. The mKahaDB element has a single attribute, directory, that specifies the location where the adapter writes its data stores. This setting is the default value for the directory attribute of the embedded KahaDB message store instances. The individual message stores can override this default setting.
mKahaDB element has a single child filteredPersistenceAdapters. The filteredPersistenceAdapters element contains multiple filteredKahaDB elements that configure the KahaDB message stores that are used by the persistence adapter.
filteredKahaDB element configures one KahaDB message store (except in the case where the perDestination attribute is set to true). The destinations matched to the message store are specified using attributes on the filteredKahaDB element:
queue—specifies the name of queuestopic—specifies the name of topics
filteredKahaDB element is configured using the standard KahaDB persistence adapter configuration. It consists of a kahaDB element wrapped in a persistenceAdapter element. For details on configuring a KahaDB message store see Section 2.2, “Configuring the KahaDB Message Store”.
Wildcard syntax
PRICE.STOCK.NASDAQ.ORCLto publish Oracle Corporation's price on NASDAQPRICE.STOCK.NYSE.IBMto publish IBM's price on the New York Stock Exchange
.separates names in a path*matches any name in a path>recursively matches any destination starting from this name
PRICE.>—any price for any product on any exchangePRICE.STOCK.>—any price for a stock on any exchangePRICE.STOCK.NASDAQ.*—any stock price on NASDAQPRICE.STOCK.*.IBM—any IBM stock price on any exchange
Example
Example 3.1. Multi KahaDB Persistence Adapter Configuration
<persistenceAdapter>
<mKahaDB directory="${activemq.base}/data/kahadb">
<filteredPersistenceAdapters>
<!-- match all queues -->
<filteredKahaDB queue=">">
<persistenceAdapter>
<kahaDB journalMaxFileLength="32mb"/>
</persistenceAdapter>
</filteredKahaDB>
<!-- match all destinations -->
<filteredKahaDB>
<persistenceAdapter>
<kahaDB enableJournalDiskSyncs="false"/>
</persistenceAdapter>
</filteredKahaDB>
</filteredPersistenceAdapters>
</mKahaDB>
</persistenceAdapter>Automatic per-destination persistence adapter
perDestination attribute is set to true on the catch-all filteredKahaDB element (that is, the instance of filteredKahaDB that specifies neither a queue nor a topic attribute), every matching destination gets its own kahaDB instance. For example, the following sample configuration shows how to configure a per-destination persistence adapter:
<broker brokerName="broker" ... >
<persistenceAdapter>
<mKahaDB directory="${activemq.base}/data/kahadb">
<filteredPersistenceAdapters>
<!-- kahaDB per destinations -->
<filteredKahaDB perDestination="true" >
<persistenceAdapter>
<kahaDB journalMaxFileLength="32mb" />
</persistenceAdapter>
</filteredKahaDB>
</filteredPersistenceAdapters>
</mKahaDB>
</persistenceAdapter>
...
</broker>perDestination attribute with either the queue or topic attributes has not been verified to work and could cause runtime errors.
Transactions
Chapter 4. Using the LevelDB Persistence Adapter
Abstract
Overview
- higher persistent throughput
- faster recovery times when a broker restarts
- supports concurrent read access
- no pausing during garbage collection cycles
- uses fewer read IO operations to load stored messages
- supports XA transactions
- checks for duplicate messages
- exposes status via JMX for monitoring
- supports replication
Platform support
Basic configuration
levelDB element in the persistenceAdapter element of your broker's configuration. The levelDB element's attributes are used to configure the message store.
directory attribute. This will ensure that the broker will not conflict with other brokers.
activemq-data directory.
Example 4.1. Configuring the LevelDB Message Store
<broker brokerName="broker" persistent="true" ... >
...
<persistenceAdapter>
<levelDB directory="activemq-data" />
</persistenceAdapter>
...
</broker>Configuration attributes
Table 4.1. Configuration Properties of the LevelDB Message Store—standard LevelDB attributes
Table 4.2. Configuration Properties of the LevelDB Message Store—pluggable storage locker attributes
Chapter 5. Using the Replicated LevelDB Persistence Adapter
Abstract
Overview
replicas="3" has a quorum size of (3/2)+1=2. In this case, the master stores the update locally, then waits for at least one slave to store the update before it reports success.
Deployment tips
- Clients should use the Failover Transport to connect to the broker nodes in the replication cluster; for example, using a URL like this:
failover:(tcp://broker1:61616,tcp://broker2:61616,tcp://broker3:61616)
- To enable highly available ZooKeeper service, run at least three ZooKeeper server nodes.NoteAvoid overcommitting ZooKeeper servers. An overworked ZooKeeper server might infer that a live broker replication node has gone offline due to delayed processing of keep-alive messages.For details on setting up and running a distributed cluster of Apache ZooKeeper servers, see the ZooKeeper Getting Started document.
- To enable highly available ActiveMQ service, run at least three replicated broker nodes.
Basic configuration
replicatedLevelDB element in the persistenceAdapter element of your broker's configuration, and use the replicatedLevelDB element's attributes to configure the message store.
brokerName attribute.
activemq-data directory.
Example 5.1. Configuring the Replicated LevelDB Message Store
<broker brokerName="broker" persistent="true" ... >
...
<persistenceAdapter>
<replicatedLevelDB
directory="activemq-data" />
replicas="3"
bind="tcp://0.0.0.0;0"
zkAddress="zoo1.example.org:2181,zoo2.example.org:2181,zoo3.example.org:2181"
zkPassword="password"
zkPath="/activemq/leveldb-stores"
/>
</persistenceAdapter>
...
</broker>Configuration attributes
Table 5.1. Configuration Properties of the Replicated LevelDB Message Store—attributes which must be identical on all broker nodes in a replication cluster
zkSessionTimeout to detect when it has been disconnected from the ZooKeeper server due to a network failure. When set to 2s, the replicated broker nodes will detect a disconnect within two seconds of a network failure. Once the disconnect is detected, the master broker gives up the master role, and the slave brokers begin the election process. The lower the timeout value, the faster the process to select a new master. However, setting the timeout value too low can result in false positives, causing masters to switch when no disconnect has occurred.
Table 5.2. Configuration Properties of the Replicated LevelDB Message Store—attributes which can be unique for each broker node in a replication cluster
Chapter 6. Using JDBC to Connect to a Database Store
Abstract
6.1. Basics of Using the JDBC Persistence Adapter
Overview
Supported databases
- MySQL
- Oracle
- PostgreSQL
- Microsoft SQL Server
Specifying the type of JDBC store to use
- JDBC store:The regular JDBC store is specified using the
jdbcPersistenceAdapterelement inside thepersistenceAdapterelement. For more details see Section 6.2, “Using the Plain JDBC Adapter”. - Journaled JDBC store:The journaled JDBC store is specified using the
journaledJDBCelement inside thepersistenceFactoryelement. For more details see Section 6.3, “Using JDBC with the High Performance Journal”.WarningThe journaled JDBC store is incompatible with the JDBC master/slave failover pattern—see Fault Tolerant Messaging.
Prerequisites
- The
org.apache.servicemix.bundles.commons-dbcpbundle. You can install this bundle into a standalone container using the following console command:osgi:install mvn:org.apache.servicemix.bundles/org.apache.servicemix.bundles.commons-dbcp/1.4_3
- The JDBC driver for the database being used.NoteDepending on the database being used, you may need to wrap the driver in an OSGi bundle by using the wrap: URI prefix when adding it to the container.
Configuring your JDBC driver
JDBC configuration for Apache Derby
Example 6.1. Configuration for the Apache Derby Database
<beans ...>
<broker xmlns="http://activemq.apache.org/schema/core"
brokerName="localhost">
...
<persistenceAdapter>
<jdbcPersistenceAdapter
dataDirectory="${activemq.base}/data"
dataSource="#derby-ds"/>
</persistenceAdapter>
...
</broker>
<!-- Embedded Derby DataSource Sample Setup -->
<bean id="derby-ds" class="org.apache.derby.jdbc.EmbeddedDataSource">
<property name="databaseName" value="derbydb"/>
<property name="createDatabase" value="create"/>
</bean>
</beans>JDBC configuration for Oracle
bean element that configures the JDBC driver.
Example 6.2. Configuration for the Oracle JDBC Driver
<beans ... >
<broker xmlns="http://activemq.apache.org/schema/core"
brokerName="localhost">
...
<persistenceAdapter>
<jdbcPersistenceAdapter
dataDirectory="${activemq.base}/data"
dataSource="#oracle-ds"/>
</persistenceAdapter>
...
</broker>
<!-- Oracle DataSource Sample Setup -->
<bean id="oracle-ds"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@localhost:1521:AMQDB"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
<property name="maxActive" value="200"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
</beans>bean element. The id attribute specifies the name by which you will refer to the driver when configuring the JDBC persistence adapter. The class attribute specifies the class that implements the data source used to interface with the JDBC driver. The destroy-method attribute specifies the name of the method to call when the JDBC driver is shutdown.
bean element, the JDBC driver configuration includes a number of property elements. Each property element specifies a property required by the JDBC driver. For information about the configurable properties refer to your JDBC driver's documentation.
6.2. Using the Plain JDBC Adapter
Overview
Example
Example 6.3. Configuring Red Hat JBoss A-MQ to use the Plain JDBC Persistence Adapter
<beans ... > <broker ...> ... 1 <persistenceAdapter> 2 <jdbcPersistenceAdapter dataSource="#derby-ds" /> </persistenceAdapter> ... <broker> ... 3<bean id="derby-ds" class="org.apache.derby.jdbc.EmbeddedDataSource"> <property name="databaseName" value="derbydb"/> <property name="createDatabase" value="create"/> </bean>
- 1
- The
persistenceAdapterelement wraps the configuration for the JDBC persistence adapter. - 2
- The
jdbcPersistenceAdapterelement specifies that the broker will use the plain JDBC persistence adapter and that the JDBC driver's configuration is specified in abeanelement with the ID,derby-ds. - 3
- The
beanelement specified the configuration for the Derby JDBC driver.
Configuration
Table 6.1. Attributes for Configuring the Plain JDBC Persistence Adapter
| Attribute | Default Value | Description |
|---|---|---|
adapter | Specifies the strategy to use when accessing a non-supported database. For more information see the section called “Using generic JDBC providers”. | |
cleanupPeriod | 300000 | Specifies, in milliseconds, the interval at which acknowledged messages are deleted. |
createTablesOnStartup | true | Specifies whether or not new database tables are created when the broker starts. If the database tables already exist, the existing tables are reused. |
dataDirectory | activemq-data | Specifies the directory into which the default Derby database writes its files. |
dataSource | #derby | Specifies the id of the Spring bean storing the JDBC driver's configuration. For more information see the section called “Configuring your JDBC driver”. |
transactionIsolation | Connection.TRANSACTION_READ_UNCOMMITTED | Specifies the required transaction isolation level. For allowed values, see java.sql.Connection. |
useLock | true | Specifies in the adapter uses file locking. |
lockKeepAlivePeriod | 30000 | Specifies the time period, in milliseconds, at which the current time is saved in the locker table to ensure that the lock does not timeout. 0 specifies unlimited time. |
6.3. Using JDBC with the High Performance Journal
Overview
Prerequisites
activeio-core-3.1.4.jar bundle is installed in the container.
InstallDir/extras folder or can be downloaded from Maven at http://mvnrepository.com/artifact/org.apache.activemq/activeio-core/3.1.4.
Example
Example 6.4. Configuring Red Hat JBoss A-MQ to use the Journaled JDBC Persistence Adapter
<beans ... >
<broker ...>
...
1 <persistenceFactory>
2 <journalPersistenceAdapterFactory journalLogFiles="5" dataDirectory="${data}/kahadb" dataSource="#mysql-ds" useDatabaseLock="true" useDedicatedTaskRunner="false />
</persistenceFactory>
...
<broker>
...
3<bean id="mysql-ds"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost/activemq?relaxAutoCommit=true"/>
<property name="username" value="activemq"/>
<property name="password" value="activemq"/>
<property name="poolPreparedStatements" value="true"/>
</bean>- 1
- The
persistenceFactoryelement wraps the configuration for the JDBC persistence adapter. - 2
- The
journaledJDBCelement specifies that the broker will use the JDBC persistence adapter with the high performance journal. The element's attributes configure the following properties:- The journal will span five log files.
- The configuration for the JDBC driver is specified in a
beanelement with the ID,mysql-ds. - The data for the journal will be stored in
${data}/kahadb.
- 3
- The
beanelement specified the configuration for the MySQL JDBC driver.
Configuration
Table 6.2. Attributes for Configuring the Journaled JDBC Persistence Adapter
| Attribute | Default Value | Description |
|---|---|---|
adapter | Specifies the strategy to use when accessing a non-supported database. For more information see the section called “Using generic JDBC providers”. | |
createTablesOnStartup | true | Specifies whether or not new database tables are created when the broker starts. If the database tables already exist, the existing tables are reused. |
dataDirectory | activemq-data | Specifies the directory into which the default Derby database writes its files. |
dataSource | #derby | Specifies the id of the Spring bean storing the JDBC driver's configuration. For more information see the section called “Configuring your JDBC driver”. |
journalArchiveDirectory | Specifies the directory used to store archived journal log files. | |
journalLogFiles | 2 | Specifies the number of log files to use for storing the journal. |
journalLogFileSize | 20MB | Specifies the size for a journal's log file. |
journalThreadPriority | 10 | Specifies the thread priority of the thread used for journaling. |
useJournal | true | Specifies whether or not to use the journal. |
useLock | true | Specifies in the adapter uses file locking. |
lockKeepAlivePeriod | 30000 | Specifies the time period, in milliseconds, at which the current time is saved in the locker table to ensure that the lock does not timeout. 0 specifies unlimited time. |
6.4. Customizing the JDBC Persistence Adapter
Overview
Customizing the SQL statements used by the adapter
statements element to the JDBC persistence adapter configuration. Example 6.5, “Fine Tuning the Database Schema” shows a configuration snippet that specifies that long strings are going to be stored as VARCHAR(128).
Example 6.5. Fine Tuning the Database Schema
<persistenceAdapter>
<jdbcPersistenceAdapter ... >
<statements>
<statements stringIdDataType ="VARCHAR(128)"/>
</statements>
</jdbcPersistenceAdapter>
</persistenceAdapter>statements element is a wrapper for one or more nested statements elements. Each nested statements element specifies a single configuration statement. Table 6.3, “Statements for Configuring the SQL Statements Used by the JDBC Persistence Adapter” describes the configurable properties.
Table 6.3. Statements for Configuring the SQL Statements Used by the JDBC Persistence Adapter
Customizing SQL statements for unsupported databases
addMessageStatementupdateMessageStatementremoveMessageStatementfindMessageSequenceIdStatementfindMessageStatementfindAllMessagesStatementfindLastSequenceIdInMsgsStatementfindLastSequenceIdInAcksStatementcreateDurableSubStatementfindDurableSubStatementfindAllDurableSubsStatementupdateLastAckOfDurableSubStatementdeleteSubscriptionStatementfindAllDurableSubMessagesStatementfindDurableSubMessagesStatementfindAllDestinationsStatementremoveAllMessagesStatementremoveAllSubscriptionsStatementdeleteOldMessagesStatementlockCreateStatementlockUpdateStatementnextDurableSubscriberMessageStatementdurableSubscriberMessageCountStatementlastAckedDurableSubscriberMessageStatementdestinationMessageCountStatementfindNextMessageStatementcreateSchemaStatementsdropSchemaStatements
Using generic JDBC providers
adapter attribute to reference the bean ID of the relevant adapter. The following adapter types are supported:
org.activemq.store.jdbc.adapter.BlobJDBCAdapterorg.activemq.store.jdbc.adapter.BytesJDBCAdapterorg.activemq.store.jdbc.adapter.DefaultJDBCAdapterorg.activemq.store.jdbc.adapter.ImageJDBCAdapter
Example 6.6. Configuring a Generic JDBC Provider
<broker persistent="true" ... >
...
<persistenceAdapter>
<jdbcPersistenceAdapter adapter="#blobAdapter" ... />
</persistenceAdapter>
<bean id="blobAdapter"
class="org.activemq.store.jdbc.adapter.BlobJDBCAdapter"/>
...
</broker>6.5. Tutorial: JDBC Persistence
Overview
Prerequisites
- You have already installed a MySQL database server (following the instructions in the MySQL Installation Guide, including the post installation set-up and testing).
- The MySQL database server is already running.
- You have root access to the MySQL database server (that is, you have access to the
rootuser account in MySQL, which you can use to administer the database). - You have access to the Internet (so that you can install the MySQL JDBC driver bundle and the Apache Commons data source bundle, both of which must be downloaded from the Maven Central repository).
Steps to configure JDBC persistence with MySQL
- Log into the MySQL database using the
mysqlclient shell. Enter the following command to log on as therootuser:mysql -u root -p
You will be prompted to enter therootuser password (alternatively, if the root user has no associated password, you can omit the-poption). - Add the new user account,
amq, to MySQL with password,amqPass, by entering the following command at themysqlshell prompt:mysql> CREATE USER 'amq'@'localhost' IDENTIFIED BY 'amqPass';
If you would rather create theamquser without any password, you can omit theIDENTIFIED BYclause, as follows:mysql> CREATE USER 'amq'@'localhost';
NoteThis example assumes you are invoking themysqlshell from the same host where the MySQL database server is running. If you are logging on to the MySQL database remotely, however, you should replacelocalhostin the preceding command (and subsequent commands) by the name of the host where you are invoking themysqlshell. - Grant privileges to the
amquser, enabling it to access theactivemqdatabase instance (which has yet to be created). Enter the followingGRANTcommand at themysqlshell prompt:mysql> GRANT ALL PRIVILEGES ON activemq.* TO 'amq'@'localhost' WITH GRANT OPTION;
- Create the
activemqdatabase instance, by entering the following command:mysql> CREATE DATABASE activemq;
There is no need to create any database tables at this point. The broker's JDBC persistence will automatically create the necessary tables when it starts up for the first time. - Start the JBoss A-MQ standalone container, with its default (unchanged) configuration:
cd InstallDir/bin ./amq
- Install the MySQL JDBC driver into the container, as follows:
JBossA-MQ:karaf@root> osgi:install mvn:mysql/mysql-connector-java/5.1.27
- Install the Apache Commons data source bundle, as follows:
JBossA-MQ:karaf@root> osgi:install mvn:org.apache.servicemix.bundles/org.apache.servicemix.bundles.commons-dbcp/1.4_3
- Stop the JBoss A-MQ container (for example, by entering the
shutdowncommand at the console). Now configure the broker to use JDBC persistence by editing theInstallDir/etc/activemq.xmlfile. Modify thebroker/persistenceAdapterelement and add a newbeanelement (for the MySQL data source) as follows:<beans ...> ... <bean id="mysql-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"> <property name="driverClassName" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost/activemq?relaxAutoCommit=true"/> <property name="username" value="amq"/> <property name="password" value="amqPass"/> <property name="poolPreparedStatements" value="true"/> </bean> <broker ...> ... <persistenceAdapter> <jdbcPersistenceAdapter dataSource="#mysql-ds"/> </persistenceAdapter> ... </broker> </beans>Where the bean with the ID,mysql-ds, creates a data source instance for connecting to the MySQL database through the JDBC protocol. Note particularly the following property settings for this bean:- url
- Is used to specify a JDBC URL in the following format:
jdbc:mysql://Hostame/DBName[?Property=Value]
WhereHostnameis the host where the MySQL database server is running;DBNameis the name of the database instance used to store the broker data (which isactivemq, in this example); and you can optionally set property values,Property=Value, after the?character. - password
- If you specified a password for the
amquser when you created it, specify the password here. Otherwise, if no password was defined, specify a blank string,"".
- Restart the JBoss A-MQ container, as follows:
./amq
As the broker initializes, it automatically creates new tables in theactivemqdatabase instance to hold the broker data (this is the default behavior). - To verify that the requisite tables have been created in the
activemqdatabase instance, enter the following commands at themysqlclient shell:mysql> USE activemq; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> SHOW TABLES; +--------------------+ | Tables_in_activemq | +--------------------+ | ACTIVEMQ_ACKS | | ACTIVEMQ_LOCK | | ACTIVEMQ_MSGS | +--------------------+ 3 rows in set (0.00 sec) mysql> describe activemq_lock; +-------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------------+--------------+------+-----+---------+-------+ | ID | bigint(20) | NO | PRI | NULL | | | TIME | bigint(20) | YES | | NULL | | | BROKER_NAME | varchar(250) | YES | | NULL | | +-------------+--------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) mysql> describe activemq_msgs -> ; +------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+--------------+------+-----+---------+-------+ | ID | bigint(20) | NO | PRI | NULL | | | CONTAINER | varchar(250) | YES | MUL | NULL | | | MSGID_PROD | varchar(250) | YES | MUL | NULL | | | MSGID_SEQ | bigint(20) | YES | | NULL | | | EXPIRATION | bigint(20) | YES | MUL | NULL | | | MSG | longblob | YES | | NULL | | | PRIORITY | bigint(20) | YES | MUL | NULL | | | XID | varchar(250) | YES | MUL | NULL | | +------------+--------------+------+-----+---------+-------+ 8 rows in set (0.00 sec)
Chapter 7. Message Cursors
Abstract
- Store-based cursors are used by default to handle persistent messages.
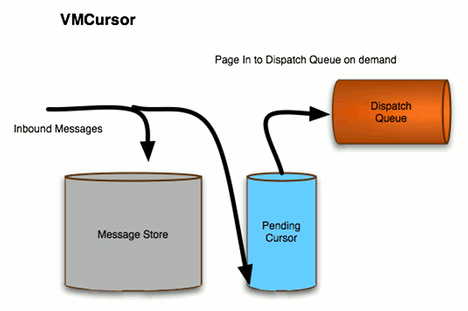
- VM cursors are very fast, but cannot handle slow message consumers.
- File-based cursors are used by default to handle non-persistent messages. They are useful when the message store is slow and message consumers are relatively fast.
7.1. Types of Cursors
Store-based cursors
Figure 7.1. Store-based Cursors for a Fast Consumer
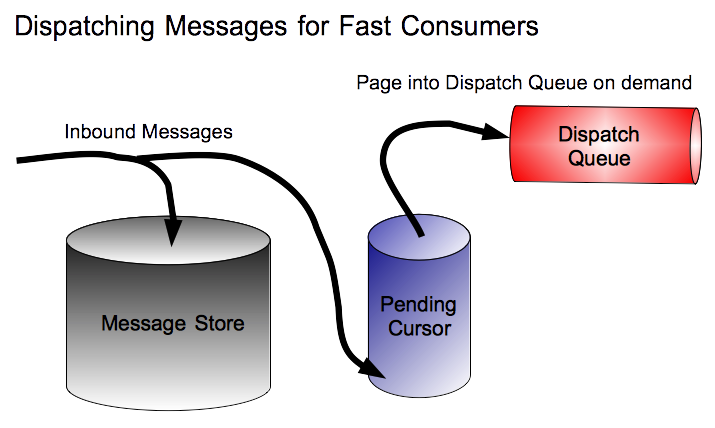
Figure 7.2. Store-based Cursors for a Slow Consumer
VM cursors
Figure 7.3. VM Cursors
File-based cursors
Figure 7.4. File-based Cursors
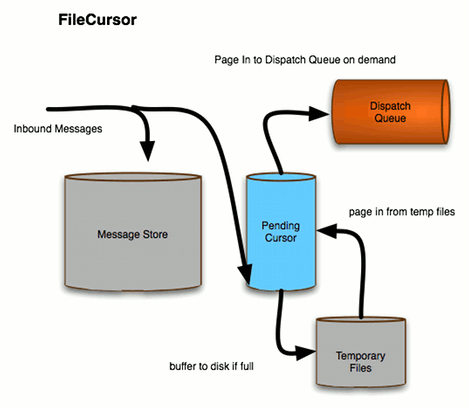
7.2. Configuring the Type of Cursor Used by a Destination
Overview
destinationPolicy element. The destinationPolicy element is a wrapper for a policyMap element. The policyMap element is a wrapper for a policyEntries element. The policyEntries element is a wrapper for one or more policyEntry elements.
policyEntry element. The configuration elements used to specify the type of destination you are configuring. Topics use cursors for both durable subscribers and transient subscribers, so it uses two sets of configuration elements. Queues only a single cursor and only require a single set of configuration elements.
Configuring topics
PendingDurableSubscriberMessageStoragePolicy child element to the topic's policyEntry element. Table 7.1, “Elements for Configuring the Type of Cursor to Use for Durable Subscribers” describes the possible children of PendingDurableSubscriberMessageStoragePolicy.
Table 7.1. Elements for Configuring the Type of Cursor to Use for Durable Subscribers
| Element | Description |
|---|---|
storeDurableSubscriberCursor | Specifies that store-based cursors will be used. See the section called “Store-based cursors” for more information. |
vmDurableCursor | Specifies that VM cursors will be used. See the section called “VM cursors” for more information. |
fileDurableSubscriberCursor | Specifies that file-based cursors will be used—only suitable for non-persistent messages. See the section called “File-based cursors” for more information. |
pendingSubscriberPolicy child element to the topic's policyEntry element. Table 7.2, “Elements for Configuring the Type of Cursor to Use for Transient Subscribers” describes the possible children of pendingSubscriberPolicy.
Table 7.2. Elements for Configuring the Type of Cursor to Use for Transient Subscribers
| Element | Description |
|---|---|
| Unspecified | Default policy is to use store-based cursors. See the section called “Store-based cursors” for more information. |
vmCursor | Specifies the VM cursors will be used. See the section called “VM cursors” for more information. |
fileCursor | Specifies that file-based cursors will be used. See the section called “File-based cursors” for more information. |
Example 7.1. Configuring a Topic's Cursor Usage
<beans ... >
<broker ... >
...
<destinationPolicy>
<policyMap>
<policyEntries>
<policyEntry topic="com.fusesource.>" >
...
<pendingSubscriberPolicy>
<vmCursor />
</pendingSubscriberPolicy>
<pendingDurableSubscriberPolicy>
<storeDurableSubscriberCursor />
</pendingDurableSubscriberPolicy>
...
</policyEntry>
...
</policyEntries>
</policyMap>
</destinationPolicy>
...
</broker>
...
</beans>Configuring queues
pendingQueuePolicy element to the queue's policyEntry element. Table 7.3, “Elements for Configuring the Type of Cursor to Use for a Queue” describes the possible children elements of the pendingQueuePolicy element.
Table 7.3. Elements for Configuring the Type of Cursor to Use for a Queue
| Element | Description |
|---|---|
storeCursor | Specifies that store-based cursors will be used. See the section called “Store-based cursors” for more information. |
vmQueueCursor | Specifies the VM cursors will be used. See the section called “VM cursors” for more information. |
fileQueueCursor | Specifies that file-based cursors will be used. See the section called “File-based cursors” for more information. |
Example 7.2. Configuring a Queue's Cursor Usage
<beans ... >
<broker ... >
...
<destinationPolicy>
<policyMap>
<policyEntries>
<policyEntry queue="com.fusesource.>" >
...
<pendingQueuePolicy>
<vmQueueCursor />
</pendingQueuePolicy>
...
</policyEntry>
...
</policyEntries>
</policyMap>
</destinationPolicy>
...
</broker>
...
</beans>Chapter 8. Message Store Lockers
Abstract
8.1. Locker Basics
Overview
- shared file locker—used by KahaDB and LevelDB stores
- database locker—used by the JDBC storeNoteJBoss A-MQ also provides a leased database locker that can be in cases where the brokers may periodically lose their connection to the message store.
Configuring a persistence adapter's locker
locker element as a child to the adapter's configuration element as shown in Example 8.1, “Configuring a Message Store Locker”.
Example 8.1. Configuring a Message Store Locker
<persistenceAdapter>
<kahaDB directory = "target/activemq-data">
<locker>
...
</locker>
</kahaDB>
</persistenceAdapter>Standard locker configuration properties
Table 8.1. Common Locker Properties
8.2. Using the Provided Lockers
- shared file locker—used by file-based message stores like KahaDB and LevelDB
- database locker—used as the default for JDBC message stores
- lease database locker—used as an alternative locker for JDBC message stores in scenarios where brokers have inconsistent connections to the message store
8.2.2. Database Locker
Overview
- intermittent database connectivity
- database failover
Configuration
database-locker element.
Example 8.3. Configuring a Database Locker
<persistenceAdapter>
<jdbcPersistenceAdapter dataDirectory="${activemq.data}" dataSource="#mysql-ds">
<locker>
<database-locker lockAcquireSleepInterval="5000"/>
</locker>
</jdbcPersistenceAdapter>
</persistenceAdapter>Intermittent database connectivity
Database failover
8.2.3. Lease Database Locker
Overview
lockKeepAlivePeriod attribute. After the initial period, the lock is renewed for the period specified by the locker's lockAcquireSleepInterval attribute.
Configuration
lease-database-locker element.
Example 8.4. Configuring a Lease Database Locker
<ioExceptionHandler>
<jDBCIOExceptionHandler/>
</ioExceptionHandler>
<persistenceAdapter>
<jdbcPersistenceAdapter dataDirectory="${activemq.data}" dataSource="#mysql-ds" lockKeepAlivePeriod="5000">
<locker>
<lease-database-locker lockAcquireSleepInterval="10000"/>
</locker>
</jdbcPersistenceAdapter>
</persistenceAdapter>jDBCIOExceptionHandler exception handler
jDBCIOExceptionHandler exception handler to the configuration. The jDBCIOExceptionHandler will pause and resume the transport connectors on any I/O exception related to database access.
Dealing with unsynchronized system clocks
maxAllowableDiffFromDBTime to specify the number of milliseconds by which a broker's system clock can differ from the database's before the locker automatically adds an adjustment. The default setting is zero which deactivates the adjustments.
Example 8.5. Configuring a Lease Database Locker to Adjust for Non-synchronized System Clocks
<ioExceptionHandler>
<jDBCIOExceptionHandler/>
</ioExceptionHandler>
<persistenceAdapter>
<jdbcPersistenceAdapter ... >
<locker>
<lease-database-locker maxAllowableDiffFromDBTime="1000"/>
</locker>
</jdbcPersistenceAdapter>
</persistenceAdapter>8.3. Using Custom Lockers
Overview
Locker interface. They are attached to the persistence adapter as a spring bean in the locker element.
Interface
org.apache.activemq.broker.Locker interface. Implementing the Locker interface involves implementing seven methods:
boolean keepAlive()
throws IOException;Used by the lock's timer to ensure that the lock is still active. If this returns false, the broker is shutdown.void setLockAcquireSleepInterval(long lockAcquireSleepInterval);Sets the delay, in milliseconds, between attempts to acquire the lock.lockAcquireSleepIntervalis typically supplied through the locker's XML configuration.public void setName(String name);Sets the name of the lock.public void setFailIfLocked(boolean failIfLocked);Sets the property that determines if the broker should fail if it cannot acquire the lock at start-up.failIfLockedis typically supplied through the locker's XML configuration.public void configure(PersistenceAdapter persistenceAdapter)
throws IOException;Allows the locker to access the persistence adapter's configuration. This can be used to obtain the location of the message store.void start();Executed when the locker is initialized by the broker. This is where the bulk of the locker's implementation logic should be placed.void stop();Executed when the broker is shutting down. This method is useful for cleaning up any resources and ensuring that all of the locks are released before the broker is completely shutdown.
Using AbstractLocker
org.apache.activemq.broker.AbstractLocker, that serves as the base for all of the provided lockers. It is recommended that all custom locker implementations also extand the AbstractLocker class instead of implementing the plain Locker interface.
AbstractLocker provides default implementations for the following methods:
keepAlive()—returnstruesetLockAcquireSleepInterval()—sets the parameter to the value of the locker beans'lockAcquireSleepIntervalif provided or to10000if the parameter is not providedsetName()setFailIfLocked()—sets the parameter to the value of the locker beans'failIfLockedif provided or tofalseif the parameter is not providedstart()—starts the locker after calling two additional methodsImportantThis method should not be overridden.stop()—stops the locker and adds a method that is called before the locker is shutdown and one that is called after the locker is shutdownImportantThis method should not be overridden.
AbstractLocker adds two methods that must be implemented:
void doStart()
throws Exception;Executed as the locker is started. This is where most of the locking logic is implemented.void doStop(ServiceStopper stopper)
throws Exception;Executed as the locker is stopped. This is where locks are released and resources are cleaned up.
AbstractLocker adds two methods that can be implemented to provide additional set up and clean up:
void preStart()
throws Exception;Executed before the locker is started. This method can be used to initialize resources needed by the lock. It can also be used to perform any other actions that need to be performed before the locks are created.void doStop(ServiceStopper stopper)
throws Exception;Executed after the locker is stopped. This method can be used to clean up any resources that are left over after the locker is stopped.
Configuration
locker element as shown in Example 8.6, “Adding a Custom Locker to a Persistence Adapter”.
Example 8.6. Adding a Custom Locker to a Persistence Adapter
<persistenceAdapter>
<kahaDB directory = "target/activemq-data">
<locker>
<bean class="my.custom.LockerImpl">
<property name="lockAcquireSleepInterval" value="5000" />
...
</bean
</locker>
</kahaDB>
</persistenceAdapter>Index
A
- AbstractLocker, Using AbstractLocker
B
- broker element, Activating and deactivating persistence
- persistent attribute, Activating and deactivating persistence
C
- configuration
- turning persistence on/off, Activating and deactivating persistence
- cursors
- file-based, File-based cursors
- store-based, Store-based cursors
- VM, VM cursors
D
- database-locker, Configuration
- destinationPolicy, Overview
- durable subscribers
- configuring cursors, Configuring topics
- using file-based cursors, Configuring topics
- using VM cursors, Configuring topics
F
- failIfLocked, Standard locker configuration properties
- fileCursor, Configuring topics
- fileDurableSubscriberCursor, Configuring topics
- fileQueueCursor, Configuring queues
- filteredKahaDB, Configuration
- filteredPersistenceAdapters, Configuration
J
- JDBC
- using generic providers, Using generic JDBC providers
- JDBC message store
- default locker, Database Locker
- jdbcPersistenceAdapter, Configuration
- adapter attribute, Configuration, Using generic JDBC providers
- cleanupPeriod attribute, Configuration
- createTablesOnStartup attribute, Configuration
- dataDirectory attribute, Configuration
- dataSource attribute, Configuration
- journaled JDBC message store
- default locker, Database Locker
- journaledJDBC, Configuration
- adapter attribute, Configuration, Using generic JDBC providers
- createTablesOnStartup attribute, Configuration
- dataDirectory attribute, Configuration
- dataSource attribute, Configuration
- journalArchiveDirectory attribute, Configuration
- journalLogFiles attribute, Configuration
- journalLogFileSize attribute, Configuration
- journalThreadPriority attribute, Configuration
- useJournal attribute, Configuration
K
- kahaDB element, Basic configuration
- archiveCorruptedIndex attribute, Configuration attributes
- archiveDataLogs attribute, Configuration attributes
- checkForCorruptJournalFiles attribute, Configuration attributes
- checkpointInterval attribute, Configuration attributes
- checksumJournalFiles attribute, Configuration attributes
- cleanupInterval attribute, Configuration attributes
- concurrentStoreAndDispatchQueues attribute, Configuration attributes
- concurrentStoreAndDispatchTopics attribute, Configuration attributes
- databaseLockedWaitDelay attribute, Configuration attributes
- directory attribute, Configuration attributes
- directoryArchive attribute, Configuration attributes
- enableIndexWriteAsync attribute, Configuration attributes
- enableJournalDiskSyncs attribute, Configuration attributes
- ignoreMissingJournalfiles attribute, Configuration attributes
- indexCacheSize attribute, Configuration attributes
- indexWriteBatchSize attribute, Configuration attributes
- journalMaxFileLength attribute, Configuration attributes
- maxAsyncJobs attribute, Configuration attributes
- KahaDB message store
- architecture, Architecture
- basic configuration, Basic configuration
- configuration attributes, Configuration attributes
- data logs, Data logs
- default locker, Shared File Locker
- metadata cache, Metadata cache
- metadata store, Metadata store
- multi, Using a Multi KahaDB Persistence Adapter
L
- lease-database-locker, Configuration
- levelDB element, Basic configuration
- directory attribute, Basic configuration, Configuration attributes
- failIfLocked attribute, Configuration attributes
- indexBlockRestartInterval attribute, Configuration attributes
- indexBlockSize attribute, Configuration attributes
- indexCacheSize attribute, Configuration attributes
- indexCompression attribute, Configuration attributes
- indexFactory attribute, Configuration attributes
- indexMaxOpenFiles attribute, Configuration attributes
- indexWriteBufferSize attribute, Configuration attributes
- logCompression attribute, Configuration attributes
- logSize attribute, Configuration attributes
- paranoidChecks attribute, Configuration attributes
- readThreads attribute, Configuration attributes
- sync attribute, Configuration attributes
- useLock attribute, Configuration attributes
- verifyChecksums attribute, Configuration attributes
- LevelDB message store
- basic configuration, Basic configuration
- configuration attributes, Configuration attributes
- default locker, Shared File Locker
- platform support, Platform support
- lockAcquireSleepInterval, Standard locker configuration properties
- locker, Configuring a persistence adapter's locker, Configuration
- Locker, Interface
- locker configuration, Standard locker configuration properties
M
- maxAllowableDiffFromDBTime, Dealing with unsynchronized system clocks
- message store
- locker configuration, Configuring a persistence adapter's locker
- mKahaDB, Configuration
- multi Kahadb persistence adapter
- transactions, Transactions
P
- PendingDurableSubscriberMessageStoragePolicy, Configuring topics
- pendingQueuePolicy, Configuring queues
- pendingSubscriberPolicy, Configuring topics
- persistenceAdapter, Configuring persistence adapter behavior
- persistenceFactory, Configuring persistence adapter behavior
- policyEntries, Overview
- policyEntry, Overview
- policyMap, Overview
R
- Replicated LevelDB message store
- configuration attributes, Configuration attributes
- replicatedLevelDB element, Basic configuration
- bind attribute, Configuration attributes
- directory attribute, Basic configuration
- hostname attribute, Configuration attributes
- replicas attribute, Configuration attributes
- securityToken attribute, Configuration attributes
- sync attribute, Configuration attributes
- zkAddress attribute, Configuration attributes
- zkPassword attribute, Configuration attributes
- zkPath attribute, Configuration attributes
- zkSessionTimeout attribute, Configuration attributes
- replicatedLevelDB message store
- replicatedLevelDB basic configuration, Basic configuration
S
- shared-file-locker, Configuration
- SQL data types, Customizing the SQL statements used by the adapter
- statements, Customizing the SQL statements used by the adapter
- binaryDataType attribute, Customizing the SQL statements used by the adapter
- containerNameDataType attribute, Customizing the SQL statements used by the adapter
- durableSubAcksTableName attribute, Customizing the SQL statements used by the adapter
- lockTableName attribute, Customizing the SQL statements used by the adapter
- longDataType attribute, Customizing the SQL statements used by the adapter
- messageTableName attribute, Customizing the SQL statements used by the adapter
- msgIdDataType attribute, Customizing the SQL statements used by the adapter
- sequenceDataType attribute, Customizing the SQL statements used by the adapter
- stringIdDataType attribute, Customizing the SQL statements used by the adapter
- tablePrefix attribute, Customizing the SQL statements used by the adapter
T
- transactions
- multi destination, Transactions
- multi Kahadb persistence adapter, Transactions
- multiple journals, Transactions
- transient subscribers
- configuring cursors, Configuring topics
- using file-based cursors, Configuring topics
- using VM cursors, Configuring topics
V
- vmCursor, Configuring topics
- vmDurableCursor, Configuring topics
- vmQueueCursor, Configuring queues
Legal Notice
Trademark Disclaimer
Legal Notice
Third Party Acknowledgements
- JLine (http://jline.sourceforge.net) jline:jline:jar:1.0License: BSD (LICENSE.txt) - Copyright (c) 2002-2006, Marc Prud'hommeaux
mwp1@cornell.eduAll rights reserved.Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
- Neither the name of JLine nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - Stax2 API (http://woodstox.codehaus.org/StAX2) org.codehaus.woodstox:stax2-api:jar:3.1.1License: The BSD License (http://www.opensource.org/licenses/bsd-license.php)Copyright (c) <YEAR>, <OWNER> All rights reserved.Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - jibx-run - JiBX runtime (http://www.jibx.org/main-reactor/jibx-run) org.jibx:jibx-run:bundle:1.2.3License: BSD (http://jibx.sourceforge.net/jibx-license.html) Copyright (c) 2003-2010, Dennis M. Sosnoski.All rights reserved.Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
- Neither the name of JiBX nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - JavaAssist (http://www.jboss.org/javassist) org.jboss.javassist:com.springsource.javassist:jar:3.9.0.GA:compileLicense: MPL (http://www.mozilla.org/MPL/MPL-1.1.html)
- HAPI-OSGI-Base Module (http://hl7api.sourceforge.net/hapi-osgi-base/) ca.uhn.hapi:hapi-osgi-base:bundle:1.2License: Mozilla Public License 1.1 (http://www.mozilla.org/MPL/MPL-1.1.txt)