
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
Sicherheitshandbuch
Anleitung zur Sicherung von Red Hat Enterprise Linux
Ausgabe 1.5
Zusammenfassung
Kapitel 1. Überblick über Sicherheit
Anmerkung
/lib-Verzeichnis. Wenn Sie 64-bit Systeme verwenden, befinden sich einige der genannten Dateien stattdessen in /lib64.
1.1. Einführung in Sicherheit
1.1.1. Definition von Computersicherheit
1.1.1.1. Anfänge der Computersicherheit
1.1.1.2. Heutige Sicherheit
- Jeden Tag werden etwa 225 schwerwiegende Fälle von Sicherheitsverletzungen an das CERT-Koordinationszentrum an der Carnegie Mellon Universität gemeldet.[6]
- Die Anzahl der bei CERT gemeldeten Vorfälle stieg sprunghaft von 52.658 im Jahre 2001 auf 82.094 in 2002 und auf 137.529 in 2003 an.[7]
- Laut dem FBI wurde der Schaden durch Computerkriminalität für US-amerikanische Unternehmen für das Jahr 2006 auf 67,2 Milliarden US-Dollar geschätzt. [8]
- Nur 23% der Befragten haben Richtlinien zur Verwendung von Web 2.0 Technologien. Diese Technologien wie z. B. Twitter, Facebook und LinkedIn bieten zwar einen bequemen Weg für Unternehmen und Privatpersonen zur Kommunikation und Zusammenarbeit, öffnen gleichzeitig aber auch neue Schwachstellen, insbesondere das mögliche Durchsickern vertraulicher Daten.
- Sogar während der kürzlichen Finanzkrise in 2009 waren die in der Befragung festgestellten Sicherheitsbudgets im Vergleich zu den Vorjahren etwa gleich geblieben oder gestiegen (fast 2 von 3 Befragten erwarteten gleichbleibende oder steigende Ausgaben). Das sind gute Neuigkeiten, da es den Wert widerspiegelt, den Unternehmen heutzutage auf Datensicherheit legen.
1.1.1.3. Standardisierung der Sicherheit
- Vertraulichkeit — Vertrauliche Informationen dürfen nur für im vornherein festgelegte Einzelpersonen verfügbar sein. Unautorisierte Übertragung und Verwendung von Informationen muss verhindert werden. So stellt zum Beispiel die Vertraulichkeit von Informationen sicher, dass persönliche oder finanzielle Details von Kunden nicht von Unbefugten für böswillige Zwecke wie Identitätsraub oder Kreditbetrug missbraucht werden können.
- Integrität — Informationen dürfen nicht derart verändert werden, dass sie unvollständig oder falsch werden. Unbefugte müssen daran gehindert werden, vertrauliche Informationen ändern oder zerstören zu können.
- Verfügbarkeit — Informationen müssen jederzeit für befugte Personen zugänglich sein. Verfügbarkeit ist die Garantie dafür, dass Informationen mit einer vereinbarten Häufigkeit und rechtzeitig abgerufen werden können. Dies wird häufig in Prozent gemessen und formell in Service-Level-Agreements (SLAs) zwischen Netzwerkservice-Anbietern und deren Geschäftskunden festgelegt.
1.1.2. SELinux
1.1.3. Sicherheitskontrollen
- Physische Kontrolle
- Technische Kontrolle
- Administrative Kontrolle
1.1.3.1. Physische Kontrolle
- Überwachungskameras
- Bewegungs- oder Wärmemelder
- Sicherheitspersonal
- Ausweise
- Verriegelte Stahltüren
- Biometrie (z. B. Erkennung von Fingerabdrücken, Stimme, Gesicht, Iris, Handschrift oder andere automatisierte Methoden, um die Identität von Personen nachzuweisen)
1.1.3.2. Technische Kontrollen
- Verschlüsselung
- Smart Cards
- Netzwerkauthentifizierung
- Zugangskontrolllisten (ACLs)
- Software zur Prüfung der Dateiintegrität
1.1.3.3. Administrative Kontrollen
- Schulung und Aufklärung
- Katastrophenvorbereitung und Wiederherstellungspläne
- Personaleinstellungs- und Separations-Strategien
- Mitarbeiterregistrierung und Buchhaltung
1.1.4. Fazit
1.2. Schwachstellenanalyse
- Die Kompetenz der Mitarbeiter, die für die Konfiguration, Überwachung und Wartung dieser Technologien verantwortlich sind.
- Die Fähigkeit, Dienste und Kernel schnell und effizient mit Patches versehen und aktualisieren zu können.
- Die Fähigkeit der Verantwortlichen, konstante Wachsamkeit im Netzwerk auszuüben.
1.2.1. Denken wie der Feind
1.2.2. Definition von Analyse und Test
Warnung
- Proaktiver Fokus auf Informationssicherheit
- Auffinden potenzieller Schwachstellen, bevor diese von Angreifern gefunden werden
- Resultiert normalerweise darin, dass Systeme aktuell gehalten und mit Patches versehen werden
- Fördert Wachstum und hilft bei der Entwicklung von Mitarbeiterkompetenz
- Vermindert finanzielle Verluste und negative Presse
1.2.2.1. Entwickeln einer Methodik
- http://www.isecom.org/osstmm/ The Open Source Security Testing Methodology Manual (OSSTMM)
- http://www.owasp.org/ The Open Web Application Security Project
1.2.3. Bewerten der Tools
1.2.3.1. Scannen von Hosts mit Nmap
1.2.3.1.1. Verwendung von Nmap
nmap gefolgt vom Hostnamen oder der IP-Adresse des zu scannenden Computers ein.
nmap foo.example.comInteresting ports on foo.example.com: Not shown: 1710 filtered ports PORT STATE SERVICE 22/tcp open ssh 53/tcp open domain 80/tcp open http 113/tcp closed auth
1.2.3.2. Nessus
Anmerkung
1.2.3.3. Nikto
1.2.3.4. Für Ihre zukünftigen Bedürfnisse vorausplanen
1.3. Angreifer und Schwachstellen
1.3.1. Ein kurzer geschichtlicher Überblick über Hacker
1.3.1.1. Grauzonen
1.3.2. Bedrohungen der Netzwerksicherheit
1.3.2.1. Unsichere Architekturen
1.3.2.1.1. Broadcast-Netzwerke
1.3.2.1.2. Zentralisierte Server
1.3.3. Bedrohungen der Serversicherheit
1.3.3.1. Unbenutzte Dienste und offene Ports
1.3.3.2. Dienste ohne Patches
1.3.3.3. Unaufmerksame Administration
1.3.3.4. Von Natur aus unsichere Dienste
1.3.4. Bedrohungen der Arbeitsplatzrechner- und Heim-PC-Sicherheit
1.3.4.1. Unsichere Passwörter
1.3.4.2. Anfällige Client-Applikationen
1.4. Häufige Sicherheitslücken und Angriffe
Tabelle 1.1. Häufige Sicherheitslücken
| Sicherheitslücke | Beschreibung | Anmerkungen | |||
|---|---|---|---|---|---|
| Null- oder Standardpasswort | Das Leerlassen von administrativen Passwörtern oder das Verwenden von Standardpasswörtern des Herstellers. Dies betrifft häufig Hardware wie Router und Firewalls, jedoch können auch einige Dienste, die unter Linux laufen, standardmäßige Administratorenpasswörter enthalten (Red Hat Enterprise Linux wird jedoch nicht mit diesen ausgeliefert). |
| |||
| Gemeinsam genutzte Standardschlüssel | Sichere Dienste werden manchmal mit standardmäßigen Sicherheitsschlüsseln für Entwicklung oder zu Evaluierungszwecken ausgeliefert. Werden diese Schlüssel nicht geändert und auf einer Produktionsumgebung im Internet platziert, kann jeder Benutzer mit denselben Standardschlüsseln auf diese Ressourcen mit gemeinsam genutzten Schlüsseln und damit auf alle sensiblen Informationen darin zugreifen. |
| |||
| IP-Spoofing | Eine sich entfernt befindliche Maschine verhält sich wie ein Knoten im lokalen Netzwerk, findet Schwachstellen auf Ihrem Server und installiert ein Backdoor-Programm oder einen Trojaner, um Kontrolle über Ihre Netzwerkressourcen zu erlangen. |
| |||
| Abhören | Das Sammeln von Daten, die zwischen zwei aktiven Knoten auf einem Netzwerk ausgetauscht werden, indem die Verbindung dieser beiden Knoten abgehört wird. |
| |||
| Schwachstellen von Diensten | Ein Angreifer findet einen Fehler oder ein Schlupfloch in einem Dienst, der über das Internet läuft. Durch diese Schwachstelle kann der Angreifer das gesamte System und alle Daten darauf sowie weitere Systeme im Netzwerk kompromittieren. |
| |||
| Schwachstellen von Applikationen | Angreifer finden Fehler in Applikationen von Desktops und Arbeitsplatzrechnern (wie z. B. E-Mail-Clients) und führen willkürlich Code aus, implantieren Trojaner für zukünftige Attacken oder bringen Systeme zum Absturz. Noch größerer Schaden kann angerichtet werden, falls der kompromittierte Arbeitsplatzrechner administrative Berechtigungen für den Rest des Netzwerks besitzt. |
| |||
| Denial-of-Service (DoS) Angriffe | Ein Angreifer bzw. eine Gruppe von Angreifern koordiniert eine Attacke auf ein Netzwerk oder auf Serverressourcen eines Unternehmens, bei der unbefugte Pakete an den Zielcomputer (entweder Server, Router oder Arbeitsplatzrechner) gesendet werden. Dies macht die Ressource für berechtigte Benutzer nicht verfügbar. |
|
1.5. Sicherheitsaktualisierungen
1.5.1. Aktualisieren von Paketen
Anmerkung
1.5.2. Verifizieren von signierten Paketen
/mnt/cdrom eingehängt, können Sie den folgenden Befehl zum Importieren des Schlüssels in den Schlüsselbund (engl. "Keyring", eine Datenbank bestehend aus vertrauenswürdigen Schlüsseln auf dem System) verwenden.
rpm --import /mnt/cdrom/RPM-GPG-KEYrpm -qa gpg-pubkey*gpg-pubkey-db42a60e-37ea5438rpm -qi, gefolgt von der Ausgabe des vorherigen Befehls, in diesem Beispiel also:
rpm -qi gpg-pubkey-db42a60e-37ea5438rpm -K /tmp/updates/*.rpmgpg OK. Ist dies nicht der Fall, überprüfen Sie, ob Sie den richtigen öffentlichen Schlüssel von Red Hat verwenden und verifizieren Sie die Quelle des Inhalts. Pakete, welche die GPG-Verifizierung nicht bestehen, sollten nicht installiert werden, da sie möglicherweise von Dritten verändert wurden.
1.5.3. Installieren von signierten Paketen
rpm -Uvh /tmp/updates/*.rpmrpm -ivh /tmp/updates/<kernel-package>rpm -e <old-kernel-package>Anmerkung
Wichtig
1.5.4. Anwenden der Änderungen
Anmerkung
- Applikationen
- Bei User-Space-Applikationen handelt es sich um alle Programme, die durch einen Systembenutzer gestartet werden können. Für gewöhnlich laufen diese Anwendungen nur, wenn ein Benutzer, ein Skript oder ein automatisiertes Dienstprogramm diese startet, und sie werden in der Regel nicht für längere Zeit ausgeführt.Wird solch eine User-Space-Applikation aktualisiert, stoppen Sie alle Instanzen dieser Anwendung auf dem System und starten Sie das Programm erneut, um die aktualisierte Version zu verwenden.
- Kernel
- Der Kernel ist die Kern-Software-Komponente für das Red Hat Enterprise Linux Betriebssystem. Er verwaltet den Zugriff auf den Speicher, den Prozessor und auf Peripheriegeräte, und plant sämtliche Aufgaben.Aufgrund seiner zentralen Rolle kann der Kernel nur durch ein Herunterfahren des Computers neu gestartet werden. Daher kann eine aktualisierte Version des Kernels erst verwendet werden, wenn das System neu gestartet wird.
- Gemeinsam verwendete Bibliotheken
- Gemeinsam verwendete Bibliotheken sind Einheiten von Code, wie z. B.
glibc, die von einer Reihe von Applikationen und Software-Programmen gemeinsam verwendet werden. Applikationen, die gemeinsam verwendete Bibliotheken nutzen, laden normalerweise den gemeinsamen Code beim Starten der Anwendungen, so dass alle Applikationen, die die aktualisierte Bibliothek verwenden, neu gestartet werden müssen.Um festzustellen, welche laufenden Applikationen mit einer bestimmten Bibliothek verknüpft sind, verwenden Sie den Befehllsofwie im folgenden Beispiel:lsof /lib/libwrap.so*Dieser Befehl gibt eine Liste aller laufenden Programme aus, die TCP-Wrappers für die Host-Zugangskontrolle verwenden. Alle aufgelisteten Programme müssen angehalten und neu gestartet werden, wenn dastcp_wrappers-Paket aktualisiert wird. - SysV-Dienste
- SysV-Dienste sind persistente Server-Programme, die während des Bootens gestartet werden. Beispiele für SysV-Dienste sind
sshd,vsftpdundxinetd.Da diese Programme normalerweise im Speicher verbleiben, solange der Rechner läuft, muss jeder aktualisierte SysV-Dienst nach der Aktualisierung des Pakets angehalten und neu gestartet werden. Dies kann über das Tool zur Dienstkonfiguration oder durch Anmelden als Root via Shell-Prompt und Ausführen des Befehls/sbin/serviceerreicht werden, wie im folgenden Beispiel veranschaulicht:/sbin/service <service-name> restartErsetzen Sie im obigen Beispiel <service-name> durch den Namen des Dienstes, wie z. B.sshd. xinetd-Dienste- Dienste, die vom Super-Dienst
xinetdgesteuert werden, werden nur ausgeführt, wenn eine aktive Verbindung vorliegt. Vonxinetdgesteuert werden z. B. die Telnet, IMAP und POP3-Dienste.Daxinetdjedesmal neue Instanzen dieser Dienste startet, wenn eine neue Anfrage empfangen wird, werden die Verbindungen, die nach einer Aktualisierung entstehen, durch die aktualisierte Software gesteuert. Bestehen jedoch zu dem Zeitpunkt, an dem vonxinetdverwaltete Dienste aktualisiert werden, aktive Verbindungen, so werden diese noch von der älteren Version der Software bedient.Um ältere Instanzen eines bestimmtenxinetd-Dienstes zu stoppen, aktualisieren Sie das Paket für den Dienst und stoppen Sie anschließend alle aktuell laufenden Prozesse. Mit dem Befehlpskönnen Sie feststellen, welche Prozesse laufen. Geben Sie dann den Befehlkilloderkillallein, um alle aktuellen Instanzen dieses Dienstes zu stoppen.Wenn zum Beispiel Sicherheits-Errata für dieimap-Pakete herausgegeben werden, aktualisieren Sie die Pakete und geben Sie danach folgenden Befehl als Root ein:ps aux | grep imapDieser Befehl gibt alle aktiven IMAP-Sitzungen aus. Einzelne Sitzungen können dann mithilfe des folgenden Befehls beendet werden:kill <PID>Falls das Beenden der Sitzung damit fehlschlägt, verwenden Sie stattdessen folgenden Befehl:kill -9 <PID>Ersetzen Sie im obigen Beispiel <PID> durch die Prozess-Identifikationsnummer (zu finden in der zweiten Spalte desps-Befehls) der fraglichen IMAP-Sitzung.Um alle aktiven IMAP-Sitzungen zu beenden, geben Sie den folgenden Befehl ein:killall imapd
Kapitel 2. Sichern Ihres Netzwerks
2.1. Sicherheit eines Arbeitsplatzrechners
2.1.1. Beurteilung der Arbeitsplatzrechner-Sicherheit
- BIOS und Bootloader-Sicherheit — Kann ein unbefugter Benutzer physisch auf den Rechner zugreifen und in den Einzelbenutzer- oder Rettungsmodus booten, ohne dass nach einem Passwort gefragt wird?
- Passwortsicherheit — Wie sicher sind die Passwörter für die Benutzeraccounts auf dem Rechner?
- Administrative Kontrolle — Wer hat alles einen Account auf dem System, und wie viel administrative Kontrolle wird diesen Accounts gewährt?
- Verfügbare Netzwerkdienste — Welche Dienste horchen auf dem Netzwerk auf Anfragen, und sollten diese überhaupt aktiv sein?
- Persönliche Firewalls — Welche Art von Firewall, wenn überhaupt, ist nötig?
- Kommunikationstools mit erweiterter Sicherheit — Welche Tools sollten zur Kommunikation zwischen Arbeitsplatzrechnern verwendet werden, und welche sollten vermieden werden?
2.1.2. BIOS und Bootloader-Sicherheit
2.1.2.1. BIOS-Passwörter
- Änderungen an den BIOS-Einstellungen verhindern — Hat ein Eindringling Zugang zum BIOS, kann dieser den Bootvorgang von einer Diskette oder einer CD-ROM festlegen. Dies ermöglicht dann, in den Rettungsmodus oder Einzelbenutzermodus zu gelangen und von hier aus schädliche Prozesse auf dem System zu starten oder sensible Daten zu kopieren.
- System-Boot verhindern — Einige BIOS erlauben Ihnen, den Bootvorgang selbst mit einem Passwort zu schützen. Ist dies aktiviert, muss ein Passwort eingegeben werden, bevor das BIOS den Bootloader startet.
2.1.2.1.1. Sicherung von nicht-x86-Plattformen
2.1.2.2. Bootloader-Passwörter
- Zugang zum Einzelbenutzermodus verhindern — Wenn Angreifer in den Einzelbenutzermodus booten können, werden diese automatisch zu Root-Benutzern, ohne nach dem Root-Passwort gefragt zu werden.
- Zugang zur GRUB-Konsole verhindern — Wenn der Rechner GRUB als Bootloader verwendet, kann ein Angreifer die GRUB-Editor-Schnittstelle verwenden, um die Konfiguration zu ändern oder Informationen mithilfe des
cat-Befehls zu sammeln. - Zugang zu unsicheren Betriebssystemen verhindern — Haben Sie ein Dual-Boot-System, kann ein Angreifer während des Bootens ein Betriebssystem wie zum Beispiel DOS auswählen, das Zugangskontrollen und Dateiberechtigungen ignoriert.
2.1.2.2.1. Passwortschutz für GRUB
/sbin/grub-md5-crypt/boot/grub/grub.conf. Öffnen Sie die Datei und fügen Sie die nachfolgende Zeile unterhalb der timeout-Zeile im Hauptabschnitt des Dokuments ein:
password --md5 <password-hash>/sbin/grub-md5-crypt[12] ausgegeben wurde.
/boot/grub/grub.conf bearbeiten.
title-Zeile des Betriebssystems, das sie absichern möchten, und fügen Sie direkt darunter eine Zeile mit der lock-Direktive ein.
title DOS lockWarnung
password-Zeile im Hauptabschnitt der /boot/grub/grub.conf-Datei vorhanden sein, damit diese Methode funktionieren kann. Andernfalls kann ein Angreifer auf den GRUB-Editor zugreifen und die lock-Zeile entfernen.
lock-Zeile gefolgt von einer Passwortzeile in den Absatz ein.
title DOS lock password --md5 <password-hash>2.1.3. Passwortsicherheit
/etc/passwd-Datei gespeichert, wodurch das System potenziell für Angriffe verwundbar wird, bei denen Passwörter offline geknackt werden. Erlangt ein Angreifer als regulärer Benutzer Zugriff auf das System, kann er die /etc/passwd-Datei auf seinen eigenen Rechner kopieren und diverse Programme zum Knacken von Passwörtern darüber laufen lassen. Befindet sich ein unsicheres Passwort in der Datei, ist es nur eine Frage der Zeit, bis es von diesen Programmen geknackt wird.
/etc/shadow gespeichert werden, die nur vom Root-Benutzer gelesen werden kann.
2.1.3.1. Erstellen sicherer Passwörter
- Verwenden Sie nicht nur Wörter oder Zahlen — Sie sollten für ein Passwort nicht ausschließlich Wörter oder ausschließlich Zahlen verwenden.Hier einige Beispiele für unsichere Passwörter:
- 8675309
- juan
- hackme
- Verwenden Sie keine erkennbaren Wörter — Wörter wie Namen, im Wörterbuch stehende Wörter oder Begriffe aus Fernsehsendungen oder Romanen sollten vermieden werden, auch wenn diese am Ende mit Zahlen versehen werden.Hier einige Beispiele für unsichere Passwörter:
- john1
- DS-9
- mentat123
- Verwenden Sie keine Wörter in anderen Sprachen — Programme zum Knacken von Passwörtern prüfen oft anhand von Wortlisten, die Wörterbücher in anderen Sprachen umfassen. Sich für sichere Passwörter auf Fremdsprachen zu verlassen ist daher häufig wenig hilfreich.Hier einige Beispiele für unsichere Passwörter:
- cheguevara
- bienvenido1
- 1dummkopf
- Verwenden Sie keine Hacker-Begriffe — Glauben Sie nicht, dass Sie auf der sicheren Seite sind, wenn Sie Hacker-Begriffe — auch l337 (LEET) genannt — für Ihre Passwörter verwenden. Viele Wortlisten enthalten LEET-Begriffe.Hier einige Beispiele für unsichere Passwörter:
- H4X0R
- 1337
- Verwenden Sie keine persönlichen Informationen — Vermeiden Sie die Verwendung von persönlichen Informationen in Ihren Passwörtern. Wenn der Angreifer Sie kennt, kann er Ihr Passwort leichter herausfinden. Sehen Sie nachfolgend eine Liste mit zu vermeidenden Informationen beim Erstellen eines Passworts:Hier einige Beispiele für unsichere Passwörter:
- Ihren Namen
- Den Namen von Haustieren
- Die Namen von Familienmitgliedern
- Jegliche Geburtstage
- Ihre Telefonnummer oder Postleitzahl
- Drehen Sie keine erkennbaren Wörter um — Gute Passwortprogramme überprüfen gemeinsprachliche Wörter auch rückwärts, das Invertieren von schlechten Passwörtern machen diese also nicht sicherer.Hier einige Beispiele für unsichere Passwörter:
- R0X4H
- nauj
- 9-DS
- Schreiben Sie sich Ihr Passwort nicht auf — Bewahren Sie Ihr Passwort niemals auf Papier auf. Es ist wesentlich sicherer, sich das Passwort zu merken.
- Verwenden Sie nie das gleiche Passwort für alle Ihre Rechner — Es ist wichtig, dass Sie separate Passwörter für jeden Recher erstellen. So sind nicht alle Rechner auf einen Schlag betroffen, falls ein System einem Angriff zum Opfer fällt.
- Das Passwort sollte mindestens acht Zeichen enthalten — Je länger das Passwort, desto besser. Wenn Sie MD5-Passwörter verwenden, sollten diese 15 Zeichen oder mehr enthalten. DES-Passwörter sollten die maximale Länge nutzen (acht Zeichen).
- Mischen Sie Groß- und Kleinbuchstaben — In Red Hat Enterprise Linux wird Groß- und Kleinschreibung unterschieden, mischen Sie daher Groß- und Kleinbuchstaben, um die Sicherheit des Passworts zu erhöhen.
- Mischen Sie Buchstaben und Zahlen — Das Hinzufügen von Zahlen, insbesondere in der Mitte des Passwortes (nicht nur am Anfang oder Ende), verstärkt die Sicherheit des Passworts.
- Verwenden Sie Sonderzeichen — Nicht-alphanumerische Zeichen wie z. B. &, $ und > können die Sicherheit des Passworts signifikant erhöhen (nicht möglich für DES-Passwörter).
- Wählen Sie ein Passwort, das Sie sich leicht merken können — selbst das beste Passwort hilft Ihnen nicht weiter, wenn Sie sich nicht daran erinnern können. Verwenden Sie daher Akronyme oder andere mnemonische Techniken, um sich das Passwort zu merken.
2.1.3.1.1. Methode zur Erstellung sicherer Passwörter
- Überlegen Sie sich einen leicht zu merkenden Satz, wie zum Beispiel:"over the river and through the woods, to grandmother's house we go."
- Verwandeln Sie dies als Nächstes in ein Akronym (einschließlich der Satzzeichen).
otrattw,tghwg. - Machen Sie das Passwort komplexer, indem Sie Buchstaben durch Zahlen und Sonderzeichen austauschen. Ersetzen Sie zum Beispiel
tdurch7undadurch das at-Symbol (@):o7r@77w,7ghwg. - Machen Sie es noch komplexer, indem Sie mindestens einen Buchstaben groß schreiben, zum Beispiel
H.o7r@77w,7gHwg. - Und bitte verwenden Sie nicht unser Beispielpasswort für Ihre Systeme.
2.1.3.2. Erstellen von Benutzerpasswörtern innerhalb eines Unternehmens
2.1.3.2.1. Erzwingen sicherer Passwörter
passwd tun, die Pluggable Authentication Manager (PAM) unterstützt und daher prüft, ob ein Passwort zu kurz oder anderweitig zu unsicher ist. Diese Prüfung erfolgt mit dem pam_cracklib.so-PAM-Modul. Da PAM anpassbar ist, ist es möglich, weitere Passwort-Integritätsprüfer hinzuzufügen wie z. B. pam_passwdqc (erhältlich unter http://www.openwall.com/passwdqc/) oder ein neues Modul zu schreiben. Eine Liste erhältlicher PAM-Module finden Sie unter http://www.kernel.org/pub/linux/libs/pam/modules.html. Weitere Informationen über PAM finden Sie unter Managing Single Sign-On and Smart Cards.
- John The Ripper — Ein schnelles und flexibles Passwort-Cracking-Programm. Es ermöglicht die Verwendung mehrerer Wortlisten und ist fähig zum Brute-Force Passwort-Cracking. Es ist unter http://www.openwall.com/john/ erhältlich.
- Crack — Die vielleicht bekannteste Passwort-Cracking-Software. Crack ist ebenfalls sehr schnell, jedoch nicht so einfach zu verwenden wie John The Ripper. Es ist unter http://www.crypticide.com/alecm/security/crack/c50-faq.html erhältlich.
- Slurpie — Slurpie funktioniert ähnlich wie John The Ripper und Crack, ist jedoch darauf ausgelegt, auf mehreren Computern gleichzeitig zu laufen und ermöglicht so einen verteilten Passwort-Cracking-Angriff. Es ist erhältlich unter http://www.ussrback.com/distributed.htm, zusammen mit einer Reihe anderer Tools zur Bewertung der Sicherheit bei verteilten Passwort-Cracking-Angriffen.
Warnung
2.1.3.2.2. Passphrasen
2.1.3.2.3. Passwortalterung
chage oder die grafische Benutzerverwaltung (system-config-users).
-M des chage-Befehls legt die maximale Anzahl von Tagen fest, für die das Passwort gültig ist. Wenn Sie zum Beispiel festlegen wollen, dass ein Benutzerpasswort nach 90 Tagen ungültig wird, geben Sie den folgenden Befehl ein:
chage -M 90 <username>99999 nach der Option -M (dies entspricht etwas mehr als 273 Jahren).
chage auch im interaktiven Modus verwenden, um mehrere Details der Passwortalterung und des Benutzerkontos zu ändern. Verwenden Sie folgenden Befehl für den interaktiven Modus:
chage <username>[root@myServer ~]# chage davido Changing the aging information for davido Enter the new value, or press ENTER for the default Minimum Password Age [0]: 10 Maximum Password Age [99999]: 90 Last Password Change (YYYY-MM-DD) [2006-08-18]: Password Expiration Warning [7]: Password Inactive [-1]: Account Expiration Date (YYYY-MM-DD) [1969-12-31]: [root@myServer ~]#
- Klicken Sie im -Menü auf der oberen Menüleiste auf und anschließend auf , um die Benutzerverwaltung anzuzeigen. Alternativ können Sie dazu auch den Befehl
system-config-usersan einem Shell-Prompt eingeben. - Klicken Sie auf den Benutzer-Reiter und wählen Sie den gewünschten Benutzer aus der Liste aus.
- Klicken Sie auf in der Werkzeugleiste, um das Dialogfeld mit den Benutzereigenschaften anzuzeigen (oder wählen Sie aus dem -Menü).
- Klicken Sie auf den Passwort-Info-Reiter und markieren Sie das Auswahlkästchen Ablauf des Passworts aktivieren.
- Geben Sie im Feld Verbleibende Tage bis zur Änderung den gewünschten Wert ein und klicken Sie anschließend auf .
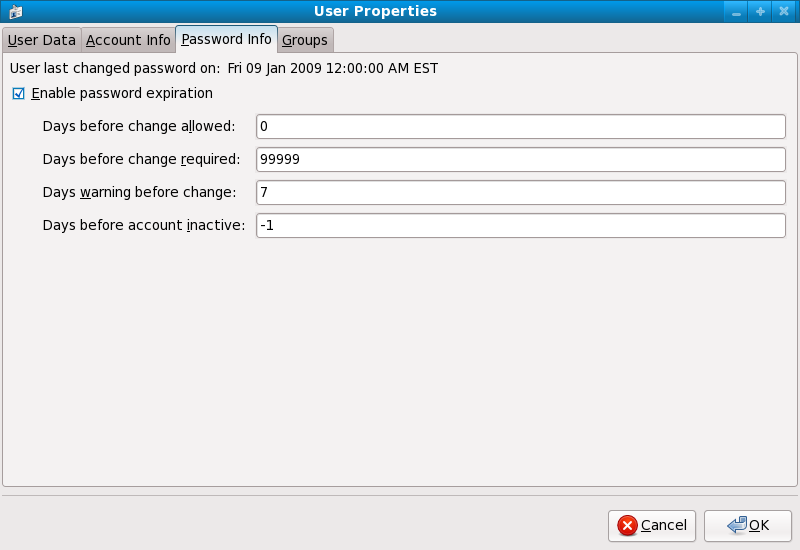
Abbildung 2.1. Angeben der Optionen zur Passwortalterung
2.1.4. Administrative Kontrolle
sudo oder su. Ein setuid-Programm ist ein Programm, das mit der Benutzer-ID (UID) des Besitzers dieses Programms ausgeführt wird, statt mit der Benutzer-ID desjenigen Benutzers, der dieses Programm ausführt. Solche Programme sind durch ein s im Besitzerabschnitt eines ausführlichen Listings gekennzeichnet, wie im folgenden Beispiel veranschaulicht:
-rwsr-xr-x 1 root root 47324 May 1 08:09 /bin/suAnmerkung
s kann ein Groß- oder Kleinbuchstabe sein. Falls es ein Großbuchstabe ist, bedeutet dies, dass das darunterliegende Berechtigungs-Bit nicht gesetzt ist.
pam_console.so können einige Vorgänge, die normalerweise nur dem Root-Benutzer erlaubt sind, wie z. B. das Neustarten und Einhängen von Wechseldatenträgern, dem ersten Benutzer erlaubt werden, der sich an der physischen Konsole anmeldet (siehe auch Managing Single Sign-On and Smart Cards für weitere Informationen über das pam_console.so-Modul). Andere wichtige Systemadministrationsaufgaben wie das Ändern von Netzwerkeinstellungen, Konfigurieren einer neuen Maus oder das Einhängen von Netzwerkgeräten sind jedoch ohne Administratorrechte nicht möglich, weshalb Systemadministratoren entscheiden müssen, in welchem Umfang die Benutzer in ihrem Netzwerk administrative Kontrolle erhalten sollen.
2.1.4.1. Gewähren von Root-Zugriff
- Fehlkonfiguration des Rechners — Benutzer mit Root-Rechten können ihre Computer unter Umständen falsch konfigurieren und benötigen dann Hilfe, oder schlimmer noch, können Sicherheitslücken öffnen, ohne dies zu merken.
- Ausführen unsicherer Dienste — Benutzer mit Root-Berechtigungen können unsichere Dienste, wie zum Beispiel FTP oder Telnet auf ihrem Rechner ausführen und dadurch Benutzernamen und Passwörter einem Risiko aussetzen, da diese im Klartext über das Netzwerk verschickt werden.
- Als Root E-Mail-Anhänge öffnen — Wenn auch selten, so gibt es doch E-Mail-Viren, die Linux angreifen. Dies wird jedoch nur dann zum Problem, wenn sie als Root ausgeführt werden.
2.1.4.2. Verwehren von Root-Zugriff
Tabelle 2.1. Methoden zum Deaktivieren des Root-Accounts
| Methode | Beschreibung | Effekt | Keine Auswirkung auf | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ändern der Root-Shell | Bearbeiten Sie die /etc/passwd-Datei und ändern Sie die Shell von /bin/bash auf /sbin/nologin. |
|
| |||||||||||||||
| Deaktivieren des Root-Zugriffs über Konsolengeräte (tty) | Eine leere /etc/securetty-Datei verhindert die Anmeldung als Root auf jeglichen am Computer angeschlossenen Geräten. |
|
| |||||||||||||||
| Deaktivieren von SSH-Logins als Root | Bearbeiten Sie die Datei /etc/ssh/sshd_config und setzen Sie den PermitRootLogin-Parameter auf no. |
|
| |||||||||||||||
| Mit PAM den Root-Zugang zu Diensten einschränken. | Bearbeiten Sie die Datei für den Zieldienst im Verzeichnis /etc/pam.d/. Stellen Sie sicher, dass die pam_listfile.so zur Authentifizierung erforderlich ist.[a] |
|
| |||||||||||||||
[a]
Siehe Abschnitt 2.1.4.2.4, »Deaktivieren von PAM für Root« für Einzelheiten.
| ||||||||||||||||||
2.1.4.2.1. Deaktivieren der Root-Shell
/etc/passwd-Datei auf /sbin/nologin setzen. Dies verhindert Zugang zum Root-Account über Befehle, die eine Shell benötigen, wie zum Beispiel su oder ssh.
Wichtig
sudo-Befehl, können weiterhin auf den Root-Account zugreifen.
2.1.4.2.2. Deaktivieren von Root-Anmeldungen
/etc/securetty bearbeiten. In dieser Datei werden alle Geräte aufgelistet, an denen sich der Root-Benutzer anmelden darf. Existiert die Datei nicht, darf sich der Root-Benutzer über jedes beliebige Kommunikationsgerät auf dem System anmelden, sei es über eine Konsole oder eine Raw-Netzwerkschnittstelle. Dies stellt ein Risiko dar, da ein Benutzer sich über Telnet am Computer als Root anmelden kann, wobei die Passwörter im Klartext über das Netzwerk versendet werden. Standardmäßig erlaubt die Red Hat Enterprise Linux Datei /etc/securetty dem Root-Benutzer nur, sich an der mit dem Rechner direkt verbundenen Konsole anzumelden. Um das Anmelden von Root zu verhindern, löschen Sie den Inhalt dieser Datei, indem Sie folgenden Befehl eingeben:
echo > /etc/securettyWarnung
/etc/securetty-Datei verhindert nicht, dass der Root-Benutzer sich von außen über die OpenSSH Toolsuite anmeldet, da die Konsole erst nach der Authentifizierung geöffnet wird.
2.1.4.2.3. Deaktivieren von Root SSH-Anmeldungen
/etc/ssh/sshd_config) bearbeiten. Ändern Sie folgende Zeile:
PermitRootLogin yesPermitRootLogin nokill -HUP `cat /var/run/sshd.pid`2.1.4.2.4. Deaktivieren von PAM für Root
/lib/security/pam_listfile.so-Modul eine größere Flexibilität in der Ablehnung bestimmter Accounts. Mithilfe dieses Moduls kann der Administrator eine Liste von Benutzern festlegen, denen die Anmeldung nicht gestattet ist. Unten finden Sie ein Beispiel, wie das Modul für den vsftpd-FTP-Server in der /etc/pam.d/vsftpd PAM-Konfigurationsdatei verwendet werden kann (das \ Zeichen am Ende der ersten Zeile im folgenden Beispiel ist nicht nötig, wenn die Direktive auf einer Zeile steht):
auth required /lib/security/pam_listfile.so item=user \ sense=deny file=/etc/vsftpd.ftpusers onerr=succeed
/etc/vsftpd.ftpusers zu lesen und allen hier aufgeführten Benutzern Zugang zum Dienst zu verbieten. Der Administrator kann den Namen dieser Datei ändern und separate Listen für jeden Dienst oder eine einzige zentrale Liste für die Zugriffsverweigerung für mehrere Dienste führen.
/etc/pam.d/pop und /etc/pam.d/imap für Mail-Clients oder /etc/pam.d/ssh für SSH-Clients hinzugefügt werden.
2.1.4.3. Beschränken des Root-Zugangs
su oder sudo gewähren.
2.1.4.3.1. Der su-Befehl
su-Befehl ausführt, wird er nach dem Root-Passwort gefragt und erhält nach erfolgreicher Authentifizierung ein Root-Shell-Prompt.
su-Befehl ist der Benutzer tatsächlich der Root-Benutzer und hat vollständigen administrativen Zugriff auf das System[13]. Nachdem der Benutzer auf diese Weise zum Root-Benutzer geworden ist, kann er mit dem Befehl su zu jedem anderen Benutzer im System wechseln, ohne nach einem Passwort gefragt zu werden.
usermod -G wheel <username>wheel-Gruppe hinzufügen möchten.
- Klicken Sie im -Menü auf der oberen Menüleiste auf und anschließend auf , um die Benutzerverwaltung anzuzeigen. Alternativ können Sie dazu auch den Befehl
system-config-usersan einem Shell-Prompt eingeben. - Klicken Sie auf den Benutzer-Reiter und wählen Sie den gewünschten Benutzer aus der Liste aus.
- Klicken Sie auf in der Werkzeugleiste, um das Dialogfeld mit den Benutzereigenschaften anzuzeigen (oder wählen Sie aus dem -Menü).
- Klicken Sie auf den Gruppen-Reiter, markieren Sie das Auswahlkästchen für die "wheel"-Gruppe und klicken Sie anschließend auf . Siehe Abbildung 2.2, »Hinzufügen von Benutzern zur "wheel"-Gruppe.«.
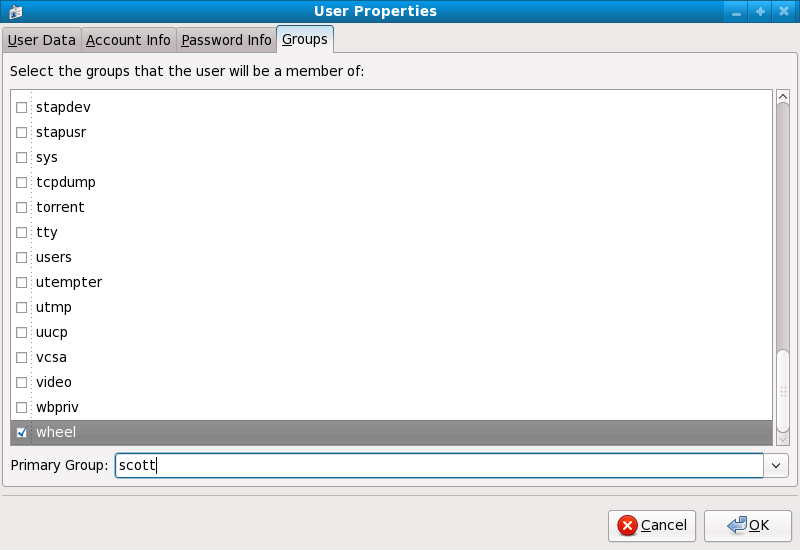
Abbildung 2.2. Hinzufügen von Benutzern zur "wheel"-Gruppe.
su (/etc/pam.d/su) in einem Texteditor und entfernen Sie die Kommentierung # von der folgenden Zeile:
auth required /lib/security/$ISA/pam_wheel.so use_uid
wheel dieses Programm nutzen.
Anmerkung
wheel-Gruppe.
2.1.4.3.2. Der sudo-Befehl
sudo-Befehl bietet eine weitere Methode, Benutzern administrativen Zugang zu gewähren. Wenn ein vertrauenswürdiger Benutzer einem administrativen Befehl den sudo-Befehl voranstellt, wird dieser nach seinem eigenen Passwort gefragt. Nach erfolgreicher Authentifizierung und vorausgesetzt, dass der Befehl erlaubt ist, wird der administrative Befehl wie von einem Root-Benutzer ausgeführt.
sudo-Befehls lautet wie folgt:
sudo <command>mount.
Wichtig
sudo-Befehls sollten sicherstellen, dass sie sich abmelden, bevor Sie sich von Ihrem Rechner entfernen, da Sudoers den Befehl innerhalb von fünf Minuten erneut ausführen können, ohne nach einem Passwort gefragt zu werden. Diese Einstellung kann mithilfe der Konfigurationsdatei /etc/sudoers geändert werden.
sudo-Befehl ermöglicht einen hohen Grad an Flexibilität. So können z. B. nur Benutzer, die in der Konfigurationsdatei /etc/sudoers aufgeführt sind, den Befehl sudo ausführen; dieser Befehl wird dann in der Shell des Benutzers ausgeführt, und nicht in der Root-Shell. Dies bedeutet, das die Root-Shell vollständig deaktiviert werden kann, wie in Abschnitt 2.1.4.2.1, »Deaktivieren der Root-Shell « gezeigt.
sudo-Befehl liefert auch ein umfangreiches Audit-Protokoll. Jede erfolgreiche Authentifizierung wird in die Datei /var/log/messages geschrieben, und der ausgeführte Befehl samt Benutzername wird in die Datei /var/log/secure geschrieben.
sudo-Befehls ist, dass ein Administrator verschiedenen Benutzern Zugang zu bestimmten Befehlen basierend auf deren Bedürfnissen geben kann.
sudo-Konfigurationsdatei /etc/sudoers bearbeiten wollen, sollten dazu den Befehl visudo verwenden.
visudo ein und fügen Sie eine Zeile ähnlich der folgenden in den Abschnitt für die Benutzerrechte ein:
juan ALL=(ALL) ALLjuan den sudo-Befehl auf jedem Host für jeden Befehl ausführen kann.
sudo:
%users localhost=/sbin/shutdown -h now/sbin/shutdown -h now ausführen kann, solange dieser auf der Konsole ausgeführt wird.
sudoers-Handbuchseite enthält eine detaillierte Liste aller Optionen für diese Datei.
2.1.5. Verfügbare Netzwerkdienste
2.1.5.1. Risiken für Dienste
- Denial-of-Service-Angriff (DoS) — Indem ein System mit Anfragen überflutet wird, kann ein Denial-of-Service-Angriff ein System zum völligen Stillstand bringen, da das System versucht, jede Anfrage zu protokollieren und zu beantworten.
- Distributed-Denial-of-Service-Angriff (DDoS) — Eine Art von DoS-Angriff, bei dem mehrere infizierte Rechner (oft Tausende) missbraucht werden, um einen koordinierten Angriff auf einen Dienst durchzuführen und diesen mit Anfragen zu überfluten.
- Skript-Angriff — Wenn ein Server Skripte zum Ausführen von serverseitigen Aufgaben verwendet, wie es Webserver gewöhnlich tun, kann ein Cracker durch nicht-sachgemäß erstellte Skripte einen Angriff initiieren. Diese Skript-Angriffe können zu einem Pufferüberlauf führen oder es dem Angreifer ermöglichen, Dateien auf dem Server zu ändern.
- Pufferüberlauf-Angriff — Dienste, die sich auf Ports 0 bis 1023 verbinden, müssen als administrativer Benutzer ausgeführt werden. Hat die Applikation einen Pufferüberlauf, kann ein Angreifer Zugang zum System erlangen als der Benutzer, der den Daemon ausführt. Da Pufferüberläufe existieren, können Cracker mit automatisierten Tools das System auf Schwachstellen prüfen. Sobald diese dann Zugang zum System haben, können sie mithilfe automatisierter Root-Kits den Zugang zum System aufrecht erhalten.
Anmerkung
Wichtig
2.1.5.2. Identifizieren und Konfigurieren von Diensten
cupsd— Der standardmäßige Druckerserver für Red Hat Enterprise Linux.lpd— Ein alternativer Druckerserver.xinetd— Ein Super-Server, der die Verbindungen zu einer Reihe untergeordneter Server, wie zum Beispielgssftpundtelnetsteuert.sendmail— Der Sendmail Mail Transport Agent (MTA) ist standardmäßig aktiviert, horcht jedoch nur auf Verbindungen von localhost.sshd— Der OpenSSH Server, ein sicherer Ersatz für Telnet.
cupsd nicht ausführen. Das gleiche gilt für portmap. Wenn Sie keine NFSv3-Datenträger einhängen oder NIS (den ypbind-Dienst) nicht verwenden, sollte Portmap deaktiviert werden.
Abbildung 2.3. Tool zur Dienstkonfiguration
2.1.5.3. Unsichere Dienste
- Unverschlüsselte Übertragung von Benutzernamen und Passwörtern über ein Netzwerk — Viele ältere Protokolle, wie beispielsweise Telnet und FTP, verschlüsseln die Authentifizierung nicht und sollten möglichst deaktiviert werden.
- Unverschlüsselte Übertragung von sensiblen Daten über ein Netzwerk — Viele Protokolle übertragen Daten unverschlüsselt über das Netzwerk. Zu diesen Protokollen gehört unter anderem Telnet, FTP, HTTP und SMTP. Viele Netzwerkdateisysteme wie z. B. NFS und SMB übertragen ebenfalls Informationen unverschlüsselt über das Netzwerk. Es liegt in der Verantwortung des Benutzers, einzuschränken, welche Art von Daten bei der Verwendung dieser Protokolle übertragen werden.Auch Remote-Speicherabbildungsdienste wie
netdumpübertragen den Speicherinhalt unverschlüsselt über das Netzwerk. Speicherauszüge können Passwörter, oder schlimmer noch, Datenbankeinträge und andere sensible Informationen enthalten.Andere Dienste wiefingerundrwhodgeben Informationen über Benutzer im System preis.
rlogin, rsh, telnet und vsftpd.
rlogin, rsh und telnet) sollten zugunsten von SSH vermieden werden. Siehe Abschnitt 2.1.7, »Kommunikationstools mit verbesserter Sicherheit« für weitere Informationen über sshd.
fingerauthd(in früheren Red Hat Enterprise Linux Releasesidentdgenannt)netdumpnetdump-servernfsrwhodsendmailsmb(Samba)yppasswddypservypxfrd
2.1.6. Persönliche Firewalls
Wichtig
system-config-securitylevel). Dieses Tool erzeugt breite iptables-Regeln für eine allgemeine Firewall, unter Verwendung einer grafischen Benutzeroberfläche.
iptables die bessere Wahl. Weitere Informationen finden Sie unter Abschnitt 2.5, »Firewalls«. Einen umfassenden Leitfaden zum iptables-Befehl finden Sie unter Abschnitt 2.6, »IPTables«.
2.1.7. Kommunikationstools mit verbesserter Sicherheit
- OpenSSH — Eine offene Implementierung des SSH-Protokolls zur Verschlüsselung von Netzwerkkommunikation.
- Gnu Privacy Guard (GPG) — Eine offene Implementierung der PGP (Pretty Good Privacy) Verschlüsselungsapplikation zur Verschlüsselung von Daten.
telnet und rsh. OpenSSH umfasst einen Netzwerkdienst namens sshd und drei Befehlszeilen-Client-Applikationen:
ssh— Ein sicherer Client für den Zugriff auf Remote-Konsolen.scp— Ein sicherer Befehl für Remote-Copy.sftp— Ein sicherer Pseudo-FTP-Client, der interaktive Dateiübertragung ermöglicht.
Wichtig
sshd-Dienst von Natur aus sicher ist, muss dieser Dienst auf dem neuesten Stand gehalten werden, um Sicherheitsgefährdungen zu vermeiden. Unter Abschnitt 1.5, »Sicherheitsaktualisierungen« finden Sie weitere Informationen zu diesem Thema.
2.2. Server-Sicherheit
- Halten Sie alle Dienste auf dem neuesten Stand, um vor den neuesten Bedrohungen geschützt zu sein.
- Verwenden Sie nach Möglichkeit sichere Protokolle.
- Wenn möglich, sollte immer nur eine Maschine eine Art von Netzwerkdienst bereitstellen.
- Überwachen Sie alle Server sorgfältig auf verdächtige Aktivitäten.
2.2.1. Sichern von Diensten mit TCP-Wrappern und xinetd
xinetd verwendet werden, einem Super-Serverdienst, der zusätzliche Zugriffs-, Protokollierungs-, Binding-, Umleitungs- und Ressourcenkontrolle bietet.
Anmerkung
xinetd zu verwenden, um eine Redundanz innerhalb der Dienst-Zugangskontrollen zu erreichen. Für mehr Information über das Einrichten von Firewalls mit IPTables-Befehlen siehe Abschnitt 2.5, »Firewalls«.
2.2.1.1. Erhöhung der Sicherheit mit TCP-Wrappern
hosts_options-Handbuchseite. Werfen Sie zudem einen Blick auf die xinetd.conf-Handbuchseite, erhältlich online unter http://linux.die.net/man/5/xinetd.conf, für Informationen über verfügbare Flags, die Sie als Optionen auf einen Dienst anwenden können.
2.2.1.1.1. TCP-Wrapper und Verbindungsbanner
banner.
vsftpd implementiert. Erstellen Sie zunächst einmal eine Bannerdatei. Es ist unerheblich, wo diese sich auf dem System befindet, muss aber den gleichen Namen wie der Daemon tragen. In diesem Beispiel heißt die Datei /etc/banners/vsftpd und enthält die folgende Zeile:
220-Hello, %c 220-All activity on ftp.example.com is logged. 220-Inappropriate use will result in your access privileges being removed.
%c-Token liefert eine Reihe von Client-Informationen wie den Benutzernamen und Hostnamen, oder den Benutzernamen und die IP-Adresse, um die Verbindung noch abschreckender zu machen.
/etc/hosts.allow ein:
vsftpd : ALL : banners /etc/banners/ 2.2.1.1.2. TCP-Wrapper und Warnung vor Angriffen
spawn-Direktive vor weiteren Angriffen von diesem Host oder Netzwerk warnen.
/etc/hosts.deny einfügen, wird der Verbindungsversuch abgewiesen und in einer speziellen Datei aufgezeichnet:
ALL : 206.182.68.0 : spawn /bin/echo `date` %c %d >> /var/log/intruder_alert %d-Token gibt den Namen des Dienstes an, auf den der Angreifer zugreifen wollte.
spawn-Direktive in die Datei /etc/hosts.allow ein.
Anmerkung
spawn-Direktive jeden beliebigen Shell-Befehl ausführt, können Sie ein spezielles Skript schreiben, das den Administrator im Falle eines Verbindungsversuchs eines bestimmten Clients mit dem Server benachrichtigt oder eine Reihe von Befehlen ausführt.
2.2.1.1.3. TCP-Wrapper und erweiterte Protokollierung
severity angehoben werden.
emerg-Flag anstelle des Standard-Flags info in die Protokolldatei ein und verweigern Sie die Verbindung.
/etc/hosts.deny ein:
in.telnetd : ALL : severity emerg authpriv-Protokollierungs-Facility verwendet, jedoch wird die Priorität vom Standardwert info auf emerg angehoben, wodurch Protokollnachrichten direkt auf der Konsole ausgegeben werden.
2.2.1.2. Erhöhen der Sicherheit mit xinetd
xinetd dazu eingesetzt werden kann, einen so genannten Trap-Dienst einzurichten sowie die verfügbaren Ressourcen für jeden xinetd-Dienst zu kontrollieren. Das Setzen von Ressourcengrenzen kann dabei helfen, Denial of Service (DoS)-Angriffe zu unterbinden. Eine Liste der verfügbaren Optionen finden Sie auf den Handbuchseiten zu xinetd und xinetd.conf.
2.2.1.2.1. Aufstellen einer Falle
xinetd ist die Fähigkeit, Hosts zu einer globalen no_access-Liste hinzufügen zu können. Den Hosts auf dieser Liste werden Verbindungen zu Diensten, die von xinetd verwaltet werden, für einen bestimmten Zeitraum oder bis xinetd neu gestartet wird, verweigert. Dies wird durch den SENSOR-Parameter erreicht. Mithilfe dieses einfachen Verfahrens können Sie Hosts blockieren, die den Server auf offene Ports absuchen.
SENSOR ist die Auswahl eines Dienstes, den Sie voraussichtlich nicht anderweitig brauchen werden. In diesem Beispiel wird Telnet ausgewählt.
/etc/xinetd.d/telnet und ändern Sie die Zeile flags folgendermaßen um:
flags = SENSOR
deny_time = 30
deny_time-Attribut sind FOREVER, wodurch eine Verbindung solange verweigert wird, bis xinetd neu gestartet wird, und NEVER, wodurch die Verbindung zugelassen und protokolliert wird.
disable = no
SENSOR eine gute Methode ist, Verbindungen von böswilligen Hosts zu erkennen und zu stoppen, hat es jedoch zwei Nachteile:
- Es hilft nicht gegen heimliches Scannen (Stealth Scans).
- Ein Angreifer, der weiß, dass ein
SENSORaktiviert ist, kann eine DoS-Attacke gegen bestimmte Hosts ausführen, indem er ihre IP-Adressen fälscht und sich mit dem verbotenen Port verbindet.
2.2.1.2.2. Kontrollieren von Server-Ressourcen
xinetd ist die Fähigkeit, für die von ihm kontrollierten Dienste Ressourcengrenzen festzulegen.
cps = <number_of_connections> <wait_period>— Begrenzt die Frequenz der eingehenden Verbindungen. Diese Direktive akzeptiert zwei Parameter:<number_of_connections>— Die Anzahl der zu verarbeitenden Verbindungen pro Sekunde. Falls die Frequenz der eingehenden Verbindungen diesen Wert überschreitet, wird der Dienst zeitweise deaktiviert. Der Standardwert ist fünfzig (50).<wait_period>— Gibt die Anzahl der Sekunden an, die gewartet werden soll, bevor der Dienst nach dessen Deaktivierung neu gestartet werden soll. Die Standardzeitspanne beträgt zehn (10) Sekunden.
instances = <number_of_connections>— Gibt die Gesamtzahl aller erlaubten Verbindungen zu einem Dienst an. Diese Direktive akzeptiert entweder einen ganzzahligen Wert oderUNLIMITED.per_source = <number_of_connections>— Gibt die Anzahl der Verbindungen an, die pro Host zu einem Dienst erlaubt sind. Diese Direktive akzeptiert entweder einen ganzzahligen Wert oderUNLIMITED.rlimit_as = <number[K|M]>— Gibt die Größe des Speicheradressraums in Kilobyte oder Megabyte an, die der Dienst in Anspruch nehmen kann kann. Diese Direktive akzeptiert entweder einen ganzzahligen Wert oderUNLIMITED.rlimit_cpu = <number_of_seconds>— Gibt die Zeit in Sekunden an, die ein Dienst die CPU beanspruchen kann. Diese Direktive akzeptiert entweder einen ganzzahligen Wert oderUNLIMITED.
xinetd-Dienst das gesamte System überschwemmt und einen Denial-of-Service verursacht.
2.2.2. Sichern von Portmap
portmap-Dienst ist ein Daemon zur dynamischen Port-Zuweisung für RPC-Dienste wie NIS und NFS. Er besitzt schwache Authentifizierungsmechanismen und hat die Fähigkeit, einen großen Bereich an Ports für die von ihm kontrollierten Dienste zuzuweisen. Aus diesen Gründen ist Portmap schwer zu sichern.
Anmerkung
portmap betrifft lediglich NFSv2- und NFSv3-Implementationen, da Portmap für NFSv4 nicht mehr länger erforderlich ist. Wenn Sie einen NFSv2- oder NFSv3-Server implementieren möchten, dann ist portmap demnach erforderlich und der folgende Abschnitt für Sie wichtig.
2.2.2.1. Schützen von Portmap mit TCP-Wrappern
portmap-Dienst einzusetzen, da Portmap selbst keine integrierte Authentifizierungsmöglichkeit bietet.
2.2.2.2. Schützen von Portmap mit IPTables
portmap-Dienst weiter einzuschränken, ist es sinnvoll, IPTables-Regeln zum Server hinzuzufügen, die den Zugriff auf bestimmte Netzwerke einschränken.
portmap-Dienst verwendet wird) vom 192.168.0/24 Netzwerk. Der zweite Befehl erlaubt TCP-Verbindungen auf demselben Port vom lokalen Host, was für den sgi_fam-Dienst für Nautilus benötigt wird. Alle anderen Pakete werden abgelehnt.
iptables -A INPUT -p tcp ! -s 192.168.0.0/24 --dport 111 -j DROP iptables -A INPUT -p tcp -s 127.0.0.1 --dport 111 -j ACCEPT
iptables -A INPUT -p udp ! -s 192.168.0.0/24 --dport 111 -j DROP
Anmerkung
2.2.3. Sichern von NIS
ypserv, der zusammen mit portmap und anderen zugehörigen Diensten verwendet wird, um Informationen zu Benutzernamen, Passwörtern und anderen sensiblen Daten an jeden beliebigen Computer innerhalb dessen Domain weiterzugeben.
/usr/sbin/rpc.yppasswdd— Auchyppasswdd-Dienst genannt. Dieser Daemon ermöglicht es Benutzern, ihre NIS-Passwörter zu ändern./usr/sbin/rpc.ypxfrd— Auchypxfrd-Dienst genannt. Dieser Daemon ist für den NIS-Map-Transfer über das Netzwerk verantwortlich./usr/sbin/yppush— Diese Applikation verbreitet geänderte NIS-Datenbanken an mehrere NIS-Server./usr/sbin/ypserv— Dies ist der NIS-Server-Daemon.
portmap-Dienst wie in Abschnitt 2.2.2, »Sichern von Portmap« beschrieben sichern und dann weitere Bereiche wie z. B. Netzwerkplanung angehen.
2.2.3.1. Planen Sie das Netzwerk sorgfältig
2.2.3.2. Verwenden Sie passwortähnliche NIS-Domain-Namen und Hostnamen
/etc/passwd-Map:
ypcat -d <NIS_domain> -h <DNS_hostname> passwd
/etc/shadow durch folgenden Befehl einsehen:
ypcat -d <NIS_domain> -h <DNS_hostname> shadow
Anmerkung
/etc/shadow nicht innerhalb einer NIS-Map gespeichert.
o7hfawtgmhwg.domain.com. Erstellen Sie auf die gleiche Weise einen anderen, zufallsgenerierten NIS-Domain-Namen. Hierdurch wird es einem Angreifer erheblich erschwert, Zugang zum NIS-Server zu erlangen.
2.2.3.3. Bearbeiten Sie die Datei /var/yp/securenets
/var/yp/securenets leer ist oder nicht existiert (dies ist z. B. nach einer Standardinstallation der Fall). Als Erstes sollten Sie ein Netzmaske/Netzwerkpaar in der Datei hinterlegen, damit ypserv nur auf Anfragen des richtigen Netzwerks reagiert.
/var/yp/securenets-Datei:
255.255.255.0 192.168.0.0
Warnung
/var/yp/securenets erstellt zu haben.
2.2.3.4. Weisen Sie statische Ports zu und nutzen Sie IPTables-Regeln
rpc.yppasswdd — dem Daemon, der Benutzern das Ändern ihrer Login-Passwörter erlaubt. Indem Sie den anderen beiden NIS-Server-Daemons, rpc.ypxfrd und ypserv, Ports zuweisen, können Sie Firewall-Regeln erstellen, um die NIS-Server-Daemons noch mehr vor Angriffen zu schützen.
/etc/sysconfig/network hinzu:
YPSERV_ARGS="-p 834" YPXFRD_ARGS="-p 835"
iptables -A INPUT -p ALL ! -s 192.168.0.0/24 --dport 834 -j DROP iptables -A INPUT -p ALL ! -s 192.168.0.0/24 --dport 835 -j DROP
Anmerkung
2.2.3.5. Verwenden Sie Kerberos-Authentifizierung
/etc/shadow-Map über das Netzwerk verschickt wird, sobald sich ein Benutzer an einem Computer anmeldet. Wenn ein Angreifer Zugang zu einer NIS-Domain erhält und Datenverkehr über das Netzwerk abfängt, können somit Benutzernamen und Passwort-Hashes unbemerkt gesammelt werden. Mit genügend Zeit kann dann ein Programm zum Knacken von Passwörtern schwache Passwörter ermitteln, wodurch ein Angreifer auf einen gültigen Account im Netzwerk zugreifen kann.
2.2.4. Sichern von NFS
Wichtig
portmap-Dienst, wie im Abschnitt 2.2.2, »Sichern von Portmap« beschrieben. Der NFS-Datenverkehr benutzt statt UDP nunmehr TCP in allen Versionen und erfordert TCP bei der Verwendung von NFSv4. NFSv4 beinhaltet nun Kerberos Benutzer- und Gruppenauthentifizierung als Teil des RPCSEC_GSS Kernel-Moduls. Informationen über portmap sind jedoch nach wie vor enthalten, da Red Hat Enterprise Linux 6 auch noch NFSv2 und NFSv3 unterstützt, die portmap einsetzen.
2.2.4.1. Planen Sie das Netzwerk sorgfältig
2.2.4.2. Vermeiden Sie Syntaxfehler
/etc/exports-Datei, welche Dateisysteme für welche Hosts exportiert werden sollen. Achten Sie darauf, dass Sie keine überflüssigen Leerstellen beim Bearbeiten dieser Datei einfügen.
/etc/exports legt fest, dass der Host bob.example.com Lese- und Schreibberechtigung auf das gemeinsam genutzte Verzeichnis /tmp/nfs/ erhält.
/tmp/nfs/ bob.example.com(rw)
/etc/exports legt dagegen fest, dass der Host bob.example.com lediglich Leseberechtigung besitzt, allerdings jeder andere Host Lese- und Schreibberechtigung hat, und das wegen eines einzelnen Leerzeichens nach dem Hostnamen.
/tmp/nfs/ bob.example.com (rw)
showmount-Befehl zu prüfen:
showmount -e <hostname>
2.2.4.3. Verwenden Sie nicht die Option no_root_squash
nfsnobody um, einen unprivilegierten Benutzer-Account. Auf diese Weise gehören alle von Root erstellten Dateien dem Benutzer nfsnobody, wodurch das Laden von Programmen mit gesetztem Setuid-Bit verhindert wird.
no_root_squash verwendet wird, können Remote-Root-Benutzer jede Datei in dem gemeinsamen Dateisystem verändern und dabei mit Trojanern infizierte Anwendungen hinterlassen, die von anderen Benutzern unbeabsichtigt ausgeführt werden.
2.2.4.4. NFS Firewall-Konfiguration
MOUNTD_PORT— TCP und UDP Port für mountd (rpc.mountd)STATD_PORT— TCP und UDP Port für status (rpc.statd)LOCKD_TCPPORT— TCP Port für nlockmgr (rpc.lockd)LOCKD_UDPPORT— UDP Port für nlockmgr (rpc.lockd)
rpcinfo -p auf dem NFS-Server aus um zu überprüfen, welche Ports und RPC-Programme verwendet werden.
2.2.5. Sicherung des Apache HTTP-Server
chown root <directory_name>
chmod 755 <directory_name>
/etc/httpd/conf/httpd.conf):
FollowSymLinks- Diese Direktive ist standardmäßig aktiviert, seien Sie also vorsichtig, wenn Sie symbolische Links zum Document-Root des Webservers erstellen. Es ist zum Beispiel keine gute Idee, einen symbolischen Link zu
/anzugeben. Indexes- Diese Direktive ist standardmäßig aktiviert, ist jedoch unter Umständen nicht wünschenswert. Wenn Sie nicht möchten, dass Benutzer Dateien auf dem Server durchsuchen, ist es sinnvoll, diese Direktive zu entfernen.
UserDir- Die
UserDir-Direktive ist standardmäßig deaktiviert, da sie das Vorhandensein eines Benutzer-Accounts im System bestätigen kann. Wenn Sie das Durchsuchen von Verzeichnissen auf dem Server durch Benutzer erlauben möchten, sollten Sie die folgenden Direktiven verwenden:UserDir enabled UserDir disabled root
Diese Direktiven aktivieren das Durchsuchen von Verzeichnissen für alle Benutzerverzeichnisse außer/root. Wenn Sie Benutzer zu der Liste deaktivierter Accounts hinzufügen möchten, können Sie eine durch Leerstellen getrennte Liste der Benutzer in die ZeileUserDir disabledeinfügen.
Wichtig
IncludesNoExec-Direktive. Standardmäßig kann das Modul Server-Side Includes (SSI) keine Befehle ausführen. Es wird davon abgeraten, diese Einstellungen zu ändern, außer wenn unbedingt notwendig, da dies einem Angreifer ermöglichen könnte, Befehle auf dem System auszuführen.
2.2.6. Sichern von FTP
gssftpd— Ein Kerberos-fähiger,xinetd-basierter FTP-Daemon, der keine Authentifizierungsinformationen über das Netzwerk überträgt.- Red Hat Content Accelerator (
tux) — Ein Kernel-Space Webserver mit FTP-Fähigkeiten. vsftpd— Eine eigenständige, sicherheitsorientierte Implementierung des FTP-Dienstes.
vsftpd-FTP-Dienstes.
2.2.6.1. FTP-Grußbanner
vsftpd zu ändern, fügen Sie die folgende Direktive zu /etc/vsftpd/vsftpd.conf-Datei hinzu:
ftpd_banner=<insert_greeting_here>
/etc/banners/. Die Bannerdatei für FTP-Verbindungen in diesem Beispiel ist /etc/banners/ftp.msg. Das nachfolgende Beispiel zeigt, wie eine derartige Datei aussehen kann:
######### # Hello, all activity on ftp.example.com is logged. #########
Anmerkung
220, wie in Abschnitt 2.2.1.1.1, »TCP-Wrapper und Verbindungsbanner« beschrieben, zu beginnen.
vsftpd auf diese Grußbanner-Datei zu verweisen, fügen Sie folgende Direktive zu /etc/vsftpd/vsftpd.conf hinzu:
banner_file=/etc/banners/ftp.msg
2.2.6.2. Anonymer Zugang
/var/ftp/-Verzeichnisses aktiviert den anonymen Account.
vsftpd-Pakets. Dieses Paket erstellt einen Verzeichnisbaum für anonyme Benutzer und vergibt anonymen Benutzern lediglich Leseberechtigungen für Verzeichnisse.
Warnung
2.2.6.2.1. Anonymes Hochladen
/var/ftp/pub/ anzulegen.
mkdir /var/ftp/pub/upload
chmod 730 /var/ftp/pub/upload
drwx-wx--- 2 root ftp 4096 Feb 13 20:05 upload
Warnung
vsftpd die folgende Zeile in die Datei /etc/vsftpd/vsftpd.conf ein:
anon_upload_enable=YES
2.2.6.3. Benutzer-Accounts
vsftpd zu deaktivieren, fügen Sie die folgende Direktive zu /etc/vsftpd/vsftpd.conf hinzu:
local_enable=NO
2.2.6.3.1. Einschränken von Benutzer-Accounts
sudo-Berechtigungen, am Zugriff auf den FTP-Server zu hindern, ist durch eine PAM-Listendatei, wie unter Abschnitt 2.1.4.2.4, »Deaktivieren von PAM für Root« beschrieben. Die PAM-Konfigurationsdatei für vsftpd ist /etc/pam.d/vsftpd.
vsftpd zu deaktivieren, fügen Sie den Benutzernamen zu /etc/vsftpd/ftpusers hinzu.
2.2.6.4. TCP-Wrapper für die Zugriffskontrolle
2.2.7. Sichern von Sendmail
2.2.7.1. Einschränken von Denial-of-Service-Angriffen
/etc/mail/sendmail.mc mit Grenzwerten versehen, kann die Wirksamkeit solcher Angriffe stark abgeschwächt werden.
confCONNECTION_RATE_THROTTLE— Die Anzahl der Verbindungen, die der Server pro Sekunde empfangen kann. Standardmäßig begrenzt Sendmail die Zahl der Verbindungen nicht. Wird eine Grenze gesetzt, werden darüber hinaus gehende Verbindungen verzögert.confMAX_DAEMON_CHILDREN— Die maximale Anzahl von untergeordneten Prozessen, die vom Server erzeugt werden können. Standardmäßig begrenzt Sendmail die Anzahl der untergeordneten Prozesse nicht. Wird eine Grenze gesetzt, werden alle darüber hinaus gehenden Verbindungen verzögert.confMIN_FREE_BLOCKS— Die minimale Anzahl freier Blöcke, die für den Server zur Verfügung stehen müssen, um E-Mail empfangen zu können. Der Standard beträgt 100 Blöcke.confMAX_HEADERS_LENGTH— Die maximal akzeptierte Größe (in Bytes) für einen Nachrichten-Header.confMAX_MESSAGE_SIZE— Die maximal akzeptierte Größe (in Bytes) pro Nachricht.
2.2.7.2. NFS und Sendmail
/var/spool/mail/, auf einem durch NFS gemeinsam genutzten Datenträger ab.
Anmerkung
SECRPC_GSS-Kernel-Modul keine UID-basierte Authentifizierung anwendet. Allerdings sollten Sie dennoch das Mail-Spool-Verzeichnis nicht auf einem durch NFS gemeinsam genutzten Datenträger ablegen.
2.2.7.3. Nur-Mail Benutzer
/etc/passwd sollten auf /sbin/nologin gesetzt sein (evtl. unter Ausnahme des Root-Benutzers).
2.2.8. Überprüfen der horchenden Ports
netstat -an oder lsof -i abzufragen. Diese Methode ist deshalb unzuverlässiger, da derartige Programme sich nicht vom Netzwerk aus mit dem Computer verbinden, sondern vielmehr prüfen, was auf dem System ausgeführt wird. Aus diesen Grund sind diese Anwendungen häufig Ziel für Ersetzungen durch Angreifer. Bei dieser Methode versuchen Cracker, ihre Spuren zu verwischen, wenn diese unbefugt Netzwerkports geöffnet haben, indem sie die Anwendungen netstat und lsof durch ihre eigenen, modifizierten Versionen ersetzen.
nmap.
nmap -sT -O localhost
Starting Nmap 4.68 ( http://nmap.org ) at 2009-03-06 12:08 EST Interesting ports on localhost.localdomain (127.0.0.1): Not shown: 1711 closed ports PORT STATE SERVICE 22/tcp open ssh 25/tcp open smtp 111/tcp open rpcbind 113/tcp open auth 631/tcp open ipp 834/tcp open unknown 2601/tcp open zebra 32774/tcp open sometimes-rpc11 Device type: general purpose Running: Linux 2.6.X OS details: Linux 2.6.17 - 2.6.24 Uptime: 4.122 days (since Mon Mar 2 09:12:31 2009) Network Distance: 0 hops OS detection performed. Please report any incorrect results at http://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 1.420 seconds
portmap ausführt, da der Dienst sunrpc vorhanden ist. Es wird jedoch auch ein unbekannter Dienst auf Port 834 ausgeführt. Um zu prüfen, ob dieser Port zu der offiziellen Liste bekannter Dienste gehört, geben Sie Folgendes ein:
cat /etc/services | grep 834
netstat oder lsof Informationen über den Port ab. Um Port 834 mithilfe von netstat zu prüfen, geben Sie folgenden Befehl ein:
netstat -anp | grep 834
tcp 0 0 0.0.0.0:834 0.0.0.0:* LISTEN 653/ypbind
netstat aufgeführt wird, ist ein gutes Zeichen, da ein Cracker, der einen Port heimlich auf einem geknackten System öffnet, das Anzeigen des Ports durch diesen Befehl höchstwahrscheinlich nicht zulassen würde. Des Weiteren zeigt die Option [p] die Prozess-ID (PID) des Dienstes an, der diesen Port geöffnet hat. In diesem Fall gehört der offene Port zu ypbind (NIS), ein RPC-Dienst, der zusammen mit dem portmap-Dienst läuft.
lsof-Befehl zeigt ähnliche Informationen wie der netstat-Befehl an, denn er kann offene Ports auch Diensten zuordnen:
lsof -i | grep 834
ypbind 653 0 7u IPv4 1319 TCP *:834 (LISTEN) ypbind 655 0 7u IPv4 1319 TCP *:834 (LISTEN) ypbind 656 0 7u IPv4 1319 TCP *:834 (LISTEN) ypbind 657 0 7u IPv4 1319 TCP *:834 (LISTEN)
lsof, netstat, nmap und services für weitere Informationen.
2.3. TCP-Wrapper und xinetd
iptables-basierte Firewall etwa filtert alle unerwünschten Netzwerkpakete im Netzwerkstapel des Kernels heraus. Für Netzwerkdienste, die davon Gebrauch machen, fügt TCP Wrapper eine zusätzliche Schutzschicht hinzu, indem dieser definiert, welchen Hosts es erlaubt ist mit Netzwerkdiensten zu verbinden, die von TCP Wrappern geschützt werden, und welchen nicht. Einer dieser durch TCP Wrapper geschützten Netzwerkdienste ist der xinetd Super-Server. Dieser Dienst wird Super-Server genannt, da er Verbindungen zu einer Untergruppe von Netzwerkdiensten steuert und die Zugriffskontrolle weiter verfeinert.
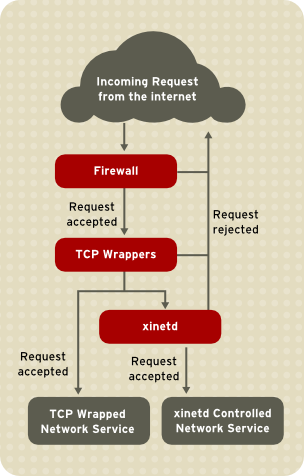
Abbildung 2.4. Zugriffskontrolle zu Netzwerkdiensten
xinetd bei der Zugriffskontrolle auf Netzwerkdienste sowie mit Wegen, wie mithilfe dieser Tools die Verwaltung der Protokollierung und der Anwendung verbessern werden kann. Weitere Informationen zum Einsatz von Firewalls mit iptables finden Sie unter Abschnitt 2.6, »IPTables«.
2.3.1. TCP Wrappers
tcp_wrappers und tcp_wrappers-libs) sind standardmäßig installiert und stellen Host-basierte Zugriffskontrolle für Netzwerkdienste zur Verfügung. Die wichtigste Komponente in diesen Paketen ist die /lib/libwrap.a oder /lib64/libwrap.a-Bibliothek. Im Wesentlichen handelt es sich bei einem von TCP Wrappern kontrollierten Dienst um einen Dienst, der mit der libwrap.a-Bibliothek kompiliert wurde.
/etc/hosts.allow und /etc/hosts.deny) untersuchen um festzustellen, ob eine Verbindung des Clients erlaubt ist. In den meisten Fällen schreibt er anschließend mithilfe des syslog-Daemons (syslogd) den Namen des anfordernden Hosts und Dienstes in /var/log/secure oder /var/log/messages.
libwrap.a-Bibliothek verbunden. Zu diesen Applikationen gehören /usr/sbin/sshd, /usr/sbin/sendmail und /usr/sbin/xinetd.
Anmerkung
libwrap.a verknüpft ist, geben Sie folgenden Befehl als Root-Benutzer ein:
ldd <binary-name> | grep libwrap
libwrap.a verknüpft.
/usr/sbin/sshd mit libwrap.a verknüpft ist:
[root@myServer ~]# ldd /usr/sbin/sshd | grep libwrap
libwrap.so.0 => /lib/libwrap.so.0 (0x00655000)
[root@myServer ~]#2.3.1.1. Vorteile von TCP-Wrappern
- Transparenz für sowohl Client als auch den TCP-wrapped Netzwerkdienst — Weder der sich verbindende Client noch der wrapped Netzwerkdienst merken, dass TCP-Wrapper in Einsatz sind. Verbindungsversuche von berechtigten Benutzern werden protokolliert und mit dem geforderten Dienst verbunden, während Verbindungsversuche unzulässiger Clients fehlschlagen.
- Zentralisierte Verwaltung mehrerer Protokolle — TCP-Wrapper arbeiten unabhängig von den Netzwerkdiensten, die sie schützen. Dadurch können sich mehrere Server-Applikationen einen gemeinsamen Satz von Konfigurationsdateien der Zugriffskontrolle teilen, was die Verwaltung vereinfacht.
2.3.2. TCP-Wrapper Konfigurationsdateien
/etc/hosts.allow/etc/hosts.deny
- Er referenziert
/etc/hosts.allow— Der TCP-wrapped Dienst analysiert die/etc/hosts.allow-Datei sequentiell und wendet die erste Regel an, die für diesen Dienst festgelegt wurde. Wenn eine passende Regel ausfindig gemacht werden kann, erlaubt der Dienst die Verbindung. Wenn nicht, geht er zum nächsten Schritt über. - Er referenziert
/etc/hosts.deny— Der TCP-wrapped Dienst analysiert die/etc/hosts.deny-Datei sequentiell. Wenn eine passende Regel ausfindig gemacht werden kann, lehnt der Dienst die Verbindung ab. Wenn nicht, wird der Zugang zu diesem Dienst bewilligt.
- Da Zugriffsregeln in
hosts.allowzuerst angewendet werden, haben diese Vorrang vor den Regeln inhosts.deny. Sollte der Zugriff zu einem Dienst inhosts.allowerlaubt sein, so wird eine den Zugriff auf diesen Dienst verbietende Regel inhosts.denyignoriert. - Da alle Regeln von oben nach unten abgearbeitet werden, wird lediglich die erste auf einen Dienst passende Regel angewendet, weshalb die Reihenfolge der Regeln extrem wichtig ist.
- Sollte keine Regel für den Dienst gefunden werden oder keine der beiden Dateien vorhanden sein, so wird der Zugriff zu diesem Dienst gewährt.
- TCP-wrapped Dienste speichern Regeln für die Hosts-Zugriffsdateien nicht zwischen. Jegliche Änderungen an
hosts.allowoderhosts.denytreten daher auch ohne Neustart der Netzwerkdienste sofort in Kraft.
Warnung
/var/log/messages oder /var/log/secure protokolliert. Dies ist auch der Fall für Regeln, die ohne Backslash-Zeichen auf mehrere Zeilen umgebrochen sind. Das folgende Beispiel zeigt den relevanten Teil einer Protokollmeldung für eine durch genannte Gründe fehlerhafte Regel:
warning: /etc/hosts.allow, line 20: missing newline or line too long
2.3.2.1. Formatierung von Zugriffsregeln
/etc/hosts.allow and /etc/hosts.deny ist identisch. Jede Regel muss in einer neuen Zeile beginnen. Leere Zeilen oder Zeilen, die mit dem Rautenzeichen (#) beginnen, werden ignoriert.
<daemon list>: <client list> [: <option>: <option>: ...]
- <daemon list> — Eine kommagetrennte Liste mit Prozessnamen (nicht Dienstnamen) oder der
ALL-Platzhalter. Die Daemon-Liste akzeptiert auch Operatoren (siehe Abschnitt 2.3.2.1.4, »Operatoren«) für größere Flexibilität. - <client list> — Eine kommagetrennte Liste mit Hostnamen, Host-IP-Adressen, bestimmten Zeichenketten oder Platzhaltern, die die von der Regel betroffenen Hosts spezifizieren. Die Client-Liste akzeptiert auch Operatoren (siehe Abschnitt 2.3.2.1.4, »Operatoren«) für größere Flexibilität.
- <option> — Eine optionale Aktion oder durch Doppelpunkte getrennte Liste von Aktionen, die ausgeführt werden, wenn eine Regel angewendet wird. Optionsfelder unterstützen Expansionen, führen Shell-Befehle aus, gewähren Zugriff oder lehnen diesen ab, und ändern das Protokollierungsverhalten.
Anmerkung
vsftpd : .example.com
vsftpd) von jedem Host in der example.com-Domain Ausschau zu halten. Wird diese Regel in hosts.allow eingefügt, so wird die Verbindung angenommen. Wird diese Regel dagegen in hosts.deny eingefügt, so wird die Verbindung abgelehnt.
sshd : .example.com \ : spawn /bin/echo `/bin/date` access denied>>/var/log/sshd.log \ : deny
sshd) von einem Host in der example.com-Domain der echo-Befehl ausgeführt wird (der den Verbindungsversuch in eine spezielle Protokolldatei schreibt) und die Verbindung abgelehnt wird. Da die optionale deny-Direktive verwendet wird, wird diese Zeile den Zugriff ablehnen, auch wenn sie in der hosts.allow-Datei erscheint. Für einen detaillierteren Überblick der Optionen, siehe Abschnitt 2.3.2.2, »Optionsfelder«.
2.3.2.1.1. Platzhalter
ALL— Stimmt mit allen Werten überein. Kann sowohl für die Daemon-Liste als auch für die Client-Liste verwendet werden.LOCAL— Stimmt mit jedem Host überein, der keinen Punkt (.) enthält, wie z. B. localhost.KNOWN— Stimmt mit jedem Host überein, dessen Host-Name und Host-Adresse oder der Benutzer bekannt sind.UNKNOWN— Stimmt mit jedem Host überein, dessen Host-Name und Host-Adresse oder der Benutzer unbekannt sind.PARANOID— Stimmt mit jedem Host überein, dessen Host-Name nicht mit der Host-Adresse übereinstimmt.
Wichtig
KNOWN, UNKNOWN und PARANOID sollten mit Vorsicht verwendet werden, da deren ordnungsgemäßer Betrieb von einem funktionierenden DNS-Server abhängt. Ein Problem bei der Namensauflösung kann eine Zugriffsverweigerung auf Dienste für berechtigte Benutzer zur Folge haben.
2.3.2.1.2. Muster
- Hostname beginnt mit einem Punkt (.) — Ein Punkt am Anfang eines Host-Namens bewirkt, dass auf alle Host-Rechner, die in diesem Hostnamen enden, die Regel angewendet wird. Das folgende Beispiel trifft auf jeden Host in der
example.comDomain zu:ALL : .example.com
- IP-Adresse endet mit einem Punkt (.) — Ein Punkt am Ende einer IP-Adresse bewirkt, dass auf alle Hosts, deren IP-Adresse mit derselben numerischen Gruppe beginnt, die Regel angewendet wird. Das folgende Beispiel trifft auf jeden Host im
192.168.x.x-Netzwerk zu:ALL : 192.168.
- IP-Adresse/Netzmaske-Paar — Netzmasken-Ausdrücke können auch als ein Muster verwendet werden, um den Zugriff zu einer bestimmten Gruppe von IP-Adressen zu regeln. Das folgende Beispiel trifft auf alle Hosts mit einer Adresse zwischen
192.168.0.0und192.168.1.255zu:ALL : 192.168.0.0/255.255.254.0
Wichtig
Wenn im IPv4-Adressraum gearbeitet wird, werden paarweise Deklarationen von Adresse/Präfixlänge (prefixlen) (CIDR-Notation) nicht unterstützt. Lediglich IPv6-Regeln können dieses Format verwenden. - [IPv6 Adresse]/prefixlen Paar — [net]/prefixlen Paare können auch als Muster verwendet werden, um den Zugriff zu einer bestimmten Gruppe von IPv6-Adressen zu regeln. Das folgende Beispiel trifft auf jeden Host mit einem Adressbereich von
3ffe:505:2:1::bis3ffe:505:2:1:ffff:ffff:ffff:ffffzu:ALL : [3ffe:505:2:1::]/64
- Ein Sternchen (*) — Sternchen können für komplette Gruppen von Host-Namen oder IP-Adressen verwendet werden, solange diese nicht in einer Client-Liste verwendet werden, die bereits andere Arten von Muster verwendet. Das folgende Beispiel trifft auf alle Hosts in der
example.com-Domain zu:ALL : *.example.com
- Der Schrägstrich (/) — Wenn die Client-Liste mit einem Schrägstrich beginnt, wird diese als Dateiname behandelt. Dies ist nützlich, wenn Regeln benötigt werden, die eine große Anzahl von Hosts angeben. Das folgende Beispiel verweist TCP-Wrapper auf die
/etc/telnet.hosts-Datei für alle Telnet-Verbindungen:in.telnetd : /etc/telnet.hosts
hosts_access(5)-Handbuchseite.
Warnung
2.3.2.1.3. Portmap und TCP Wrappers
Portmaps Implementierung von TCP-Wrappern unterstützt keine Namensauflösung, was bedeutet, dass portmap keine Host-Namen zur Identifizierung von Hosts verwenden kann. Daher müssen Regeln für die Zugriffskontrolle für Portmap in hosts.allow oder hosts.deny IP-Adressen oder den Schlüsselbegriff ALL für die Spezifizierung von Hosts verwenden.
portmap-Zugriffskontrollregeln werden nicht sofort wirksam. Sie müssen ggf. den portmap-Dienst neu starten.
portmap abhängt, bedenken Sie diese Einschränkungen.
2.3.2.1.4. Operatoren
EXCEPT. Dieser kann sowohl in der Daemon- als auch in der Client-Liste einer Regel verwendet werden.
EXCEPT-Operator erlaubt spezifische Ausnahmen an breiter gefächerten Treffern in einer Regel.
hosts.allow-Datei ist es allen example.com Hosts gestattet, sich mit allen Diensten mit Ausnahme von cracker.example.com zu verbinden:
ALL: .example.com EXCEPT cracker.example.com
hosts.allow-Datei können Clients des 192.168.0.x-Netzwerks alle Dienste benutzen, mit der Ausnahme von FTP:
ALL EXCEPT vsftpd: 192.168.0.
Anmerkung
EXCEPT-Operatoren zu vermeiden. Dadurch können andere Administratoren schnell die gewünschten Dateien durchsuchen, um zu sehen, welche Hosts Zugriff und welche keinen Zugriff auf bestimmte Dienste haben sollen, ohne dass mehrere EXCEPT-Operatoren berücksichtigt werden müssen.
2.3.2.2. Optionsfelder
2.3.2.2.1. Protokollierung
severity-Direktive verwendet wird.
example.com-Domain in die standardmäßige Protokoll-Facility authpriv syslog geschrieben (da kein Facility-Wert angegeben ist), und dies mit einer Priorität von emerg:
sshd : .example.com : severity emerg
severity-Option anzugeben. Das folgende Beispiel protokolliert alle SSH-Verbindungsversuche von Hosts aus der example.com-Domain zur local0-Facility, mit einer Priorität von alert:
sshd : .example.com : severity local0.alert
Anmerkung
syslogd) nicht dazu konfiguriert ist, an die local0-Facility zu protokollieren. Weitere Informationen zur Konfiguration von benutzerdefinierten Facilitys finden Sie auf der syslog.conf-Handbuchseite.
2.3.2.2.2. Zugriffskontrolle
allow oder deny-Direktive als letzte Option hinzufügen.
client-1.example.com, lehnen aber Verbindungsversuche von client-2.example.com ab:
sshd : client-1.example.com : allow sshd : client-2.example.com : deny
hosts.allow oder in hosts.deny. Einige Administratoren finden diese Art, die Zugriffsregeln zu organisieren, einfacher.
2.3.2.2.3. Shell-Befehle
spawn— Startet einen Shell-Befehl als untergeordneten Prozess. Diese Direktive kann Aufgaben wie/usr/sbin/safe_fingerdurchführen, um weitere Informationen über den anfragenden Client zu erhalten oder spezielle Protokolldateien mit demecho-Befehl erzeugen.Im folgenden Beispiel werden Clients, die von derexample.com-Domain aus auf einen Telnet-Dienst zuzugreifen versuchen, unbemerkt in einer speziellen Protokolldatei aufgezeichnet:in.telnetd : .example.com \ : spawn /bin/echo `/bin/date` from %h>>/var/log/telnet.log \ : allow
twist— Ersetzt den angeforderten Dienst durch den angegebenen Befehl. Diese Direktive wird oft verwendet, um Fallen für potenzielle Eindringlinge zu stellen. Es kann auch dazu verwendet werden, um Nachrichten an verbindende Clients zu senden. Dietwist-Direktive muss am Ende der Regelzeile stehen.Im folgenden Beispiel wird Clients, die von derexample.com-Domain aus auf einen FTP-Dienst zuzugreifen versuchen, mithilfe desecho-Befehls eine Nachricht gesendet:vsftpd : .example.com \ : twist /bin/echo "421 This domain has been black-listed. Access denied!"
hosts_options Handbuchseite.
2.3.2.2.4. Erweiterungen
spawn und twist-Direktiven verwendet werden, liefern Informationen über den Client, den Server sowie die beteiligten Prozesse.
%a— Die IP-Adresse des Clients.%A— Die IP-Adresse des Servers.%c— Verschiedene Client-Informationen, wie zum Beispiel der Benutzer- und Host-Name oder der Benutzername und die IP-Adresse.%d— Der Name des Daemon-Prozesses.%h— Der Host-Name des Clients (oder IP-Adresse, wenn der Host-Name nicht verfügbar ist).%H— Der Host-Name des Servers (oder IP-Adresse, wenn der Host-Name nicht verfügbar ist).%n— Der Host-Name des Clients. Wenn dieser nicht verfügbar ist, so wirdunknownausgegeben. Wenn der Host-Name und die Host-Adresse des Clients nicht übereinstimmen, wirdparanoidausgegeben.%N— Der Host-Name des Servers. Wenn dieser nicht verfügbar ist, wirdunknownausgegeben. Wenn der Host-Name und die Host-Adresse des Servers nicht übereinstimmen, wirdparanoidausgegeben.%p— Die ID des Daemon-Prozesses.%s— Verschiedene Server-Informationen, wie zum Beispiel der Daemon-Prozess und die Host- oder IP-Adresse des Servers.%u— Der Benutzername des Clients. Wenn dieser nicht verfügbar ist, wirdunknownausgegeben.
spawn-Befehl, um den Client-Host in einer benutzerdefinierten Protokolldatei zu identifizieren.
sshd) von einem Host in der example.com-Domain unternommen werden, führen Sie den echo-Befehl aus, um den Versuch in eine spezielle Protokolldatei zu schreiben, einschließlich des Host-Namens des Clients (unter Verwendung der %h-Erweiterung):
sshd : .example.com \ : spawn /bin/echo `/bin/date` access denied to %h>>/var/log/sshd.log \ : deny
example.com-Domain aus zuzugreifen versuchen, mitgeteilt, dass diese vom Server ausgeschlossen wurden:
vsftpd : .example.com \ : twist /bin/echo "421 %h has been banned from this server!"
hosts_access (man 5 hosts_access) sowie der Handbuchseite für hosts_options.
2.3.3. xinetd
xinetd-Daemon ist ein TCP-wrapped Super-Dienst, der den Zugriff auf eine Reihe gängiger Netzwerkdienste wie FTP, IMAP und Telnet steuert. Er bietet außerdem dienstspezifische Konfigurationsoptionen zur Zugriffskontrolle, erweiterte Protokollierung, Binding, Umleitungen sowie Ressourcenverwaltung.
xinetd gesteuerten Netzwerkdienst unternimmt, so erhält der Super-Dienst die Anfrage und prüft auf Zugriffskontrollregeln der TCP-Wrapper.
xinetd, dass die Verbindung unter den eigenen Zugriffsregeln für diesen Dienst gestattet ist. Es wird auch geprüft, ob dem Dienst mehr Ressourcen zugewiesen werden können und dass keine definierten Regeln verletzt werden.
xinetd eine Instanz des angefragten Dienstes und gibt die Kontrolle über die Verbindung daran ab. Sobald die Verbindung besteht, greift xinetd nicht weiter in die Kommunikation zwischen Client Host und Server ein.
2.3.4. xinetd-Konfigurationsdateien
xinetd lauten wie folgt:
/etc/xinetd.conf— Die allgemeinexinetd-Konfigurationsdatei./etc/xinetd.d/— Das Verzeichnis, das alle dienstspezifischen Dateien enthält.
2.3.4.1. Die /etc/xinetd.conf-Datei
/etc/xinetd.conf-Datei enthält allgemeine Konfigurationseinstellungen, die sich auf jeden Dienst unter der Kontrolle von xinetd auswirken. Bei jedem Start des xinetd-Dienstes wird diese Datei gelesen. Damit Konfigurationsänderungen wirksam werden, muss der Administrator den xinetd-Dienst also neu starten. Nachfolgend sehen Sie ein Beispiel für eine /etc/xinetd.conf-Datei:
defaults
{
instances = 60
log_type = SYSLOG authpriv
log_on_success = HOST PID
log_on_failure = HOST
cps = 25 30
}
includedir /etc/xinetd.dxinetd:
instances— Legt die Höchstzahl von Anfragen fest, diexinetdgleichzeitig bearbeiten kann.log_type— Weistxinetdan, dieauthpriv-Facillity zu verwenden, die Protokolleinträge in die/var/log/secure-Datei schreibt. Das Hinzufügen einer Direktive wieFILE /var/log/xinetdlogwürde eine benutzerdefinierte Protokolldatei mit dem Namenxinetdlogim/var/log/-Verzeichnis erstellen.log_on_success— Weistxinetddazu an, erfolgreiche Verbindungsversuche zu protokollieren. Standardmäßig werden die Remote-Host-IP-Adresse und die ID des Servers, der die Anfrage verarbeitet, aufgezeichnet.log_on_failure— Weistxinetddazu an, fehlgeschlagene oder abgewiesene Verbindungsversuche zu protokollieren.cps— Weistxinetddazu an, für einen bestimmten Dienst nicht mehr als 25 Verbindungen pro Sekunde zuzulassen. Wenn diese Grenze erreicht ist, wird der Dienst für 30 Sekunden ausgesetzt.includedir/etc/xinetd.d/— Enthält Optionen der dienstspezifischen Konfigurationsdateien im Verzeichnis/etc/xinetd.d/. Weitere Informationen zu diesem Verzeichnis finden Sie unter Abschnitt 2.3.4.2, »Das /etc/xinetd.d/-Verzeichnis«.
Anmerkung
log_on_success und log_on_failure in /etc/xinetd.conf werden oftmals von den dienstspezifischen Protokolldateien geändert. Aus diesem Grund können mehr Informationen in der Protokolldatei eines Dienstes angezeigt werden, als die /etc/xinetd.conf-Datei angibt. Weitere Informationen diesbezüglich finden Sie unter Abschnitt 2.3.4.3.1, »Protokolloptionen«.
2.3.4.2. Das /etc/xinetd.d/-Verzeichnis
/etc/xinetd.d/-Verzeichnis enthält die Konfigurationsdateien für jeden einzelnen Dienst, der von xinetd verwaltet wird sowie die Namen der Dateien, die mit dem Dienst zusammenhängen. Wie auch xinetd.conf wird diese Datei nur gelesen, wenn der xinetd-Dienst gestartet wird. Um Änderungen wirksam werden zu lassen, muss der Administrator den xinetd-Dienst daher neu starten.
/etc/xinetd.d/-Verzeichnis verwenden dieselben Konventionen und Optionen wie /etc/xinetd.conf. Der Hauptgrund dafür, dass sich diese in eigenen Konfigurationsdateien befinden, ist zur einfacheren Anpassung und um Auswirkungen auf andere Dienste möglichst zu vermeiden.
/etc/xinetd.d/krb5-telnet:
service telnet
{
flags = REUSE
socket_type = stream
wait = no
user = root
server = /usr/kerberos/sbin/telnetd
log_on_failure += USERID
disable = yes
}telnet-Dienstes:
service— Definiert den Dienstnamen, meist einer der in der/etc/services-Datei aufgeführten.flags— Legt eine beliebiege Anzahl von Parametern für die Verbindung fest.REUSEweistxinetdan, den Socket für eine Telnet-Verbindung wiederzuverwenden.Anmerkung
DasREUSE-Flag ist veraltet. Alle Dienste verwenden jetzt implizit dasREUSE-Flag.socket_type— Setzt den Netzwerk-Sockettyp aufstream.wait— Legt fest, ob der Dienst "einthreadig" (yes) oder "mehrthreadig" (no) ist.user— Legt fest, unter welcher Benutzer-ID der Prozess abläuft.server— Legt die auszuführende Binärdatei fest.log_on_failure— Bestimmt die Protokollparameter fürlog_on_failurezusätzlich zu den inxinetd.confbereits definierten.disable— Legt fest, ob der Dienst deaktiviert (yes) oder aktiviert (no) ist.
xinetd.conf Handbuchseite.
2.3.4.3. Änderungen an xinetd-Konfigurationsdateien
xinetd geschützte Dienste. Dieser Abschnitt beschreibt einige der häufig verwendeten Optionen.
2.3.4.3.1. Protokolloptionen
/etc/xinetd.conf und die dienstspezifischen Konfigurationsdateien im /etc/xinetd.d/-Verzeichnis zur Verfügung.
ATTEMPT— Protokolliert einen fehlgeschlagenen Versuch (log_on_failure).DURATION— Protokolliert, wie lange ein Remote-System einen Dienst nutzt (log_on_success).EXIT— protokolliert den Exit-Status oder das Endsignal des Dienstes (log_on_success).HOST— Protokolliert die IP-Adresse des Remote-Host-Rechners (log_on_failureundlog_on_success).PID— Protokolliert die Prozess-ID des Servers, an den die Anfrage gesendet wird (log_on_success).USERID— Protokolliert den Remote-Benutzer mithilfe der in RFC 1413 definierten Methode für alle mehrthreadigen Stream-Dienste (log_on_failureundlog_on_success).
xinetd.conf Handbuchseite.
2.3.4.3.2. Zugriffskontroll-Optionen
xinetd-Diensten können wählen, ob sie die Host-Zugriffskontrolldateien der TCP-Wrapper, Zugriffskontrolle mittels der xinetd-Konfigurationsdateien oder eine Kombination aus beidem verwenden wollen. Informationen zum Gebrauch von Host-Zugriffskontrolldateien der TCP-Wrapper finden Sie in Abschnitt 2.3.2, »TCP-Wrapper Konfigurationsdateien«.
xinetd für die Kontrolle von Zugriffen auf bestimmte Dienste behandelt.
Anmerkung
xinetd-Administrator nach jeder Änderung den xinetd-Dienst neu starten, damit diese wirksam werden.
xinetd lediglich die Dienste, die durch xinetd kontrolliert werden.
xinetd-Host-Zugriffskontrolle unterscheidet sich von der von TCP-Wrappern verwendeten Methode. Während TCP-Wrapper die gesamte Zugriffskonfiguration in zwei Dateien ablegt, /etc/hosts.allow und /etc/hosts.deny, befindet sich die xinetd-Zugriffskontrolle in den jeweiligen Dienstkonfigurationsdateien im /etc/xinetd.d/-Verzeichnis.
xinetd für die Host-Zugriffskontrolle unterstützt:
only_from— Erlaubt nur den aufgeführten Host-Rechnern den Zugriff auf den Dienst.no_access— Verwehrt den aufgeführten Host-Rechnern den Zugriff auf den Dienst.access_times— Der Zeitraum, in dem ein bestimmter Dienst verwendet werden darf. Der Zeitraum muss im 24-Stunden-Format, also HH:MM-HH:MM, angegeben werden.
only_from und no_access können eine Liste von IP-Adressen oder Hostnamen verwenden, oder ein gesamtes Netzwerk referenzieren. Wie TCP-Wrapper kann durch die Kombination der xinetd-Zugriffskontrolle und der entsprechenden Protokollkonfiguration die Sicherheit durch das Abweisen von Anfragen von gesperrten Hosts und das Protokollieren aller Verbindungsversuche erhöht werden.
/etc/xinetd.d/telnet-Datei verwendet werden, um den Telnet-Zugriff von einer bestimmten Netzwerkgruppe auf ein System zu verweigern und um die Zeitspanne, die selbst erlaubte Benutzer angemeldet sein dürfen, einzuschränken:
service telnet
{
disable = no
flags = REUSE
socket_type = stream
wait = no
user = root
server = /usr/kerberos/sbin/telnetd
log_on_failure += USERID
no_access = 172.16.45.0/24
log_on_success += PID HOST EXIT
access_times = 09:45-16:15
}172.16.45.0/24-Netzwerk wie etwa von 172.16.45.2 versucht, auf den Telnet-Dienst zuzugreifen, erhält es die folgende Meldung:
Connection closed by foreign host.
/var/log/messages protokolliert:
Sep 7 14:58:33 localhost xinetd[5285]: FAIL: telnet address from=172.16.45.107 Sep 7 14:58:33 localhost xinetd[5283]: START: telnet pid=5285 from=172.16.45.107 Sep 7 14:58:33 localhost xinetd[5283]: EXIT: telnet status=0 pid=5285 duration=0(sec)
xinetd verwenden, müssen Sie die Beziehung dieser beiden Zugriffskontroll-Mechanismen zueinander verstehen.
xinetd-Vorgänge beschrieben, wenn ein Client eine Verbindung anfordert:
- Der
xinetd-Daemon greift auf die Host-Zugriffsregeln der TCP-Wrapper durch einenlibwrap.a-Bibliotheksaufruf zu. Besteht eine Deny-Regel für den Client, so wird die Verbindung nicht aufgebaut. Besteht eine Allow-Regel für den Client, wird die Verbindung anxinetdweitergegeben. - Der
xinetd-Daemon überprüft seine eigenen Zugriffskontrollregeln für denxinetd-Dienst und den angeforderten Dienst. Besteht eine Deny-Regel für den Client, wird die Verbindung nicht aufgebaut. Andernfalls startetxinetdeine Instanz des angeforderten Dienstes und gibt die Kontrolle über die Verbindung an diesen weiter.
Wichtig
xinetd-Zugriffskontrollen. Eine Fehlkonfiguration kann unerwünschte Auswirkungen haben.
2.3.4.3.3. Bindungs- und Umleitungsoptionen
xinetd unterstützen auch die Bindung des Dienstes an eine bestimmte IP-Adresse und Umleitung der eingehenden Anfragen für diesen Dienst an andere IP-Adressen, Hostnamen oder Ports.
bind-Option in den Dienstkonfigurationsdateien gesteuert und verknüpft den Dienst mit einer IP-Adresse auf dem System. Nach der Konfiguration lässt die bind-Option nur Anfragen für die richtige IP-Adresse zum Zugriff auf den Dienst zu. Auf diese Weise kann jeder Dienst je nach Bedarf an verschiedene Netzwerkschnittstellen gebunden werden.
redirect-Option akzeptiert eine IP-Adresse oder einen Hostnamen gefolgt von einer Portnummer. Sie konfiguriert den Dienst, um alle Anfragen für diesen Dienst an eine bestimmte Adresse und Portnummer weiterzuleiten. Diese Option kann verwendet werden, um auf eine andere Portnummer auf demselben System zu verweisen, die Anfrage an eine andere IP-Adresse auf demselben Rechner weiterzuleiten, die Anfrage an ein anderes System oder eine andere Portnummer zu verschieben, oder aber eine Kombination all dieser Optionen. Auf diese Weise kann ein Benutzer, der sich für einen bestimmten Dienst an einem System anmeldet, ohne Unterbrechung umgeleitet werden.
xinetd-Daemon kann diese Umleitung durch Erzeugen eines Prozesses ausführen, der während der Verbindung des anfragenden Client-Rechners mit dem Host-Rechner, der den eigentlichen Dienst liefert, im Stay-Alive-Modus läuft und Daten zwischen den zwei Systemen austauscht.
bind und redirect-Optionen liegt in deren kombinierter Verwendung. Durch Bindung eines Dienstes an eine bestimmte IP-Adresse auf einem System und dem darauffolgenden Umleiten der Anfragen für denselben Dienst an einen zweiten Rechner, der nur für den ersten Rechner sichtbar ist, können Sie ein internes System verwenden, um Dienste für vollkommen unterschiedliche Netzwerke zur Verfügung zu stellen. Alternativ können diese Optionen verwendet werden, damit ein Dienst auf einem Multihomed-Rechner weniger einer bekannten IP-Adresse ausgesetzt ist, und um jegliche Anfragen für diesen Dienst an einen anderen Rechner weiterzuleiten, der eigens für diesen Zweck konfiguriert ist.
service telnet
{
socket_type = stream
wait = no
server = /usr/kerberos/sbin/telnetd
log_on_success += DURATION USERID
log_on_failure += USERID
bind = 123.123.123.123
redirect = 10.0.1.13 23
}bind und redirect-Optionen in dieser Datei stellen sicher, dass der Telnet-Dienst auf dem Rechner an eine externe IP-Adresse (123.123.123.123) gebunden ist, und zwar die Internet-seitige. Außerdem werden alle an 123.123.123.123 gesendeten Telnet-Anfragen über einen zweiten Netzwerkadapter an eine interne IP-Adresse (10.0.1.13) weitergeleitet, auf die nur die Firewall und interne Systeme Zugriff haben. Die Firewall sendet dann die Kommunikation von einem System an das andere, und für das sich verbindende System sieht es so aus, als ob es mit 123.123.123.123 verbunden sei, während es in Wirklichkeit mit einem anderen Rechner verbunden ist.
xinetd kontrolliert werden, mit den Optionen bind und redirect konfiguriert sind, kann der Gateway-Rechner als eine Art Proxy zwischen externen Systemen und einem bestimmten internen Rechner fungieren, der konfiguriert ist, um den Dienst breitzustellen. Außerdem sind die verschiedenen xinetd-Zugriffskontroll- und Protokollierungsoptionen auch für zusätzlichen Schutz verfügbar.
2.3.4.3.4. Optionen zur Ressourcenverwaltung
xinetd-Daemon kann einen einfachen Grad an Schutz vor Denial of Service (DoS) Angriffen bieten. Untenstehend finden Sie eine Liste an Direktiven, welche die Auswirkung dieser Angriffe abschwächen können:
per_source— Legt die Höchstanzahl von Verbindungen von einer bestimmen IP-Adresse mit einem bestimmen Dienst fest. Es werden nur ganzzahlige Werte als Parameter akzeptiert. Diese Direktive kann sowohl inxinetd.confals auch in den dienstspezifischen Konfigurationsdateien imxinetd.d/-Verzeichnis verwendet werden.cps— Legt die Höchstzahl der Verbindungen pro Sekunde fest. Diese Option akzeptiert zwei ganzzahlige Parameter getrennt durch eine Leerstelle. Die erste Zahl ist die Höchstzahl von Verbindungen zum Dienst pro Sekunde. Die zweite Zahl ist die Anzahl der Sekunden, diexinetdwarten muss, bis der Dienst erneut aktiviert wird. Es werden nur ganzzahlige Werte als Parameter akzeptiert. Diese Direktive kann sowohl inxinetd.confals auch in den dienstspezifischen Konfigurationsdateien imxinetd.d/-Verzeichnis verwendet werden.max_load— Legt den Schwellenwert für die CPU-Nutzung oder durchschnittliche Auslastung eines Dienstes fest. Es akzeptiert deine Gleitkommazahl als Parameter.Die durchschnittliche Auslastung ist ein ungefähres Maß dafür, wie viele Prozesse zu einem bestimmten Zeitpunkt aktiv sind. Weitere Informationen zur durchschnittlichen Auslastung finden Sie unter denuptime,whoundprocinfo-Befehlen.
xinetd. Auf der xinetd.conf Handbuchseite finden Sie weitere Informationen diesbezüglich.
2.3.5. Zusätzliche Informationsquellen
xinetd finden Sie in der Systemdokumentation und im Internet.
2.3.5.1. Installierte TCP-Wrapper-Dokumentation
xinetd und zur Zugriffskontrolle suchen.
/usr/share/doc/tcp_wrappers-<version>/— Dieses Verzeichnis enthält eineREADME-Datei, in der die Funktionsweise von TCP-Wrappern und die verschiedenen Hostname- und Hostadress-Spoofing-Risiken beschrieben werden./usr/share/doc/xinetd-<version>/— Dieses Verzeichnis enthält eineREADME-Datei, in der Aspekte der Zugriffskontrolle beschrieben sind und einesample.conf-Datei mit verschiedenen Ideen zum Bearbeiten der Konfigurationsdateien im/etc/xinetd.d/-Verzeichnis.- Handbuchseiten zu TCP-Wrappern und
xinetd— Es gibt eine Reihe von Handbuchseiten für die verschiedenen Applikationen und Konfigurationsdateien rund um TCP-Wrapper undxinetd. Die folgende Liste benennt einige der wichtigeren Handbuchseiten.- Server-Applikationen
man xinetd— Die Handbuchseite fürxinetd.
- Konfigurationsdateien
man 5 hosts_access— Die Handbuchseite für die Hosts-Zugriffskontrolldateien der TCP-Wrapper.man hosts_options— Die Handbuchseite für die Optionsfelder der TCP-Wrapper.man xinetd.conf— Die Handbuchseite mit einer Liste derxinetd-Konfigurationsoptionen.
2.3.5.2. Hilfreiche TCP-Wrapper-Websites
- http://www.docstoc.com/docs/2133633/An-Unofficial-Xinetd-Tutorial — Eine ausführliche Anleitung, in der viele Möglichkeiten beschrieben werden, standardmäßige
xinetd-Konfigurationsdateien für bestimmte Sicherheitsanforderungen anzupassen.
2.3.5.3. Bücher zum Thema
- Hacking Linux Exposed von Brian Hatch, James Lee und George Kurtz; Osbourne/McGraw-Hill — Eine exzellente Informationsquelle zu TCP-Wrappern und
xinetd.
2.4. Virtual Private Networks (VPNs)
2.4.1. Funktionsweise eines VPNs
2.4.2. Openswan
2.4.2.1. Überblick
Openswan ist eine quelloffene IPsec-Implementierung auf Kernel-Ebene in Red Hat Enterprise Linux. Es setzt die IKE-Protokolle (Internet Key Exchange) v1 und v2 zur Schlüsselverwaltung ein, implementiert als Daemons auf Benutzerebene. Manuelle Einrichtung von Schlüsseln ist ebenfalls möglich mittels der ip xfrm Befehle, dies wird jedoch nicht empfohlen.
Openswan verfügt über eine integrierte kryptografische Bibliothek, unterstützt jedoch auch eine NSS (Network Security Services) Bibliothek, die vollständig unterstützt wird und zur Einhaltung der FIPS-Sicherheitsstandards notwendig ist. Weitere Informationen über FIPS (Federal Information Processing Standard) finden Sie unter Abschnitt 7.2, »Federal Information Processing Standard (FIPS)«.
Führen Sie den Befehl yum install openswan aus, um Openswan zu installieren.
2.4.2.2. Konfiguration
Dieser Abschnitt erläutert die Dateien und Verzeichnisse, die zur Konfiguration von Openswan wichtig sind.
/etc/ipsec.d- Hauptverzeichnis. Speichert die Dateien im Zusammenhang mit Openswan./etc/ipsec.conf- Hauptkonfigurationsdatei. Weitere*.conf-Konfigurationsdateien für individuelle Konfigurationen können in/etc/ipsec.derstellt werden./etc/ipsec.secrets- Hauptgeheimnisdatei. Weitere*.secrets-Dateien für individuelle Konfigurationen können in/etc/ipsec.derstellt werden./etc/ipsec.d/cert*.db- Zertifikatsdatenbankdateien. Die alte standardmäßige NSS-Datenbankdatei istcert8.db. Ab Red Hat Enterprise Linux 6 werden NSS SQLite-Datenbanken in dercert9.db-Datei verwendet./etc/ipsec.d/key*.db- Schlüssedatenbankdateien. Die alte standardmäßige NSS-Datenbankdatei istkey3.db. Ab Red Hat Enterprise Linux 6 werden NSS SQLite-Datenbanken in dercert9.db-Datei verwendet./etc/ipsec.d/cacerts- Speicherort für Zertifikate von Zertifikatsstellen (auch Certificate Authorities, kurz CA)./etc/ipsec.d/certs- Speicherort für Benutzerzertifikate. Nicht notwendig bei der Verwendung von NSS./etc/ipsec.d/policies- Gruppenrichtlinien. Richtlinien können als block, clear, clear-or-private, private oder private-or-clear definiert werden./etc/ipsec.d/nsspassword- NSS-Passwortdatei. Diese Datei ist standardmäßig nicht vorhanden, wird jedoch benötigt, falls die NSS-Datenbank mit einem Passwort erstellt wird.
Dieser Abschnitt listet einige der verfügbaren Konfigurationsoptionen auf, von denen die meisten in /etc/ipsec.conf gespeichert werden.
protostack- definert den verwendeten Protokollstapel. Die standardmäßige Option in Red Hat Enterprise Linux 6 ist netkey. Andere gültige Werte sind auto, klips und mast.nat_traversal- definiert, ob NAT für Verbindungen akzeptiert wird. Standardmäßig ist dies nicht der Fall.dumpdir- definiert den Speicherort für Speicherauszugsdateien.nhelpers- falls NSS eingesetzt wird, definiert dies die Anzahl der Threads, die für kryptografische Operationen verwendet werden. Falls NSS nicht eingesetzt wird, definiert dies die Anzahl der Prozesse, die für kryptografische Operationen verwendet werden.virtual_private- erlaubte Subnetze für die Client-Verbindung. Bereiche, die sich hinter einem NAT-Router befinden können, über den ein Client verbindet.plutorestartoncrash- standardmäßig auf "yes" gesetzt.plutostderr- Pfad zum Puto-Fehlerprotokoll. Verweist standardmäßig auf den syslog-Speicherort.connaddrfamily- kann entweder auf ipv4 oder ipv6 gesetzt werden.
ipsec.conf(5)-Handbuchseite.
2.4.2.3. Befehle
Anmerkung
service ipsec start/stop empfohlen, um den Status des ipsec-Dienstes zu ändern. Dies ist auch die empfohlene Methode zum Starten und Stoppen aller anderen Dienste in Red Hat Enterprise Linux 6.
- Starten und Stoppen von Openswan:
ipsec setup start/stopservice ipsec start/stop
- Hinzufügen und Löschen einer Verbindung:
ipsec auto --add/delete <connection name>
- Erstellen und Abbrechen einer Verbindung
ipsec auto --up/down <connection-name>
- Generieren von RSA-Schlüsseln:
ipsec newhostkey --configdir /etc/ipsec.d --password password --output /etc/ipsec.d/<name-of-file>
- Überprüfen von ipsec-Richtlinien im Kernel:
ip xfrm policyip xfrm state
- Erstellen eines selbst signierten Zertifikats:
certutil -S -k rsa -n <ca-cert-nickname> -s "CN=ca-cert-common-name" -w 12 -t "C,C,C" -x -d /etc/ipsec.d
- Erstellen von Benutzerzertifikaten signiert durch die vorherige CA:
certutil -S -k rsa -c <ca-cert-nickname> -n <user-cert-nickname> -s "CN=user-cert-common-name" -w 12 -t "u,u,u" -d /etc/ipsec.d
2.4.2.4. Informationsquellen zu Openswan
- Das Openswan-doc-Paket: HTML, Beispiele, README.*
- README.nss
2.5. Firewalls
Tabelle 2.2. Firewall-Typen
| Methode | Beschreibung | Vorteile | Nachteile | ||||||
|---|---|---|---|---|---|---|---|---|---|
| NAT | Network Address Translation (NAT) platziert private IP-Subnetzwerke hinter eine einzige oder eine kleine Gruppe von externen IP-Adressen, wodurch alle Anfragen wie von einer Quelle erscheinen statt von mehreren. Der Linux-Kernel hat eine integrierte NAT-Funktionalität durch das Netfilter-Kernel-Subsystem. |
|
| ||||||
| Paketfilter | Paketfilter-Firewalls lesen alle Datenpakete, die sich im LAN bewegen. Pakete können mithilfe der Kopfzeileninformation gelesen und bearbeitet werden. Die Pakete werden auf der Grundlage von programmierbaren Regeln gefiltert, die vom Administrator der Firewall aufgestellt wurden. Der Linux-Kernel hat eine integrierte Paketfilterfunktion über das Netfilter-Kernel-Subsystem. |
|
| ||||||
| Proxy | Proxy-Firewalls filtern alle Anfragen eines bestimmten Protokolls oder Typs von den LAN-Clients zu einer Proxy-Maschine, von wo aus die Anfragen im Auftrag des lokalen Clients an das Internet gestellt werden. Eine Proxy-Maschine fungiert als ein Puffer zwischen bösartigen Benutzern von außen und den internen Client- Maschinen des Netzwerkes. |
|
|
2.5.1. Netfilter und IPTables
iptables-Hilfsprogramm gesteuert.
2.5.1.1. Überblick über IPTables
iptables-Verwaltungstools implementiert, ein Befehlszeilentool, das eine ähnliche Syntax wie sein Vorgänger ipchains verwendet. ipchains wurde ab dem Linux-Kernel 2.4 durch Netfilter/iptables abgelöst.
iptables verwendet das Netfilter-Subsystem zur Erweiterung, Untersuchung und Verarbeitung der Netzwerkverbindungen. iptables bietet verbesserte Protokollierung, Pre- und Post-Routing Aktionen, Network Address Translation und Port-Weiterleitung, alles in einer einzigen Befehlszeilenschnittstelle.
iptables. Für weitere Informationen werfen Sie bitte einen Blick auf Abschnitt 2.6, »IPTables«.
2.5.2. Grundlegende Firewall-Konfiguration
2.5.2.1. Firewall-Konfigurationstool
[root@myServer ~] # system-config-firewall
Abbildung 2.5. Firewall-Konfigurationstool
Anmerkung
iptables-Regeln.
2.5.2.2. Aktivieren und Deaktivieren der Firewall
- Deaktiviert — Mit deaktivierter Firewall werden keinerlei Sicherheitsprüfungen durchgeführt und der Zugang zu Ihrem System steht weit offen. Wählen Sie diese Einstellung nur, wenn sich Ihr System in einem vertrauenswürdigen Netzwerk befindet (nicht dem Internet) oder falls Sie mithilfe des iptables-Befehlszeilentools eine angepasste Firewall konfigurieren möchten.
Warnung
Firewall-Konfigurationen und benutzerdefinierte Firewall-Regeln werden in der/etc/sysconfig/iptables-Datei gespeichert. Falls Sie Deaktivieren wählen und auf klicken, gehen diese Konfigurationen und Firewall-Regeln verloren. - Aktiviert — Diese Option konfiguriert das System derart, dass eingehende Verbindungen, die keine Antworten auf ausgehende Anfragen sind, wie z. B. DNS-Antworten oder DHCP-Anfragen, abgewiesen werden. Falls der Zugriff auf Dienste nötig ist, die auf diesem Rechner laufen, können Sie bestimmte Dienste durch die Firewall erlauben.Falls Sie Ihr System mit dem Internet verbinden, jedoch nicht beabsichtigen, einen Server auszuführen, ist dies die sicherste Wahl.
2.5.2.3. Vertrauenswürdige Dienste
- WWW (HTTP)
- Das HTTP-Protokoll wird von Apache (und anderen Webservern) zur Bereitstellung von Webseiten genutzt. Falls Sie beabsichtigen, Ihren Webserver öffentlich verfügbar zu machen, markieren Sie dieses Auswahlkästchen. Diese Option ist dagegen nicht nötig, wenn Sie die Seiten nur lokal anzeigen möchten oder während Sie die Websites entwickeln. Dieser Dienst erfordert die Installation des
httpd-Pakets.Wenn Sie nur WWW (HTTP) aktivieren, wird kein Port für HTTPS geöffnet, die SSL-Version von HTTP. Falls dieser Dienst erforderlich ist, markieren Sie ebenfalls das Secure WWW (HTTPS) Auswahlkästchen. - FTP
- Das FTP-Protokoll wird zur Übertragung von Dateien zwischen Rechnern auf einem Netzwerk verwendet. Falls Sie beabsichtigen, Ihren FTP-Server öffentlich verfügbar zu machen, markieren Sie dieses Auswahlkästchen. Dieser Dienst erfordert die Installation des
vsftpd-Pakets. - SSH
- Secure Shell (SSH) ist eine Tool-Suite zum Anmelden auf einem entfernten Rechner und zum Ausführen von Befehlen darauf. Um Fernzugriff auf den Rechner über SSH zu erlauben, markieren Sie dieses Auswahlkästchen. Dieser Dienst erfordert die Installation des
openssh-server-Pakets. - Telnet
- Telnet ist ein Protokoll zum Anmelden auf entfernen Rechnern. Die Kommunikation über Telnet ist nicht verschlüsselt und bietet keinerlei Schutz gegen das Abfangen der Daten. Es wird daher nicht empfohlen, eingehenden Telnet-Zugriff zu erlauben. Um den Fernzugriff auf den Rechner über Telnet zu erlauben, markieren Sie dieses Auswahlkästchen. Dieser Dienst erfordert die Installation des
telnet-server-Pakets. - Mail (SMTP)
- SMTP ist ein Protokoll, dass es entfernten Hosts erlaubt, zum Zustellen von E-Mail direkt mit Ihrem Rechner zu verbinden. Sie brauchen diesen Dienst nicht zu aktivieren, wenn Sie Ihre E-Mails mittels POP3 oder IMAP von dem Server Ihres Internet Service Providers abrufen, oder falls Sie ein Tool wie z. B.
fetchmailverwenden. Um die Zustellung von E-Mail an Ihren Rechner zu erlauben, markieren Sie dieses Auswahlkästchen. Beachten Sie, dass ein fehlerhaft konfigurierter SMTP-Server es entfernten Rechnern ermöglichen kann, Ihren Server zum Versenden von Spam zu missbrauchen. - NFS4
- Das Network File System (NFS) ist ein File-Sharing-Protokoll, das häufig auf *NIX-Systemen eingesetzt wird. Version 4 dieses Protokolls ist sicherer als seine Vorläufer. Falls Sie Dateien oder Verzeichnisse auf Ihrem System für andere Benutzer auf dem Netzwerk freigeben möchten, markieren Sie dieses Auswahlkästchen.
- Samba
- Samba ist eine Implementierung von Microsofts proprietärem SMB-Netzwerkprotokoll. Falls Sie Dateien, Verzeichnisse oder lokal angeschlossene Drucker für Microsoft Windows Rechner auf dem Netzwerk freigeben möchten, markieren Sie dieses Auswahlkästchen.
2.5.2.4. Andere Ports
iptables als vertrauenswürdig festzulegen. Um beispielsweise IRC und Internet Printing Protocol (IPP) das Passieren der Firewall zu erlauben, fügen Sie Folgendes zum Andere Ports Abschnitt hinzu:
194:tcp,631:tcp
2.5.2.5. Speichern der Einstellungen
iptables-Befehle übersetzt und in die /etc/sysconfig/iptables-Datei geschrieben. Zudem wird der iptables-Dienst gestartet, so dass die Firewall sofort nach Abspeichern der gewählten Optionen aktiviert ist. Falls Firewall deaktivieren ausgewählt wurde, wird die /etc/sysconfig/iptables-Datei gelöscht und der iptables-Dienst umgehend gestoppt.
/etc/sysconfig/system-config-firewall geschrieben, so dass die Einstellungen beim nächsten Start der Applikation wiederhergestellt werden können. Bearbeiten Sie diese Datei nicht manuell.
iptables-Dienst nicht zum automatischen Start beim Systemstart konfiguriert. Siehe Abschnitt 2.5.2.6, »Aktivieren des IPTables-Dienstes« für weitere Informationen.
2.5.2.6. Aktivieren des IPTables-Dienstes
iptables-Dienst läuft. Um den Dienst manuell zu starten, führen Sie den folgenden Befehl aus:
[root@myServer ~] # service iptables restart
iptables zum Zeitpunkt des Systemstarts ebenfalls gestartet wird, verwenden Sie den folgenden Befehl:
[root@myServer ~] # chkconfig --level 345 iptables on
2.5.3. Verwenden von IPTables
iptables verwenden zu können, müssen Sie zunächst den iptables-Dienst starten. Führen Sie den folgenden Befehl aus, um den iptables-Dienst zu starten:
[root@myServer ~] # service iptables start
Anmerkung
ip6tables-Dienst kann ausgeschaltet werden, falls Sie ausschließlich den iptables-Dienst nutzen möchten. Falls Sie den ip6tables-Dienst deaktivieren, vergessen Sie nicht, auch das IPv6-Netzwerk zu deaktivieren. Lassen Sie nie ein Netzwerkgerät aktiv, das keine entsprechende Firewall besitzt.
iptables dazu zu zwingen, beim Hochfahren des Systems ebenfalls zu starten, führen Sie den folgenden Befehl aus:
[root@myServer ~] # chkconfig --level 345 iptables on
iptables dazu gezwungen zu starten, sobald das System in Runlevel 3, 4 oder 5 hochgefahren wird.
2.5.3.1. Befehlssyntax von IPTables
iptables-Befehls veranschaulicht die grundlegende Befehlssyntax:
[root@myServer ~ ] # iptables -A <chain> -j <target>
-A-Option gibt an, dass die Regel ans Ende der <chain> (Kette) angehängt werden soll. Jede Kette besteht aus einer oder mehrerer rules (Regeln), und wird daher auch als Regelset bezeichnet.
-j <target> legt das Ziel der Regel fest, also das Verhalten, wenn ein Paket mit einer Regel übereinstimmt. Beispiele für integrierte Ziele sind ACCEPT, DROP und REJECT.
iptables-Handbuchseite für weitere Informationen über die verfügbaren Ketten, Optionen und Ziele.
2.5.3.2. Grundlegende Firewall-Richtlinien
iptables-Kette besteht aus einer Standardrichtlinie und null oder mehr Regeln, die zusammen mit der Standardrichtlinie das gesamte Regelset der Firewall definieren.
[root@myServer ~ ] # iptables -P INPUT DROP [root@myServer ~ ] # iptables -P OUTPUT DROP
[root@myServer ~ ] # iptables -P FORWARD DROP
2.5.3.3. Speichern und Wiederherstellen von IPTables-Regeln
iptables sind nicht dauerhaft. Wenn das System oder der iptables-Dienst neu gestartet wird, werden die Regeln automatisch gelöscht und zurückgesetzt. Um die Regeln zu speichern und sie beim Start des iptables-Dienstes zu laden, führen Sie den folgenden Befehl aus:
[root@myServer ~ ] # service iptables save
/etc/sysconfig/iptables-Datei gespeichert und werden angewendet, sobald der Dienst oder der Rechner neu gestartet wird.
2.5.4. Häufige IPTables-Filter
[root@myServer ~ ] # iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
[root@myServer ~ ] # iptables -A INPUT -p tcp -m tcp --dport 443 -j ACCEPT
Wichtig
iptables-Regelsets ist die Reihenfolge von entscheidender Bedeutung.
-I-Option. Zum Beispiel:
[root@myServer ~ ] # iptables -I INPUT 1 -i lo -p all -j ACCEPT
iptables konfigurieren, um Verbindungen von entfernten SSH-Clients zu akzeptieren. Die folgende Regel erlaubt beispielsweise SSH-Zugriff von Remote aus:
[root@myServer ~ ] # iptables -A INPUT -p tcp --dport 22 -j ACCEPT [root@myServer ~ ] # iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT
iptables Filterungsregeln nutzen.
2.5.5. FORWARD- und NAT-Regeln
iptables Richtlinien zur Um- und Weiterleitung von Paketen, die den untypischen Gebrauch von Netzwerkressourcen verhindern können.
FORWARD-Kette kann ein Administrator steuern, wohin innerhalb eines LANs Pakete weitergeleitet werden können. Um beispielsweise die Weiterleitung für das gesamte LAN zu gestatten (vorausgesetzt, der Firewall bzw. dem Gateway ist eine interne IP-Adresse auf eth1 zugewiesen), verwenden Sie die folgenden Regeln:
[root@myServer ~ ] # iptables -A FORWARD -i eth1 -j ACCEPT [root@myServer ~ ] # iptables -A FORWARD -o eth1 -j ACCEPT
eth1-Gerät.
Anmerkung
[root@myServer ~ ] # sysctl -w net.ipv4.ip_forward=1
/etc/sysctl.conf-Datei wie folgt:
net.ipv4.ip_forward = 0
net.ipv4.ip_forward = 1
sysctl.conf-Datei zu aktivieren:
[root@myServer ~ ] # sysctl -p /etc/sysctl.conf
2.5.5.1. Postrouting und IP Masquerading
[root@myServer ~ ] # iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
-t nat) und spezifiziert die integrierte POSTROUTING-Kette für NAT (-A POSTROUTING) auf dem externen Netzwerkgerät der Firewall (-o eth0).
-j MASQUERADE wird spezifiziert, um die private IP-Adresse eines Knotens mit der externen IP-Adresse der Firewall bzw. des Gateways zu maskieren.
2.5.5.2. Prerouting
-j DNAT der PREROUTING-Kette in NAT verwenden, um eine Ziel-IP-Adresse und einen Port anzugeben, an die eingehende Pakete, die eine Verbindung mit Ihrem internen Dienst anfragen, weitergeleitet werden können.
[root@myServer ~ ] # iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to 172.31.0.23:80
Anmerkung
[root@myServer ~ ] # iptables -A FORWARD -i eth0 -p tcp --dport 80 -d 172.31.0.23 -j ACCEPT
2.5.5.3. DMZs und IPTables
iptables-Regeln erstellen, um Daten an bestimmte Rechner weiterzuleiten, wie z. B. an dedizierte HTTP- oder FTP-Server, in einer demilitarisierten Zone (DMZ). Eine DMZ ist ein spezielles, lokales Subnetzwerk, das Dienste auf einem öffentlichen Träger wie z. B. dem Internet bereitstellt.
PREROUTING-Tabelle, um Pakete an das entsprechende Ziel weiterzuleiten:
[root@myServer ~ ] # iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to-destination 10.0.4.2:80
2.5.6. Schädliche Software und erschnüffelte IP-Adressen
[root@myServer ~ ] # iptables -A OUTPUT -o eth0 -p tcp --dport 31337 --sport 31337 -j DROP [root@myServer ~ ] # iptables -A FORWARD -o eth0 -p tcp --dport 31337 --sport 31337 -j DROP
[root@myServer ~ ] # iptables -A FORWARD -s 192.168.1.0/24 -i eth0 -j DROP
Anmerkung
DROP- und REJECT-Zielen.
REJECT-Ziel verweigert den Zugang und gibt eine connection refused Fehlermeldung an Benutzer heraus, die mit dem Dienst zu verbinden versuchen. Das DROP-Ziel verwirft das Paket dagegen ohne jegliche Fehlermeldung.
REJECT-Ziel zu verwenden, um Benutzer nicht unnötig zu verwirren und um wiederholte Verbindungsversuche zu vermeiden.
2.5.7. IPTables und Connection Tracking
iptables verwendet eine Methode, die Connection Tracking oder auch Dynamische Paketfilterung genannt wird, um Informationen über eingehende Verbindungen zu speichern. Sie können den Zugriff auf Grundlage der folgenden Verbindungszustände erlauben oder verweigern:
NEW— Ein Paket fordert eine neue Verbindung an, z. B. eine HTTP-Anfrage.ESTABLISHED— Ein Paket ist Teil einer bestehenden Verbindung.RELATED— Ein Paket fordert eine neue Verbindung an, ist jedoch Teil einer bestehenden Verbindung. So verwendet FTP beispielsweise Port 21, um eine Verbindung herzustellen, die Daten werden jedoch auf einem anderen Port übertragen (üblicherweise Port 20).INVALID— Ein Paket gehört zu keiner Verbindung in der Connection-Tracking-Tabelle.
iptables-Funktion zur Zustandsüberprüfung mit jedem Netzwerkprotokoll verwenden, selbst wenn das Protokoll selbst zustandslos ist (wie z. B. UDP). Das folgende Beispiel zeigt eine Regel, die mithilfe der dynamischen Paketfilterung nur solche Pakete weiterleitet, die mit einer bereits bestehenden Verbindung zusammenhängen:
[root@myServer ~ ] # iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
2.5.8. IPv6
ip6tables-Befehls. In Red Hat Enterprise Linux 6 sind sowohl IPv4- als auch IPv6-Dienste standardmäßig aktiviert.
ip6tables-Befehlssyntax ist identisch mit iptables, mit Ausnahme der Tatsache, dass es 128-Bit-Adressen unterstützt. Führen Sie beispielsweise den folgenden Befehl aus, um SSH-Verbindungen auf einem IPv6-kompatiblen Netzwerkserver zu aktivieren:
[root@myServer ~ ] # ip6tables -A INPUT -i eth0 -p tcp -s 3ffe:ffff:100::1/128 --dport 22 -j ACCEPT
2.5.9. Zusätzliche Informationsquellen
2.5.9.1. Installierte Firewall-Dokumentation
- Abschnitt 2.6, »IPTables« beinhaltet ausführliche Informationen über den
iptables-Befehl, einschließlich der Definitionen für zahlreiche Befehlsoptionen. - Die
iptables-Handbuchseite enthält eine kurze Zusammenfassung der verschiedenen Optionen.
2.5.9.2. Hilfreiche Firewall-Websites
- http://www.netfilter.org/ — Die offizielle Homepage des Netfilter- und
iptables-Projekts. - http://www.tldp.org/ — Das Linux-Dokumentations-Projekt enthält mehrere hilfreiche Handbücher in Zusammenhang mit der Erstellung und Administration von Firewalls.
- http://www.iana.org/assignments/port-numbers — Die offizielle Liste registrierter und üblicher Dienst-Ports, zugeteilt von der Internet Assigned Numbers Authority.
2.5.9.3. Verwandte Dokumentation
- Red Hat Linux Firewalls, von Bill McCarty; Red Hat Press — ein umfassendes Nachschlagewerk zum Erstellen von Netzwerk- und Server-Firewalls mittels Open-Source-Paketfilterungs-Technologie wie z. B. Netfilter und
iptables. Es beinhaltet Themen wie beispielsweise das Analysieren von Firewall-Protokollen, das Entwickeln von Firewall-Regeln und das Anpassen Ihrer Firewall mit grafischen Tools wie z. B.lokkit. - Linux Firewalls, von Robert Ziegler; New Riders Press — enthält eine Menge an Informationen über das Erstellen von Firewalls mit 2.2 Kernel und
ipchainssowie mit Netfilter undiptables. Es werden auch zusätzliche Sicherheitsthemen behandelt, wie z. B. der Fernzugriff und Intrusion-Detection-Systeme.
2.6. IPTables
ipchains zur Paketfilterung und wendeten Regellisten auf Pakete in jeder Phase des Filterungsprozesses an. Mit der Kernel-Version 2.4 wurde iptables eingeführt (auch Netfilter genannt), die den ipchains zwar ähnlich sind, jedoch den Wirkungsbereich und die Kontrollmöglichkeiten bei der Filterung von Netzwerkpaketen stark erweitern.
iptables-Befehle. Es wird außerdem gezeigt, wie Filterungsregeln über Neustarts des Systems hinweg bewahrt werden können.
iptables-Regeln angelegen und darauf basierend eine Firewall einrichten können.
Wichtig
iptables, allerdings kann iptables nicht benutzt werden, wenn ipchains bereits läuft. Falls zum Zeitpunkt des Systemstarts ipchains bereits vorhanden ist, gibt der Kernel eine Fehlermeldung aus und kann iptables nicht starten.
ipchains wird durch diese Fehlermeldungen jedoch nicht beeinträchtigt.
2.6.1. Paketfilterung
filter— Die Standardtabelle zur Verarbeitung von Netzwerkpaketen.nat— Diese Tabelle wird zur Änderung von Paketen verwendet, die eine neue Verbindung herstellen, sowie für Network Address Translation (NAT).mangle— Diese Tabelle wird für spezielle Arten der Paketänderung verwendet.
netfilter auf dem Paket durchgeführt werden.
filter-Tabelle sind:
- INPUT — Gilt für Netzwerkpakete, die für den Host bestimmt sind.
- OUTPUT — Gilt für Netzwerkpakete, die lokal generiert wurden.
- FORWARD — Gilt für Netzwerkpakete, die über den Host geroutet werden.
nat-Tabelle sind:
- PREROUTING — Ändert Netzwerkpakete beim Empfang.
- OUTPUT — Ändert lokal generierte Netzwerkpakete, bevor diese gesendet werden.
- POSTROUTING — Ändert Netzwerkpakete, bevor diese gesendet werden.
mangle-Tabelle sind:
- INPUT — Ändert Netzwerkpakete, die für den Host bestimmt sind.
- OUTPUT — Ändert lokal generierte Netzwerkpakete, bevor diese gesendet werden.
- FORWARD — Ändert Netzwerkpakete, die über den Host geroutet werden.
- PREROUTING — Ändert eingehende Netzwerkpakete, bevor diese geroutet werden.
- POSTROUTING — Ändert Netzwerkpakete, bevor diese gesendet werden.

Anmerkung
/etc/sysconfig/iptables oder /etc/sysconfig/ip6tables gespeichert.
iptables-Dienst startet beim Booten eines Linux-Systems vor jeglichen DNS-Diensten. Aus diesem Grund können Firewall-Regeln nur auf numerische IP-Adressen (zum Beispiel 192.168.0.1) verweisen. Domainnamen (wie beispielsweise host.example.com) in solchen Regeln verursachen dagegen Fehler.
ACCEPT-Ziel für ein übereinstimmendes Paket spezifiziert, überspringt das Paket die restlichen Regeln und darf somit seinen Weg zum Bestimmungsort fortsetzen. Wenn aber eine Regel ein DROP-Ziel spezifiziert, wird dem Paket der Zugriff auf das System verwehrt, ohne eine Meldung an den Host-Rechner, von dem das Paket stammt, zurückzusenden. Wenn eine Regel ein QUEUE-Ziel spezifiziert, wird das Paket an den Userspace weitergeleitet. Wenn eine Regel ein optionales REJECT-Ziel spezifiziert, wird das Paket verworfen und es wird ein Fehlerpaket an den Ursprungs-Host zurückgesendet.
ACCEPT, DROP, REJECT oder QUEUE. Wenn das Paket keiner der Regeln in der Kette entspricht, wird auf dieses Paket die Standardrichtlinie angewendet.
iptables-Befehl konfiguriert diese Tabellen und erstellt neue, falls nötig.
2.6.2. Befehlsoptionen für IPTables
iptables-Befehls erstellt. Die folgenden Aspekte eines Pakets werden häufig als Kriterien verwendet:
- Pakettyp — Legt fest, welche Pakete der Befehl filtert, basierend auf dem Typ des Pakets.
- Paketquelle/-bestimmungort — Legt fest, welche Pakete der Befehl filtert, basierend auf der Quelle oder dem Bestimmungort des Pakets.
- Ziel — Legt fest, welche Aktion auf den Paketen angewendet wird, die den oben genannten Kriterien entsprechen.
iptables-Regeln verwendeten Optionen müssen logisch gruppiert sein, basierend auf Zweck und Bedingungen der gesamten Regel, damit die Regel gültig ist. Der Rest dieses Abschnitts erläutert häufig verwendete Optionen für den iptables-Befehl.
2.6.2.1. Syntax der IPTables-Befehlsoptionen
iptables-Befehle folgen dem folgenden Format:
iptables [-t <table-name>] <command> <chain-name> \ <parameter-1> <option-1> \ <parameter-n> <option-n>filter-Tabelle verwendet.
iptables-Befehls kann sich sehr unterscheiden, abhängig von dessen Zweck.
iptables -D <chain-name> <line-number>
iptables-Befehls muss bedacht werden, dass einige Parameter und Optionen weitere Parameter und Optionen benötigen, um eine gültige Regel zu bilden. Dies kann einen Dominoeffekt hervorrufen, mit weiteren Parametern, die wiederum weitere Parameter benötigen. Solange nicht alle Parameter und Optionen, die eine Reihe weiterer Optionen benötigen, erfüllt sind, ist die Regel nicht gültig.
iptables -h eingeben, erhalten Sie eine vollständige Liste der iptables-Befehlsstrukturen.
2.6.2.2. Befehlsoptionen
iptables angewiesen, einen bestimmten Vorgang auszuführen. Nur eine einzige Befehlsoption pro iptables-Befehl ist erlaubt. Mit Ausnahme des Hilfebefehls sind alle Befehle in Großbuchstaben geschrieben.
iptables-Befehle sind:
-A— Hängt die Regel an das Ende der angegebenen Kette an. Im Gegensatz zur weiter unten beschriebenen Option-Iwird hierbei kein ganzzahliger Parameter verwendet. Die Regel wird immer an das Ende der angegebenen Kette gehängt.-D <integer> | <rule>— Entfernt eine Regel in einer bestimmten Kette anhand ihrer Nummer (z. B.5für die fünfte Regel einer Kette) oder durch Angabe einer Regelspezifikation. Die Regelspezifikation muss exakt mit einer bestehenden Regel übereinstimmen.-E— Benennt eine benutzerdefinierte Kette um. Eine benutzerdefinierte Kette ist jede Kette, die nicht eine standardmäßige, voreingestellte Kette ist. (Werfen Sie einen Blick auf die Option-Nweiter unten für Informationen zur Erstellung von benutzerdefinierten Ketten). Dies ist eine reine Schönheitskorrektur und beeinflusst nicht die Struktur der Tabelle.Anmerkung
Falls Sie versuchen, eine der Standardketten umzubenennen, gibt das System die FehlermeldungMatch not foundaus. Sie können die Standardketten nicht umbenennen.-F— Löscht den Inhalt der gewählten Kette, woraufhin effektiv jede Regel in der Kette entfernt wird. Wenn keine Kette angegeben wird, löscht dieser Befehl jede Regel in jeder Kette.-h— Liefert eine Liste mit Befehlsstrukturen sowie eine kurze Zusammenfassung der Befehlsparameter und -optionen.-I [<integer>]— Fügt eine Regel an einem bestimmten Punkt, der anhand eines ganzzahligen, benutzerdefinierten Werts spezifiziert wird, in eine Kette ein. Wird kein Wert angegeben, wird die Regel am Anfang der Kette eingefügt.Wichtig
Wie bereits oben erwähnt, bestimmt die Reihenfolge der Regeln in einer Kette, welche Regeln auf welche Pakete angewendet werden. Dies sollten Sie beim Hinzufügen von Regeln mit der Option-Aoder-lunbedingt bedenken.Dies ist besonders wichtig, wenn Regeln unter Verwendung der Option-lmit einem ganzzahligen Parameter hinzugefügt werden. Wenn Sie beim Hinzufügen einer Regel zu einer Kette eine bereits existierende Nummer angeben, fügtiptablesdie neue Regel vor (also über) der existierenden Regel ein.-L— Listet alle Regeln in der angegebenen Kette auf. Um alle Regeln in allen Ketten in der Standardtabellefilteraufzulisten, spezifizieren Sie keine Kette oder Tabelle. Ansonsten sollte folgende Syntax verwendet werden, um die Regeln in einer bestimmten Kette in einer bestimmten Tabelle aufzulisten:iptables -L <chain-name> -t <table-name>Zusätzliche Optionen für die-L-Befehlsoption, die z. B. Regelnummern anzeigen oder ausführlichere Regelbeschreibungen ermöglichen, finden Sie in Abschnitt 2.6.2.6, »Auflistungsoptionen«.-N— Erstellt eine neue Kette mit benutzerdefiniertem Namen. Der Name der Kette muss eindeutig sein, andernfalls wird eine Fehlermeldung angezeigt.-P— Legt die Standardrichtlinie für die angegebene Kette fest. Dadurch werden Pakete, die eine Kette vollständig durchlaufen, ohne mit einer Regel übereinzustimmen, an das angegebene Ziel gesendet, wie z. B. ACCEPT oder DROP.-R— Ersetzt eine Regel in einer angegebenen Kette. Sie müssen dazu nach dem Namen der Kette eine Regelnummer angeben, um die Regel zu ersetzen. Die erste Regel einer Kette ist die Regel Nummer 1.-X— Löscht eine benutzerdefinierte Kette. Eine integrierte Kette kann dagegen nicht gelöscht werden.-Z— Stellt Byte- und Paketzähler in allen Ketten für eine Tabelle auf Null.
2.6.2.3. IPTables-Parameteroptionen
iptables-Befehle, zum Beispiel die Befehle zum Hinzufügen, Anhängen, Entfernen, Einfügen oder Ersetzen von Regeln innerhalb einer bestimmten Kette, erfordern verschiedene Parameter für die Erstellung einer Paketfilterungsregel.
-c— Setzt die Zähler für eine angegebene Regel zurück. Dieser Parameter akzeptiert diePKTS- undBYTES-Optionen um anzugeben, welche Zähler zurückzusetzen sind.-d— Legt den Bestimmungsort des Pakets als Hostnamen, IP-Adresse oder Netzwerk fest, der mit der Regel übereinstimmt. Zur Übereinstimmung mit einem Netzwerk werden die folgenden Formate für IP-Adressen/Netmasks unterstützt:N.N.N.N/M.M.M.M— Wobei N.N.N.N der IP-Adressbereich und M.M.M.M die Netmask ist.N.N.N.N/M— Wobei N.N.N.N der IP-Adressbereich und M die Bitmask ist.
-f— Wendet diese Regel nur auf fragmentierte Pakete an.Wird ein Ausrufezeichen (!) als Option vor diesem Parameter verwendet, werden nur unfragmentierte Pakete verglichen.Anmerkung
Die Unterscheidung zwischen fragmentierten und unfragmentierten Paketen ist wünschenswert, auch wenn fragmentierte Pakete standardmäßig Teil des IP-Protokolls sind.Fragmentierung wurde ursprünglich dazu konzipiert, IP-Paketen das Passieren von Netzwerken mit unterschiedlichen Frame-Größen zu gestatten, wird heutzutage jedoch meist dazu verwendet, mithilfe von fehlerhaften Paketen DoS-Angriffe zu unternehmen. An dieser Stelle sei auch erwähnt, dass IPv6 Fragmentierung komplett verbietet.-i— Legt die Eingangsnetzwerkschnittstelle fest, z. B.eth0oderppp0. Mitiptablesdarf dieser zusätzliche Parameter nur mit INPUT- und FORWARD-Ketten in Verbindung mit derfilter-Tabelle und der PREROUTING-Kette mit dennat- undmangle-Tabellen verwendet werden.Dieser Parameter unterstützt darüberhinaus folgende spezielle Optionen:- Ausrufezeichen (
!) — Kehrt die Direktive um, was bedeutet, dass jegliche angegebene Schnittstellen von dieser Regel ausgenommen sind. - Pluszeichen (
+) — Ein Platzhalterzeichen, mithilfe dessen alle Schnittstellen zutreffend sind, die mit der angegebenen Zeichenkette übereinstimmen. Der Parameter-i eth+würde diese Regel z. B. für alle Ethnernet-Schnittstellen Ihres Systems anwenden, aber alle anderen Schnittstellen, wie z. B.ppp0auslassen.
Wenn der-i-Parameter ohne Angabe einer Schnittstelle verwendet wird, ist jede Schnittstelle von dieser Regel betroffen.-j— Springt zum angegebenen Ziel, wenn ein Paket einer bestimmten Regel entspricht.Die Standardziele sindACCEPT,DROP,QUEUEundRETURN.Erweiterte Optionen sind zudem über Module verfügbar, die standardmäßig mit mit dem Red Hat Enterprise Linuxiptables-RPM-Paket geladen werden. Gültige Ziele in diesen Modulen sind unter anderemLOG,MARKundREJECT. Weitere Informationen zu diesen und anderen Zielen finden Sie auf deriptables-Handbuchseite.Diese Option kann dazu verwendet werden, ein Paket, das einer bestimmten Regel entspricht, an eine benutzerdefinierte Kette außerhalb der aktuellen Kette weiterzuleiten, so dass andere Regeln auf dieses Paket angewendet werden können.Falls kein Ziel festgelegt ist, durchläuft das Paket diese Regel, ohne dass etwas unternommen wird. Der Zähler für diese Regel wird jedoch um eins erhöht.-o— Legt die Ausgangsnetzwerkschnittstelle für eine bestimmte Regel fest, die nur mit OUTPUT- und FORWARD-Ketten in derfilter-Tabelle und mit der POSTROUTING-Kette in dennat- undmangle-Tabellen verwendet werden kann. Die akzeptierten Optionen dieses Parameters sind dieselben wie die des Parameters der Eingangsnetzwerkschnittstelle (-i).-p <protocol>— Legt das IP-Protokoll für die Regel fest. Dies kann entwedericmp,tcp,udp,all, oder aber ein numerischer Wert sein, der für eines dieser Protokolle oder für ein anderes Protokoll steht. Auch Protokolle, die in/etc/protocolsaufgelistet sind, können verwendet werden.Die Option "all" bewirkt, dass die Regel auf alle unterstützte Protokolle angewendet wird. Falls kein Protokoll in der Regel angegeben wird, ist der Standardwert "all".-s— Legt die Quelle eines bestimmten Pakets fest, und zwar unter Verwendung derselben Syntax, die auch der Parameter für den Bestimmungsort (-d) verwendet.
2.6.2.4. IPTables Übereinstimmungsoptionen
iptables-Befehl spezifiziert werden. So aktiviert -p <protocol-name> z. B. Optionen für das angegebene Protokoll. Beachten Sie, dass Sie auch die Protokoll-ID anstelle des Protokollnamens verwenden können. Werfen Sie einen Blick auf die folgenden Beispiele, die jeweils denselben Effekt haben:
iptables -A INPUT -p icmp --icmp-type any -j ACCEPT iptables -A INPUT -p 5813 --icmp-type any -j ACCEPT /etc/services geliefert. Im Interesse der Lesbarkeit wird die Verwendung der Dienstnamen anstelle der Portnummern empfohlen.
Warnung
/etc/services-Datei, um ein unerlaubtes Bearbeiten zu verhindern. Ist diese Datei editierbar, können Angreifer sie dazu missbrauchen, Ports auf Ihrem Rechner zu aktivieren, die Sie geschlossen hatten. Um diese Datei abzusichern, führen Sie als Root folgende Befehle aus:
[root@myServer ~]# chown root.root /etc/services [root@myServer ~]# chmod 0644 /etc/services [root@myServer ~]# chattr +i /etc/services
2.6.2.4.1. TCP-Protokoll
-p tcp):
--dport— Definiert den Ziel-Port für das Paket.Verwenden Sie den Namen eines Netzwerkdienstes (wie z. B. www oder smtp), eine Portnummer oder einen Bereich von Portnummern, um diese Option zu konfigurieren.Um einen Bereich von Portnummern anzugeben, trennen Sie die zwei Nummern durch einen Doppelpunkt (:), z. B.:-p tcp --dport 3000:3200. Der größtmögliche Bereich ist0:65535.Sie können auch ein Ausrufezeichen (!) vor der--dport-Option verwenden, um mit allen Paketen, die nicht diesen Netzwerkdienst oder diesen Port verwenden, übereinzustimmen.Um die Namen und Aliasse von Netzwerkdiensten und den von ihnen verwendeten Portnummern zu durchsuchen, werfen Sie einen Blick auf die/etc/services-Datei.Die Übereinstimmungsoption--destination-portist dasselbe wie--dport.--sport— Setzt den Ursprungsport des Pakets unter Verwendung derselben Optionen wie--dport. Die Übereinstimmungsoption--source-portist dasselbe wie--sport.--syn— Gilt für alle TCP-Pakete, die eine Kommunikation initialisieren sollen, allgemein SYN-Pakete genannt. Alle Pakete, die Nutzdaten enthalten, werden nicht bearbeitet.Wird ein Ausrufezeichen (!) vor der--syn-Option verwendet, wird die Regel nur auf Pakete angewendet, bei denen es sich nicht um SYN-Pakete handelt.--tcp-flags <tested flag list> <set flag list>— Ermöglicht TCP-Paketen mit bestimmten Bits (Flags), mit einer Regel übereinzustimmen.Die Übereinstimmungsoption--tcp-flagsakzeptiert zwei Parameter. Beim ersten Parameter handelt es sich um eine Maske, eine kommagetrennte Liste mit Flags, die im Paket zu untersuchen sind. Der zweite Parameter ist eine kommagetrennte Liste mit Flags, die gesetzt sein müssen, um eine Übereinstimmung mit der Regel zu erhalten.Mögliche Flags sind:ACKFINPSHRSTSYNURGALLNONE
Eineiptables-Regel, die folgende Spezifikation enthält, trifft beispielsweise nur auf TCP-Pakete zu, in denen das SYN-Flag aktiviert und die ACK- und FIN-Flags deaktiviert sind:--tcp-flags ACK,FIN,SYN SYNVerwenden Sie das Ausrufezeichen (!) hinter--tcp-flags, um den Effekt der Übereinstimmungsoption umzukehren.--tcp-option— Versucht eine Übereinstimmung anhand von TCP-spezifischen Optionen, die innerhalb eines bestimmten Pakets eingestellt werden können. Diese Übereinstimmungsoption kann ebenfalls mit dem Ausrufezeichen (!) umgekehrt werden.
2.6.2.4.2. UDP-Protokoll
-p udp):
--dport— Spezifiziert den Ziel-Port des UDP-Pakets unter Verwendung von Dienstnamen, Portnummer oder einem Portnummernbereich. Die Übereinstimmungsoption--destination-portist dasselbe wie--dport.--sport— Spezifiziert den Ursprungs-Port des UDP-Pakets unter Verwendung von Dienstnamen, Portnummer oder einem Portnummernbereich. Die Übereinstimmungsoption--source-portist dasselbe wie--sport.
--dport und --sport anzugeben, trennen Sie die zwei Nummern durch einen Doppelpunkt (:), z. B.: -p tcp --dport 3000:3200. Der größtmögliche Bereich ist 0:65535.
2.6.2.4.3. ICMP-Protokoll
-p icmp) verfügbar:
--icmp-type— Bestimmt den Namen oder die Nummer des ICMP-Typs, der mit der Regel übereinstimmen soll. Durch Eingabe des Befehlsiptables -p icmp -hwird eine Liste aller gültigen ICMP-Namen angezeigt.
2.6.2.4.4. Module mit zusätzlichen Übereinstimmungsoptionen
iptables geladen werden können.
-m <module-name> laden (wobei <module-name> der Name des Moduls ist).
limit-Modul — Schränkt die Anzahl der Pakete ein, auf die eine bestimmte Regel zutrifft.Wenn daslimit-Modul in Verbindung mit demLOG-Ziel verwendet wird, kann es verhindern, dass eine Flut übereinstimmender Pakete das Systemprotokoll mit sich wiederholenden Nachrichten überschwemmen bzw. Systemressourcen verbrauchen.Werfen Sie einen Blick auf Abschnitt 2.6.2.5, »Zieloptionen« für weitere Informationen zumLOG-Ziel.Daslimit-Modul akzeptiert die folgenden Optionen:--limit— Bestimmt die maximale Zahl der Übereinstimmungen innerhalb eines bestimmten Zeitraums im Format<value>/<period>. Mit--limit 5/hourdarf die Regel beispielsweise nur5Mal pro Stunde übereinstimmen.Die Zeiträume können in Sekunden, Minuten, Stunden oder Tagen angegeben werden.Wenn keine Angaben zur Anzahl oder Zeit gemacht werden, wird der Standardwert3/hourangenommen.--limit-burst— Setzt eine Grenze für die Anzahl von Paketen, die gleichzeitig mit einer Regel übereinstimmen können.Diese Option wird als ganzzahliger Wert angegeben und sollte zusammen mit der Option--limitverwendet werden.Wird kein Wert angegeben, so wird der Standardwert fünf (5) angenommen.
state-Modul — Ermöglicht Übereinstimmungen nach Zustand.Dasstate-Modul akzeptiert die folgenden Optionen:--state— Übereinstimmung mit einem Paket, das folgenden Verbindungszustand hat:ESTABLISHED— Das übereinstimmende Paket gehört zu anderen Paketen in einer bestehenden Verbindung. Sie müssen diesen Zustand akzeptieren, wenn Sie eine Verbindung zwischen Client und Server aufrecht erhalten möchten.INVALID— Das übereinstimmende Paket kann nicht mit einer bekannten Verbindung verknüpft werden.NEW— Das übereinstimmende Paket stellt entweder eine neue Verbindung her oder ist Teil einer Zwei-Wege-Verbindung, die vorher nicht gesehen wurde. Sie müssen diesen Zustand akzeptieren, wenn Sie neue Verbindungen zu einem Dienst erlauben möchten.RELATED— Ein übereinstimmendes Paket stellt eine neue Verbindung her, die auf irgendeine Weise mit einer bestehenden Verbindung zusammenhängt. Ein Beispiel hierfür ist FTP, das eine Verbindung zur Kontrolle des Datenverkehrs (Port 21) und eine separate Verbindung zur Übertragung von Daten (Port 20) verwendet.
Diese Verbindungszustände können auch in Kombination verwendet werden, wobei sie durch Kommas getrennt werden, wie z. B.-m state --state INVALID,NEW.
mac-Modul — Ermöglicht Übereinstimmung anhand Hardware-MAC-Adressen.Dasmac-Modul akzeptiert die folgende Option:--mac-source— Überprüft die MAC-Adresse der Netzwerkkarte, die das Paket gesendet hat. Um eine MAC-Adresse von einer Regel auszuschließen, fügen Sie nach der--mac-source-Übereinstimmungsoption ein Ausrufezeichen (!) hinzu.
iptables für weitere Übereinstimmungsoptionen, die über Module verfügbar sind.
2.6.2.5. Zieloptionen
<user-defined-chain>— Eine benutzerdefinierte Kette innerhalb der Tabelle. Namen von benutzerdefinierten Ketten müssen eindeutig sein. Dieses Ziel leitet das Paket an die angegebene Kette weiter.ACCEPT— Lässt das Paket zu dessen Bestimmungsort oder zu einer anderen Kette passieren.DROP— Das Paket wird ohne jegliche Antwort verworfen. Das System, das dieses Paket gesendet hat, wird nicht über das Verwerfen des Pakets benachrichtigt.QUEUE— Das Paket wird zur Warteschlange für die Bearbeitung durch eine Userspace-Applikation hinzugefügt.RETURN— Hält die Suche nach Übereinstimmungen des Pakets mit Regeln in der aktuellen Kette an. Wenn ein Paket mit einemRETURN-Ziel mit einer Regel in einer Kette übereinstimmt, die von einer anderen Kette aufgerufen wurde, wird das Paket an die erste Kette zurückgesendet, damit die Überprüfung wieder dort aufgenommen werden kann, wo sie unterbrochen wurde. Wenn dieRETURN-Regel in einer integrierten Kette verwendet wird und das Paket nicht zu seiner vorherigen Kette zurückkehren kann, entscheidet das Standardziel für die aktuelle Kette, welche Maßnahme getroffen wird.
LOG— Protokolliert alle Pakete, die dieser Regel entsprechen. Da die Pakete vom Kernel protokolliert werden, bestimmt die Datei/etc/syslog.conf, wohin diese Protokolleinträge geschrieben werden. Standardmäßig werden sie in der Datei/var/log/messagesabgelegt.Nach demLOG-Ziel können verschiedene, zusätzliche Optionen verwendet werden, um die Art der Protokollierung zu bestimmen:--log-level— Bestimmt die Prioritätsstufe eines Protokollereignisses. Auf den Handbuchseiten vonsyslog.conffinden Sie eine Liste der Prioritätsstufen.--log-ip-options— Protokolliert alle im Header eines IP-Pakets enthaltenen Optionen.--log-prefix— Fügt beim Schreiben einer Protokollzeile eine Zeichenkette von bis zu 29 Zeichen vor der Protokollzeile ein. Dies ist beim Schreiben von syslog-Filtern im Zusammenhang mit der Paketprotokollierung sehr nützlich.Anmerkung
Aufgrund eines Problems mit dieser Option sollten sie ein Leerzeichen hinter dem log-prefix-Wert einfügen.--log-tcp-options— Protokolliert alle im Header eines TCP-Pakets enthaltenen Optionen.--log-tcp-sequence— Schreibt die TCP-Sequenznummer für das Paket in die Protokolldatei.
REJECT— Sendet ein Fehlerpaket an das entfernte System zurück und verwirft das Paket.Mit demREJECT-Ziel kann die--reject-with <type>-Option verwendet werden (wobei <type> die Art der Zurückweisung angibt), um mehr Details zusammen mit dem Fehlerpaket zu senden. Die Meldungport-unreachableist die standardmäßige Fehlermeldung, wenn keine andere Option angewandt wurde. Eine vollständige Liste der verfügbaren<type>-Optionen finden Sie auf deriptables-Handbuchseite.
nat-Tabelle oder für Paketänderung mithilfe der mangle-Tabelle nützlich sind, finden Sie auf der iptables-Handbuchseite.
2.6.2.6. Auflistungsoptionen
iptables -L [<chain-name>], bietet eine sehr allgemeine Übersicht über die aktuellen Ketten der standardmäßigen Filtertabelle. Doch es gibt zusätzliche Optionen, die weitere Informationen liefern:
-v— Zeigt eine ausführliche Ausgabe an, wie z. B. die Anzahl der Pakete und Bytes, die jede Kette abgearbeitet hat, die Anzahl der Pakete und Bytes, die von jeder Regel auf Übereinstimmung überprüft wurden und welche Schnittstellen für eine bestimmte Regel zutreffen.-x— Erweitert die Zahlen auf ihre exakten Werte. In einem ausgelasteten System kann die Anzahl der Pakte und Bytes, die von einer bestimmten Kette oder Regel verarbeitet werden, aufKilobytes,MegabytesundGigabytesabgekürzt werden. Diese Option erzwingt die Anzeige der vollständigen Zahl.-n— Zeigt IP-Adressen und Portnummern in numerischem Format an, statt im standardmäßigen Hostnamen- und Netzwerkdienst-Format.--line-numbers— Listet Regeln in jeder Kette neben deren numerischer Position in der Kette auf. Diese Option ist nützlich, wenn Sie versuchen, eine bestimmte Regel aus einer Kette zu entfernen oder zu bestimmen, wo eine Regel in einer Kette eingefügt werden soll.-t <table-name>— Gibt einen Tabellennamen an. Falls nicht angegeben, wird standardmäßig die Filtertabelle verwendet.
2.6.3. Speichern von IPTables-Regeln
iptables-Befehl erstellt wurden, werden zunächst nur im Arbeitsspeicher bewahrt. Wird das System neu gestartet, bevor die iptables-Regeln gespeichert wurden, gehen diese Regeln verloren. Wenn Sie möchten, dass Netfilter-Regeln dauerhaft wirksam sind, müssen sie abgespeichert werden. Führen Sie dazu folgenden Befehl als Root aus:
/sbin/service iptables save iptables-init-Skript angewiesen, das /sbin/iptables-save-Programm auszuführen und die aktuelle iptables-Konfiguration in die /etc/sysconfig/iptables-Datei zu schreiben. Die bestehende /etc/sysconfig/iptables-Datei wird unter /etc/sysconfig/iptables.save gespeichert.
iptables-init-Skript die in /etc/sysconfig/iptables gespeicherten Regeln mittels des /sbin/iptables-restore-Befehls erneut an.
iptables-Regel immer erst zu testen, bevor sie in der /etc/sysconfig/iptables-Datei abgespeichert wird. Sie können die iptables-Regeln aber auch von einer Datei eines anderen Systems in diese Datei kopieren, wodurch sie in kurzer Zeit ganze Gruppen von iptables-Regeln an verschiedene Rechner verteilen können.
[root@myServer ~]# iptables-save > <filename> wobei <filename> ein benutzerdefinierter Name für Ihr Regelset ist.Wichtig
/etc/sysconfig/iptables-Datei an andere Rechner verteilen, müssen Sie /sbin/service iptables restart ausführen, damit die neuen Regeln wirksam werden.
Anmerkung
iptables-Befehl (/sbin/iptables), der dazu verwendet wird, die Tabellen und Ketten zu handhaben, die die iptables-Funktionalität darstellen, und dem iptables-Dienst (/sbin/iptables service), der zum Aktivieren und Deaktivieren des iptables-Dienstes selbst verwendet wird.
2.6.4. IPTables Kontrollskripte
iptables:
- Firewall-Konfigurationstool (
system-config-selinux) — Eine grafische Benutzeroberfläche zum Erstellen, Aktivieren und Speichern von einfachen Firewall-Regeln. Weitere Informationen über die Verwendung dieses Tools finden Sie unter Abschnitt 2.5.2, »Grundlegende Firewall-Konfiguration«. /sbin/service iptables <option>— Wird verwendet, um verschiedene Funktionen voniptableszu handhaben, unter Verwendung des init-Skripts von IPTables. Die folgenden Optionen stehen zur Verfügung:start— Ist eine Firewall konfiguriert (d. h./etc/sysconfig/iptablesist vorhanden), werden alle laufendeniptableskomplett beendet und dann mit dem Befehl/sbin/iptables-restoregestartet. Diese Option funktioniert nur dann, wenn dasipchainsKernel-Modul nicht geladen ist. Um zu überprüfen, ob dieses Modul geladen ist, führen Sie als Root folgenden Befehl aus:[root@MyServer ~]# lsmod | grep ipchainsWenn dieser Befehl keine Ausgabe zurückgibt, ist das Modul nicht geladen. Falls nötig, können Sie das Modul mit dem Befehl/sbin/rmmodentfernen.stop— Falls eine Firewall ausgeführt wird, werden die Firewall-Regeln im Speicher gelöscht und alle IPTables-Module und Helfer entladen.Wenn dieIPTABLES_SAVE_ON_STOP-Direktive in der Konfigurationsdatei/etc/sysconfig/iptables-configvom Standardwert aufyesgeändert wurde, werden die augenblicklichen Regeln unter/etc/sysconfig/iptablesgespeichert und jede bestehende Regel nach/etc/sysconfig/iptables.saveverschoben.Werfen Sie einen Blick auf Abschnitt 2.6.4.1, »Konfigurationsdatei der IPTables-Kontrollskripte« für weitere Informationen zuriptables-config-Datei.restart— Falls eine Firewall ausgeführt wird, werden die Firewall-Regeln im Speicher gelöscht und die Firewall, sollte sie in/etc/sysconfig/iptableskonfiguriert sein, neu gestartet. Diese Option funktioniert nur dann, wenn dasipchainsKernel-Modul nicht geladen ist.Wenn dieIPTABLES_SAVE_ON_RESTART-Direktive der Konfigurationsdatei/etc/sysconfig/iptables-configvom Standardwert aufyesgeändert wurde, werden die augenblicklichen Regeln unter/etc/sysconfig/iptablesgespeichert und jede bestehende Regel nach/etc/sysconfig/iptables.saveverschoben.Werfen Sie einen Blick auf Abschnitt 2.6.4.1, »Konfigurationsdatei der IPTables-Kontrollskripte« für weitere Informationen zuriptables-config-Datei.status— Zeigt den Status einer Firewall an und listet alle aktiven Regeln auf.Die Standardkonfiguration für diese Option zeigt die IP-Adressen in jeder Regel an. Um Informationen über Domain- und Hostnamen anzuzeigen, bearbeiten Sie die Datei/etc/sysconfig/iptables-configund setzen den Wert vonIPTABLES_STATUS_NUMERICaufno. Werfen Sie einen Blick auf Abschnitt 2.6.4.1, »Konfigurationsdatei der IPTables-Kontrollskripte« für weitere Informationen zuriptables-config-Datei.panic— Löscht alle Firewall-Regeln. Die Richtlinie aller konfigurierten Tabellen wird aufDROPgesetzt.Diese Option kann nützlich sein, wenn ein Server im Verdacht steht, kompromittiert worden zu sein. Anstatt das System physisch vom Netzwerk zu trennen oder es herunterzufahren, können Sie mithilfe dieser Option jeglichen weiteren Netzwerkverkehr stoppen und gleichzeitig den Rechner in einem Zustand belassen, der eine Analyse oder andere forensische Untersuchungen ermöglicht.save— Speichert Firewall-Regeln mittelsiptables-savenach/etc/sysconfig/iptables. Werfen Sie einen Blick auf Abschnitt 2.6.3, »Speichern von IPTables-Regeln« für weitere Informationen.
Anmerkung
iptables durch ip6tables in den in diesem Abschnitt angegebenen /sbin/service-Befehlen. Für weitere Informationen zu IPv6 und Netfilter, werfen Sie einen Blick auf Abschnitt 2.6.5, »IPTables und IPv6«.
2.6.4.1. Konfigurationsdatei der IPTables-Kontrollskripte
iptables-init-Skripts wird durch die Konfigurationsdatei /etc/sysconfig/iptables-config gesteuert. Nachfolgend sehen Sie eine Liste der in dieser Datei enthaltenen Direktiven:
IPTABLES_MODULES— Gibt eine durch Leerzeichen getrennte Liste von zusätzlicheniptables-Modulen an, die beim Aktivieren einer Firewall geladen werden, wie z. B. Verbindungs-Tracker und NAT-Helfer.IPTABLES_MODULES_UNLOAD— Entlädt Module beim Neustarten und Stoppen. Diese Direktive akzeptiert die folgenden Werte:yes— Der Standardwert. Diese Option muss gesetzt sein, um einen richtigen Status für einen Firewall-Neustart oder -Stopp zu erhalten.no— Diese Option sollte nur dann gesetzt sein, wenn es Probleme beim Entladen der Netfilter-Module gibt.
IPTABLES_SAVE_ON_STOP— Speichert die aktuellen Firewall-Regeln unter/etc/sysconfig/iptables, wenn die Firewall gestoppt wird. Diese Direktive akzeptiert folgende Werte:yes— Speichert vorhandene Regeln unter/etc/sysconfig/iptables, wenn die Firewall gestoppt wird. Die vorherige Version wird unter/etc/sysconfig/iptables.saveabgelegt.no— Der Standardwert. Bestehende Regeln werden nicht gespeichert, wenn die Firewall gestoppt wird.
IPTABLES_SAVE_ON_RESTART— Speichert die aktuellen Firewall-Regeln, wenn die Firewall neu gestartet wird. Diese Direktive akzeptiert die folgenden Werte:yes— Speichert bestehende Regeln unter/etc/sysconfig/iptables, wenn die Firewall neu gestartet wird. Die vorherige Version wird dabei unter/etc/sysconfig/iptables.saveabgelegt.no— Der Standardwert. Bestehende Regeln werden nicht gespeichert, wenn die Firewall neu gestartet wird.
IPTABLES_SAVE_COUNTER— Speichert und stellt alle Paket- und Byte-Zähler in allen Ketten und Regeln wieder her. Diese Direktive akzeptiert die folgenden Werte:yes— Speichert die Werte der Zähler.no— Der Standardwert. Speichert die Werte der Zähler nicht.
IPTABLES_STATUS_NUMERIC— Gibt die IP-Adressen in numerischer Form aus anstelle der Domain- oder Hostnamen. Diese Direktive akzeptiert die folgenden Werte:yes— Der Standardwert. Gibt lediglich IP-Adressen in der Statusanzeige aus.no— Gibt Domain- oder Hostnamen in der Statusanzeige aus.
2.6.5. IPTables und IPv6
iptables-ipv6 installiert ist, kann der Netfilter in Red Hat Enterprise Linux das neueste IPv6-Internetprotokoll filtern. Der Befehl zur Verwaltung des IPv6-Netfilters lautet ip6tables.
iptables, mit der Ausnahme, dass die nat-Tabelle noch nicht unterstützt wird. Infolgedessen ist es noch nicht möglich, IPv6 Network-Address-Translation-Aufgaben, wie z. B. Masquerading oder Port-Forwarding, durchzuführen.
ip6tables werden in der Datei /etc/sysconfig/ip6tables gespeichert. Vorherige, durch die ip6tables-init-Skripte gespeicherte Regeln werden in der Datei /etc/sysconfig/ip6tables.save abgelegt.
ip6tables-init-Skripte werden in /etc/sysconfig/ip6tables-config gespeichert und die Namen der jeweiligen Direktiven unterscheiden sich leicht von ihren iptables-Gegenstücken.
iptables-config-Direktive IPTABLES_MODULES ist zum Beispiel IP6TABLES_MODULES in der ip6tables-config-Datei.
2.6.6. Zusätzliche Informationsquellen
iptables.
- Abschnitt 2.5, »Firewalls« — Enthält ein Kapitel über die Rolle von Firewalls innerhalb einer umfassenden Sicherheitsstrategie, sowie Strategien zum Erstellen von Firewall-Regeln.
2.6.6.1. Installierte IPTables-Dokumentation
man iptables— Enthält eine Beschreibung voniptables, sowie eine umfangreiche Liste verschiedener Ziele, Optionen und Übereinstimmungserweiterungen.
2.6.6.2. Hilfreiche IPTables-Websites
- http://www.netfilter.org/ — Die Homepage des Netfilter/iptables-Projekts. Enthält ausgewählte Informationen zu
iptablessowie ein FAQ zu spezifischen Problemen und verschiedene hilfreiche Handbücher von Rusty Russell, dem Linux-IP-Firewall-Maintainer. In diesen Anleitungen werden Themen, wie z. B. grundlegende Netzwerkkonzepte, Kernel-Paketfilterung und NAT-Konfigurationen behandelt. - http://www.linuxnewbie.org/nhf/Security/IPtables_Basics.html — Eine Einführung in die Art und Weise, wie sich Pakete durch den Linux-Kernel bewegen, sowie eine Übersicht zur Erstellung von einfachen
iptables-Befehlen.
Kapitel 3. Verschlüsselung
3.1. Ruhende Daten
3.2. Vollständige Festplattenverschlüsselung
3.3. Dateibasierte Verschlüsselung
3.4. Daten in Übertragung
3.5. Virtuelle Private Netzwerke
3.6. Secure Shell
3.7. OpenSSL PadLock Engine
Anmerkung
/etc/pki/tls/openssl.cnf und fügen Folgendes am Anfang der Datei hinzu:
openssl_conf = openssl_init
[openssl_init] engines = openssl_engines [openssl_engines] padlock = padlock_engine [padlock_engine] default_algorithms = ALL dynamic_path = /usr/lib/openssl/engines/libpadlock.so init = 1
# openssl engine -c -tt
# openssl speed aes-128-cbc
# dd if=/dev/zero count=100 bs=1M | ssh -c aes128-cbc localhost "cat >/dev/null"
3.8. LUKS-Festplattenverschlüsselung
3.8.1. LUKS-Implementierung in Red Hat Enterprise Linux
cryptsetup --help) ist aes-cbc-essiv:sha256 (ESSIV - Encrypted Salt-Sector Initialization Vector). Beachten Sie, dass das Installationsprogramm Anaconda standardmäßig den XTS-Modus (aes-xts-plain64) verwendet. Die standardmäßige Schlüsselgröße für LUKS ist 256 Bits. Die standardmäßige Schlüsselgröße für LUKS mit Anaconda (XTS-Modus) ist 512 Bits. Verfügbare Schlüssel sind:
- AES - Advanced Encryption Standard - FIPS PUB 197
- Twofish (Eine 128-Bit Blockchiffre)
- Serpent
- cast5 - RFC 2144
- cast6 - RFC 2612
3.8.2. Manuelle Verschlüsselung von Verzeichnissen
Warnung
3.8.3. Schrittweise Anleitung
- Wechseln Sie zu Runlevel 1:
telinit 1 - Hängen Sie Ihre vorhandene /home-Partition aus:
umount /home - Sollte dies fehlschlagen, verwenden Sie
fuser, um noch aktive Prozesse auf /home zu finden und zu beenden:fuser -mvk /home - Vergewissern Sie sich, dass /home nicht mehr eingehängt ist:
cat /proc/mounts | grep home - Füllen Sie Ihre Partition mit zufälligen Daten:
dd if=/dev/urandom of=/dev/VG00/LV_homeDieser Vorgang kann mehrere Stunden dauern.Wichtig
Dieser Vorgang ist von entscheidender Bedeutung für die Sicherung gegen Einbruchsversuche. Lassen Sie den Vorgang ggf. über Nacht laufen. - Initialisieren Sie Ihre Partition:
cryptsetup --verbose --verify-passphrase luksFormat /dev/VG00/LV_home - Öffnen Sie das neu verschlüsselte Gerät:
cryptsetup luksOpen /dev/VG00/LV_home home - Vergewissern Sie sich, dass das Gerät vorhanden ist:
ls -l /dev/mapper | grep home - Erstellen Sie ein Dateisystem:
mkfs.ext3 /dev/mapper/home - Hängen Sie es ein:
mount /dev/mapper/home /home - Überprüfen Sie, ob es sichtbar ist:
df -h | grep home - Fügen Sie Folgendes zur /etc/crypttab hinzu:
home /dev/VG00/LV_home none - Bearbeiten Sie Ihre /etc/fstab, entfernen Sie den alten Eintrag für /home und fügen Sie Folgendes hinzu:
/dev/mapper/home /home ext3 defaults 1 2 - Stellen Sie die standardmäßigen SELinux-Sicherheitskontexte wieder her:
/sbin/restorecon -v -R /home - Starten Sie das Sytem neu:
shutdown -r now - Der Eintrag in der /etc/crypttab-Datei weist Ihr System dazu an, beim Hochfahren zur Eingabe der
luks-Passphrase aufzufordern. - Melden Sie sich als Root an und stellen Sie Ihre gesicherten Daten wieder her.
3.8.4. Ergebnis
3.8.5. Hilfreiche Links
3.9. Verwenden von GNU Privacy Guard (GnuPG)
3.9.1. Erstellen von GPG-Schlüsseln in GNOME
System > Administration > Software hinzufügen/entfernen und warten Sie, bis die Applikation gestartet ist. Geben Sie Seahorse in das Textfeld ein und klicken Sie auf Suchen. Markieren Sie das Auswahlkästchen neben dem ''seahorse''-Paket und klicken Sie auf "Anwenden", um die Software hinzuzufügen. Sie können Seahorse auch mithilfe des Befehls su -c "yum install seahorse" über die Befehlszeile installieren.
Seahorse-Applikation startet. Wählen Sie aus dem "Datei"-Menü "Neu", dann "PGP-Schlüssel". Klicken Sie anschließend auf "Weiter". Geben Sie Ihren vollständigen Namen, Ihre E-Mail-Adresse und einen optionalen Kommentar an (z. B.: John C. Smith, jsmith@example.com, The Man). Klicken Sie auf "Erstellen". Ein Dialogfeld erscheint, dass Sie zur Eingabe eines Passworts für den Schlüssel auffordert. Wählen Sie ein sicheres, jedoch einfach zu merkendes Passwort. Klicken Sie auf "OK", und der Schlüssel wird erstellt.
Warnung
3.9.2. Erstellen von GPG-Schlüsseln in KDE
KGpg.
Warnung
3.9.3. Erstellen von GPG-Schlüsseln per Befehlszeile
gpg --gen-key
Eingabetaste, um einen Standardwert zuzuweisen, falls gewünscht. Die erste Eingabeaufforderung fordert Sie zur Auswahl auf, welche Art von Schlüssel Sie bevorzugen:
1y eingeben, bleibt der Schlüssel für ein Jahr gültig. (Sie können dieses Ablaufdatum auch noch nach Erzeugung des Schlüssels ändern, sollten Sie es sich anders überlegen.)
gpg-Programm die Signaturinformationen abfragt, erscheint die folgende Eingabeaufforderung: Ist dies richtig (j/N)? Tippen Sie j, um den Vorgang abzuschließen.
gpg-Programm fordert Sie zur zweimaligen Eingabe des Passworts auf, um Tippfehler auszuschließen.
gpg-Programm generiert nun zufällige Daten, um Ihren Schlüssel so eindeutig wie möglich zu machen. Bewegen Sie während dieses Vorgangs Ihre Maus, tippen wahllos auf der Tastatur oder führen Sie andere Aufgaben auf dem System aus, um diesen Vorgang zu beschleunigen. Nachdem dieser Schritt abgeschlossen wurde, sind Ihre Schlüssel fertig und einsatzbereit:
pub 1024D/1B2AFA1C 2005-03-31 John Q. Doe <jqdoe@example.com> Key fingerprint = 117C FE83 22EA B843 3E86 6486 4320 545E 1B2A FA1C sub 1024g/CEA4B22E 2005-03-31 [expires: 2006-03-31]
gpg --fingerprint jqdoe@example.com
Warnung
3.9.4. Informationen zur asymmetrischen Verschlüsselung
Kapitel 4. Allgemeine Prinzipien der Informationssicherheit
- Verschlüsseln Sie alle Daten, die über das Netzwerk übertragen werden, um Man-in-the-Middle-Angriffe und das Abgreifen von Daten zu verhindern. Es ist insbesondere wichtig, sämtliche Daten zur Authentifikation wie z. B. Passwörter zu verschlüsseln.
- Installieren Sie nur die nötigste Software und führen Sie nur die nötigsten Dienste aus.
- Verwenden Sie Software und Tools zur Verbesserung der Sicherheit, wie z. B. Security-Enhanced Linux (SELinux) für Mandatory Access Control (MAC), Netfilter IPTables zur Paketfilterung (Firewall) und den GNU Privacy Guard (GnuPG) zur Verschlüsselung von Dateien.
- Falls möglich, führen Sie jeden Netzwerkdienst auf einem separaten System aus, um das Risiko zu verringern, dass ein kompromittierter Dienst zur Schädigung weiterer Dienste eingesetzt wird.
- Pflegen Sie die Benutzerkonten: Setzen Sie eine Richtlinie für sichere Passwörter durch und entfernen Sie ungenutzte Benutzerkonten.
- Sehen Sie regelmäßig die System- und Applikationsprotokolle durch. Standardmäßig werden Systemprotokolle rund um die Sicherheit in
/var/log/secureund/var/log/audit/audit.loggeschrieben. Beachten Sie auch, dass der Einsatz eines dedizierten Protokollservers es Angreifern erschwert, lokale Protokolle einfach zu ändern, um ihre Spuren zu verwischen. - Melden Sie sich niemals als Root-Benutzer an, es sei denn, es ist absolut notwendig. Administratoren wird empfohlen, möglichst
sudozur Ausführung von Befehlen als Root zu nutzen. Benutzer, diesudonutzen dürfen, können in der/etc/sudoers-Datei festgelegt werden. Verwenden Sie dasvisudo-Hilfsprogramm, um/etc/sudoerszu bearbeiten.
4.1. Tipps, Handbücher und Werkzeuge
Anmerkung
Kapitel 5. Sichere Installation
5.1. Festplattenpartitionen
5.2. Verwenden der LUKS-Partitionsverschlüsselung
Kapitel 6. Software-Wartung
6.1. Installieren minimaler Software
6.2. Planen und Konfigurieren von Sicherheitsaktualisierungen
6.3. Anpassen der automatischen Aktualisierungen
System -> Einstellungen -> Software-Aktualisierungen. In KDE finden Sie dies unter: Anwendungen -> Einstellungen -> Software-Aktualisierungen.
6.4. Installieren signierter Pakete von bekannten Repositorys
Kapitel 7. Regierungsstandards und -reglementierungen
7.1. Einführung
7.2. Federal Information Processing Standard (FIPS)
- Level 1 - Sicherheits-Level 1 bietet das geringste Level an Sicherheit. Nur einfache Sicherheitsanforderungen werden für ein kryptografisches Modul spezifiziert (z. B. muss mindestens ein bestätigter Algorithmus oder eine bestätigte Sicherheitsfunktion genutzt werden). Über diese einfachen Anforderungen hinaus sind in einem kryptografischen Modul des Sicherheits-Level 1 keine physischen Sicherheitsverfahren für Produktionskomponenten erforderlich. Ein Beispiel für ein kryptografisches Modul auf Sicherheits-Level 1 ist ein PC-Encryption-Board.
- Level 2 - Sicherheits-Level 2 verbessert die physischen Sicherheitsmaßnahmen eines kryptografischen Moduls des Sicherheits-Level 1 durch zusätzlich notwendige Originalitätssicherung mithilfe von Siegeln oder Beschichtungen oder mithilfe von Sicherheitsschlössern oder Abdeckungen für das Modul. Beschichtungen oder Siegel zur Originalitätssicherung werden auf einem kryptografischen Modul platziert, so dass die Beschichtung oder das Siegel gebrochen werden müssen, um physischen Zugriff auf die kryptografischen Schlüssel in Klartext und auf kritische Sicherheitsparameter (CSPs) innerhalb des Moduls zu erlangen. Sicherheitsschlösser oder Siegel zur Originalitätssicherung werden auf Abdeckungen oder Öffnungen platziert, um gegen unbefugten physischen Zugriff zu schützen.
- Level 3 - Zusätzlich zur den Sicherheitsmaßnahmen zur Originalitätssicherung für Sicherheits-Level 2 versucht das Sicherheits-Level 3 einen Angreifer daran zu hindern, Zugriff auf die kritischen Sicherheitsparameter innerhalb des kryptografischen Moduls zu erlangen. Die für Sicherheits-Level 3 nötigen physischen Sicherheitsmechanismen sollen mit hoher Wahrscheinlichkeit Versuche, auf das kryptografische Modul zuzugreifen, es zu verwenden oder zu verändern, erkennen und darauf reagieren. Zu den physischen Sicherheitsmechanismen gehören der Einsatz von stabilen Gehäusen sowie Schaltkreise zur Erkennung von Einbrüchen, die sämtliche kritische Sicherheitsparameter mit Nullen überschreiben, wenn die Abdeckungen oder Öffnungen des kryptografischen Moduls geöffnet werden.
- Level 4 - Das Sicherheits-Level 4 bietet das höchste Maß an Sicherheit, das in diesem Standard definiert ist. Bei diesem Sicherheits-Level bieten die physischen Sicherheitsmechanismen einen vollständigen Schutzschild um das kryptografische Modul, um alle unerlaubten physischen Zugriffe darauf zu erkennen und entsprechend zu reagieren. Ein wie auch immer geartetes Eindringen in das Gehäuse des kryptografischen Moduls wird mit hoher Wahrscheinlichkeit entdeckt, woraufhin sofort sämtliche kritische Sicherheitsparameter in Klartext mit Nullen überschrieben werden. Kryptografische Module des Sicherheits-Level 4 sind nützlich für den Einsatz in Umgebungen, die anderweitig nicht physisch geschützt sind.
7.3. National Industrial Security Program Operating Manual (NISPOM)
7.4. Payment Card Industry Data Security Standard (PCI DSS)
7.5. Handbuch zur technischen Sicherheitsimplementierung
Kapitel 8. Weitere Informationsquellen
Bücher
- SELinux by Example
- Mayer, MacMillan, and CaplanPrentice Hall, 2007
Tutorials und Hilfen
- Verstehen und Anpassen der Apache HTTP SELinux-Richtlinie
- Tutorials und Vorträge von Russell Coker
- Allgemeines HOWTO zum Schreiben von SELinux-Richtlinien
- Red Hat Wissensdatenbank
Allgemeine Informationen
- NSA SELinux Hauptwebsite
- NSA SELinux FAQ
- Fedora SELinux FAQ
- SELinux NSA's Open Source Security Enhanced Linux
Technologie
- Ein Überblick über Objektklassen und Berechtigungen
- Integrieren flexibler Unterstützung für Sicherheitsrichtlinien in das Linux-Betriebssystem (eine Geschichte der Flask-Implementierung in Linux)
- Implementieren von SELinux als Linux-Sicherheitsmodul
- Eine Sicherheitsrichtlinien-Konfiguration für Security-Enhanced Linux
Community
- Fedora SELinux-Benutzerhandbuch
- Fedora SELinux-Handbuch zur Verwaltung eingeschränkter Dienste
- SELinux Community-Seite
- IRC
- irc.freenode.net, #selinux, #fedora-selinux, #security
Geschichte
- Geschichtliches zu Flask
- Umfassende Hintergrundinformationen zu Fluke
Anhang A. Verschlüsselungsstandards
A.1. Symmetrische Verschlüsselung
A.1.1. Advanced Encryption Standard - AES
A.1.1.1. Anwendungsfälle für AES
A.1.1.2. Geschichte von AES
A.1.2. Data Encryption Standard - DES
A.1.2.1. Anwendungsfälle für DES
A.1.2.2. Geschichte von DES
A.2. Asymmetrische Verschlüsselung
A.2.1. Diffie-Hellman
A.2.1.1. Geschichte von Diffie-Hellman
A.2.2. RSA
A.2.3. DSA
A.2.4. SSL/TLS
A.2.5. Cramer-Shoup Kryptosystem
A.2.6. ElGamal-Verschlüsselung
Anhang B. Versionsgeschichte
| Versionsgeschichte | |||
|---|---|---|---|
| Version 1.5-2.402 | Fri Oct 25 2013 | ||
| |||
| Version 1.5-2 | 2012-07-18 | ||
| |||
| Version 1.5-0 | Apr 19 2010 | ||
| |||
| Version 1.4.1-0 | Mar 5 2010 | ||
| |||
| Version 1.3-0 | Feb 19 2010 | ||
| |||